












A problem shared is a problem halved? Not at all, because the unique launch marathon starts today, where NVIDIA and AMD want to steal each other’s thunder! And if all that wasn’t enough, only the GeForce RTX 4060 Ti as Founders Edition or MSRP card without OC is available today. And when AMD unpacks the Radeon RX 7600 tomorrow, the OC cards of the GeForce RTX 4060 Ti are supposed to interfere with the launch of the Radeon RX 7600, whose board partner cards will only be launched the day after tomorrow.
However, three days with overlapping releases are nothing to please customers and testers alike. On the contrary, because then the information and stimulus overload is perfect. That with the sprawling work on such articles anyway. That’s exactly why I’ll present the GeForce RTX 4060 Ti as MSRP card and OC model in equal measure today, because NVIDIA has thankfully left this loophole open for us. Since the performance increase of the OC cards was already predictable and, above all, uniformly measurable with the RTX 4070, I’ll save myself the superfluous two-parter tomorrow and already pack everything into this one article today. The rest can be transferred and the AIC cards can be shown as a hands-on. I’ll do the individual tests after Computex.

And what does the customer do? For an MSRP of 439 Euros, NVIDIA lets the lower mid-range off the leash today and hopes to win new customers and annoy AMD, which currently cannot offer any new cards in this segment. In the end, I can already spoil this by saying that the performance is more like that of a GeForce RTX 3070 FE 8 GB in Full HD. I will price that at the end, but I still want to mention it first. The older GeForce RTX 3060 Ti will be outclassed in any case, not only at the socket. Of course, today’s test will show how this looks exactly and where AMD’s older 6000 cards can still compete.

I compared the NVIDIA GeForce RTX 4060 Ti FE with the Palit RTX 4060 Ti Dual in terms of performance: The difference is again only at or even below one percent, which passes for measurement inaccuracy and chip lottery, with the Palit card having the slightly worse cooler than the FE. Therefore, I’ll do something else for performance today than compare all MSRP cards correctly in terms of accounting. Equally long bars don’t interest anyone anyway. I will present the single cards later after the Computex step by step in detail, because there are quite differences in the technical implementation, the cooler and the optics. But everything in its time. So there will be several single reviews, don’t worry. Just for today, it was all just too much.
Instead, I’m testing the NVIDIA GeForce RTX 4060 Ti FE 8GB out of the box today, where it represents the entire 160 watt class of so-called MSRP cards, because the performance is identical. And, of course, there is the run with the 175 watts as the maximum power limit as a topping, where I increased the clock by another 210 MHz. It’s not my fault that this is in the range of OC cards that will be launched tomorrow. The card can do it and that’s why I show it. And without spoiling anything: I never needed more than 165 watts, not even at the clock limit. Because at some point the voltage always limits, no matter how high you set the power limit.
Important preface
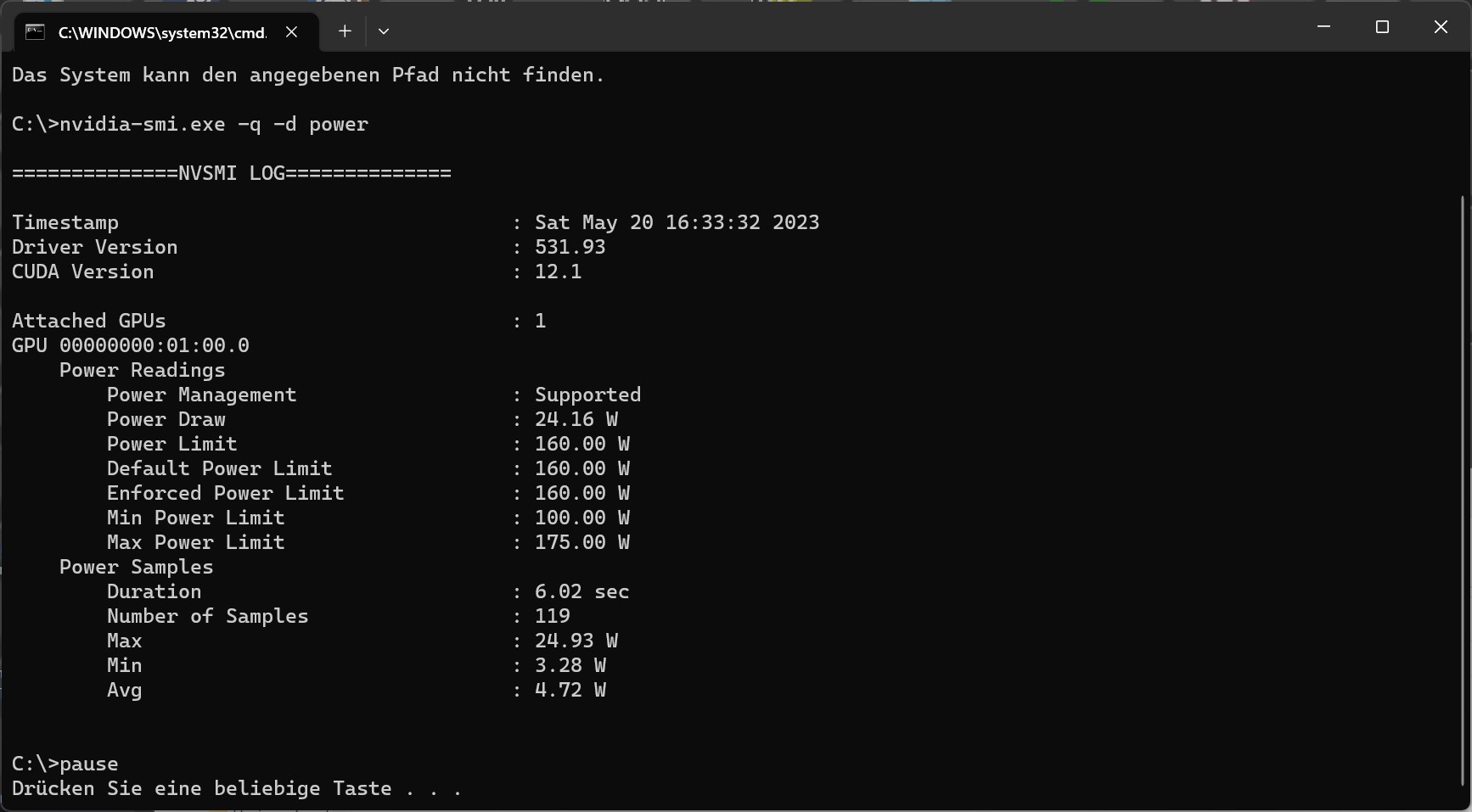
Of course, as usual, there are many benchmarks, the comprehensive teardown, a very elaborate board and cooler analysis with some reverse engineering, as well as the analysis of power consumption and load peaks including a suitable power supply recommendation. Since I know that many colleagues also repeat all the technical details including theory, which have already been presented in various tidbits, I’ll spare myself that today and only briefly refer to the already known data. This also includes NVIDIA’s explanation about the cache and why this is supposed to relieve the memory expansion. But you want to see real numbers today and not PR fireworks. Of course, the specs will follow in a moment. By the way, our chip on the package with the number 266 on the FE is from calendar week 45 in 2022.

The AD 106 and the new Ada architecture
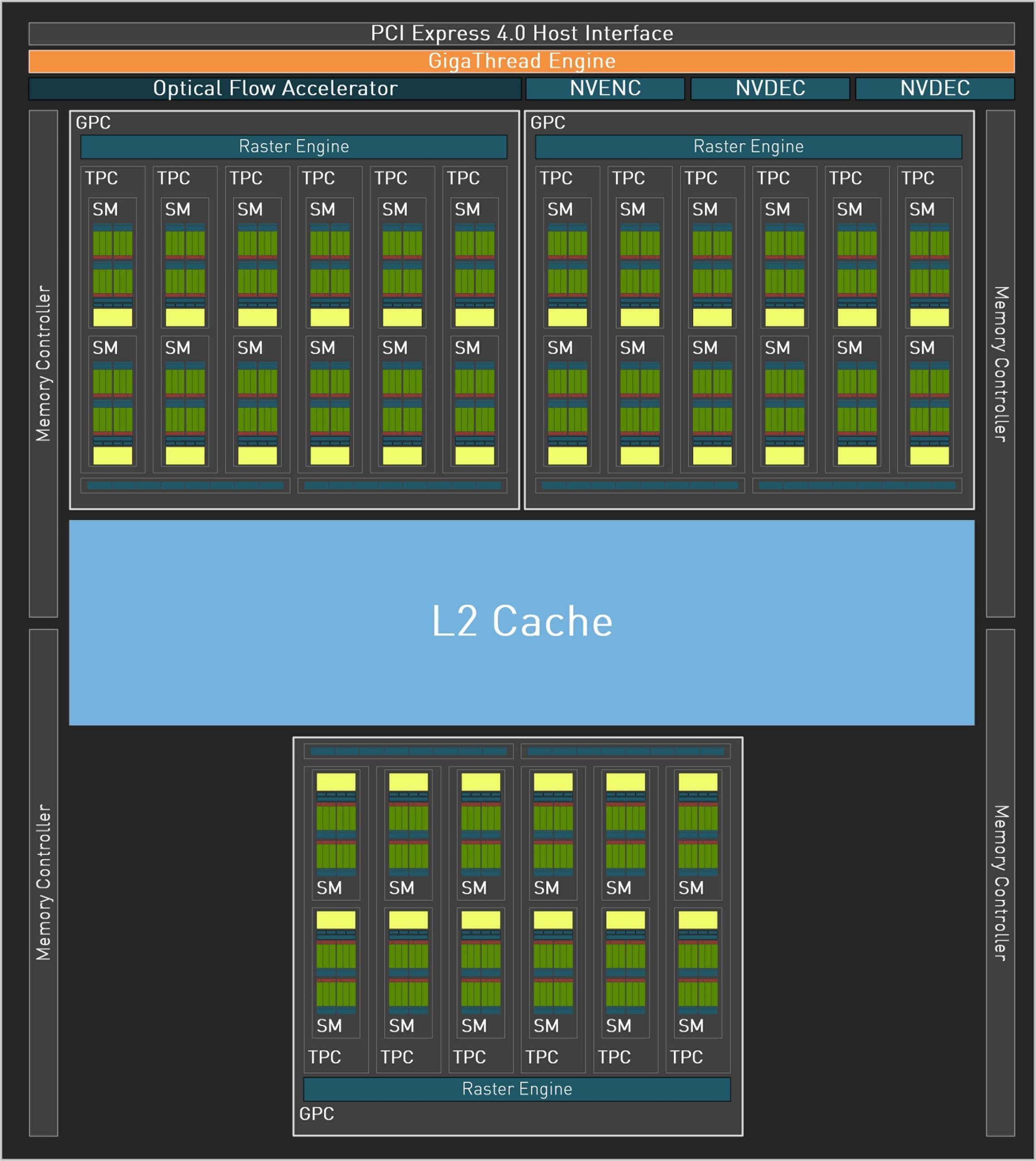
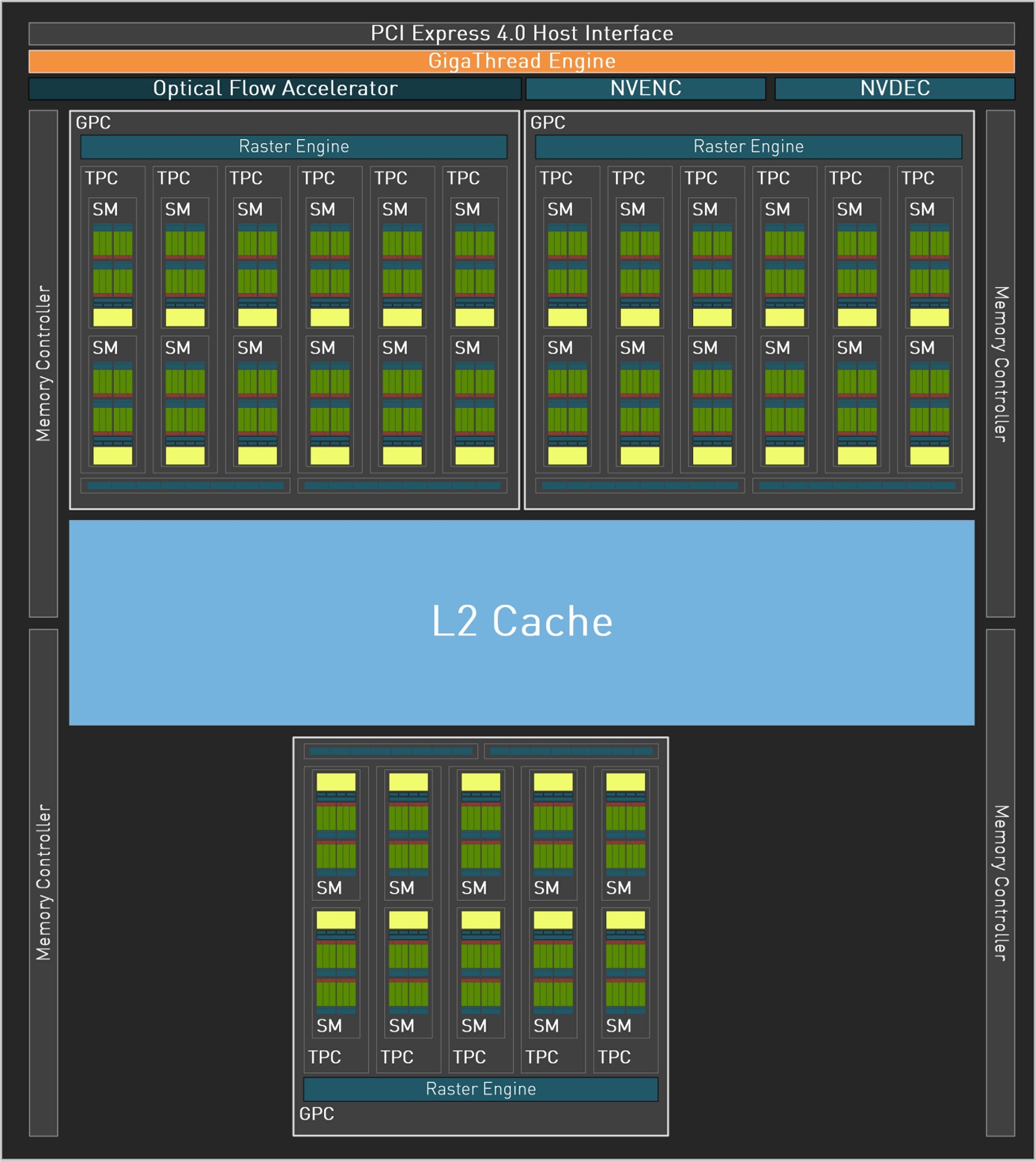
The 190 mm² chip of the NVIDIA GeForce RTX 4070 is also manufactured in the TSMC 4N process and has 22.9 billion transistors. The AD106-351 still has three Graphic Processing Clusters (GPC) and 34 new Streaming Multiprocessors (SM) with 4352 CUDA cores, whose performance and energy efficiency has increased significantly compared to Ampere. Add to that 136 4th generation Tensor cores and Optical Flow, enabling transformative AI technologies including NVIDIA DLSS and the new frame rate multiplier NVIDIA DLSS 3.
The 34 3rd generation RT cores provide up to 2x ray tracing performance, Shader Execution Reordering (SER) also improves ray tracing operations by 2x. In addition, there are a total of 17 Texture Processing Clusters (TPC), 136 Texture Units (TU) and 48 ROPs. The L2 cache is 32768 KB in total and the card, like the GeForce RTX 4070 Ti, uses the familiar 8 GB GDDR6 with MHz clock on a rather narrow 128-bit interface, which corresponds to a data rate of 18 Gbps and a bandwidth of 288 GB/s. The AD106-351 of the GeForce RTX 4060 Ti offers only one NVDEC (decoder) instead of two and a single NVENC (encoder) in total. The AV1 encoder is supposed to work up to 40% more efficiently than H.264.
 |
 |
The RTX 4060 Ti offers up to 22 teraflops of computing power with 32 bits of single precision domain (FP32) accuracy. Another important aspect of the RTX 4060 Ti is the power consumption. With a board power of 160 W (16 GB variant 165 watts) and an average power consumption of about 140 W when gaming, this graphics card is energy-efficient yet powerful.
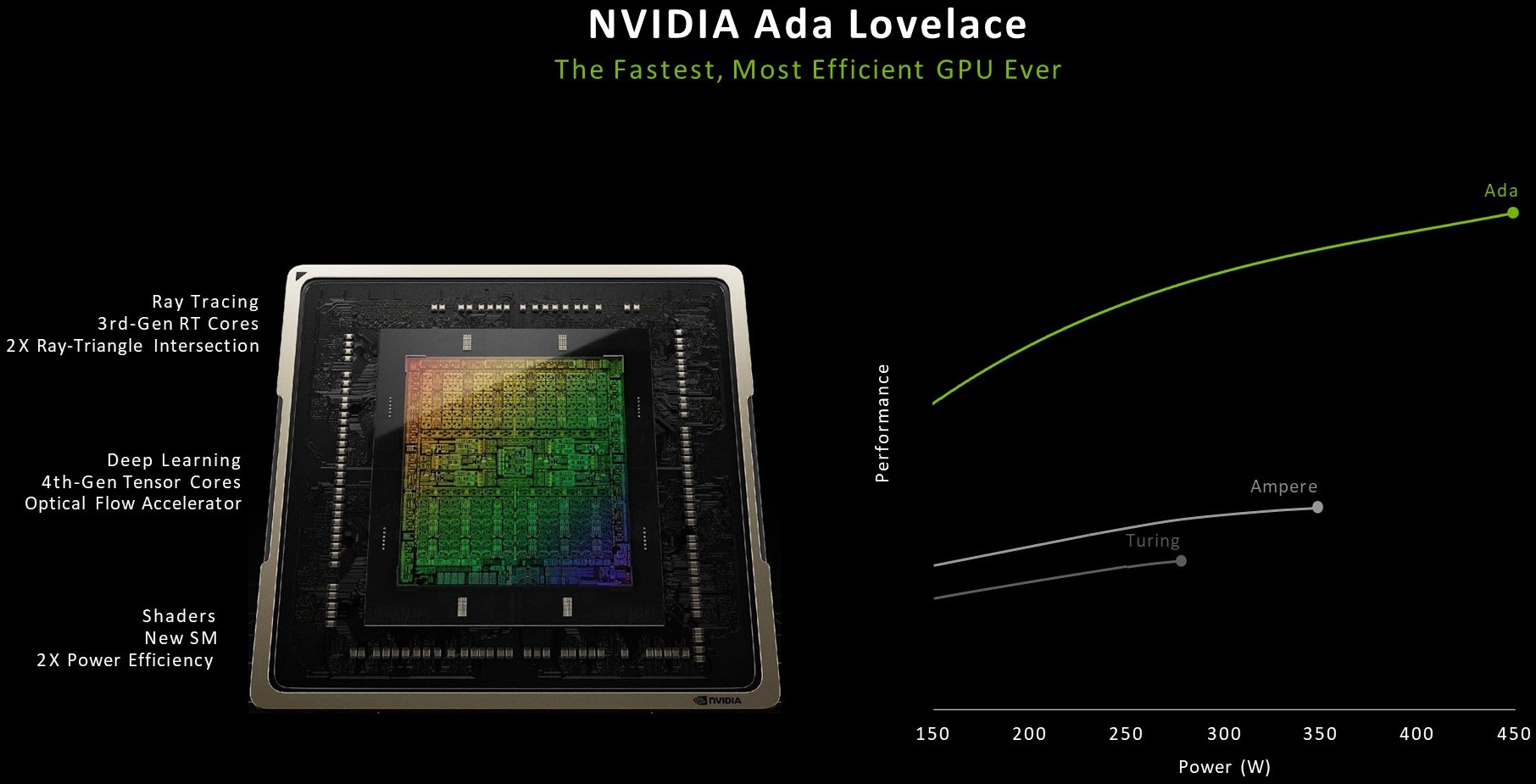
The already mentioned 18 Gbps GDDR6 128-bit memory seems a bit sparse when you consider the bandwidths of 488 GB/s or 608 GB/s of the older GeForce RTX 3060 Ti. However, the significantly expanded L2 cache in Ada Lovelace compared to Ampere should be taken into account here: While the GeForce RTX 3060 Ti still has 4 MB of L2 cache, the RTX 4060 Ti has a 32 MB L2 cache. This reduces the data traffic over the memory bus and thus enables the most efficient combination of performance and energy efficiency for gaming in 1080p resolution.
As you can see in the picture below, all calculations take place in the cores. These must therefore be able to access data quickly and efficiently to meet the demands of modern games. This is where the GPU ‘s L1 data cache comes into play. Each streaming multiprocessor (SM) has an extremely fast L1 data cache right next to its processing cores, making the L1 the first memory area the GPU looks to for information. Due to the close proximity to the core, the L1 cache cannot be particularly large, however, and it turns out accordingly with 4352 KB.
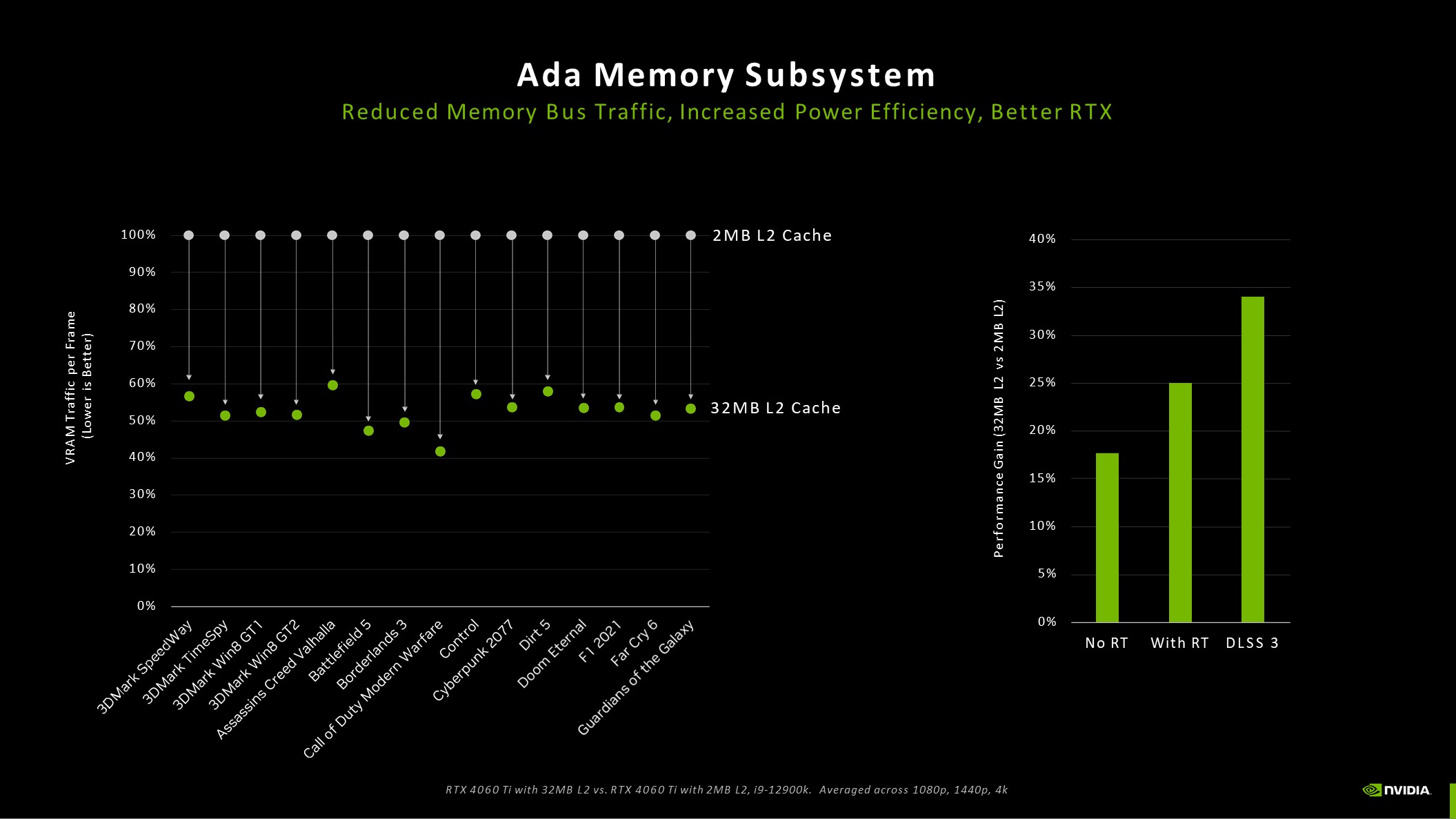
Compared to a 128-bit Ampere GPU, Ada’s L2 cache architecture thus offers a 16-fold capacity increase. In addition, the bandwidth of the L2 cache in the Ada GPUs has been significantly increased compared to previous GPUs. This enables the fastest possible data transfer between the cores and the L2 cache. Ada’s larger L2 cache results in significantly more cache hits in the L2 area while reducing traffic over the memory bus. We will see whether this works in the end in a moment.
The card still relies on a PCIe Gen. 4 interface and only at the external power connection with the 12VHPWR connector (12+4 pin) on an element of the PCIe Gen. 5 specification. The TGP is 160 (175) watts and can also be raised further, depending on the board partner (which is rather pointless, because the voltage limits at some point anyway).

- 1 - Introduction, technical data and technology
- 2 - The GeForce RTX 4060 Ti FE in detail
- 3 - Test System in the igor'sLAB MIFCOM-PC
- 4 - Teardown: PCB, components and cooler
- 5 - Gaming performance FHD (1920 x 1080)
- 6 - Gaming performance WQHD (2560 x 1440)
- 7 - Gaming performance DLSS vs. DLSS3 vs. FSR
- 8 - Latencies and DLSS 3.0
- 9 - Details: Power consumption and load balancing
- 10 - Load peaks, capping and PSU recommendation
- 11 - Temperatures, clock rate and thermal imaging
- 12 - Fan curves, noise level and audio samples
- 13 - Summary and conclusion

















418 Antworten
Kommentar
Lade neue Kommentare
Urgestein
Moderator
1
Urgestein
1
Urgestein
Mitglied
Urgestein
Veteran
1
Veteran
Veteran
Neuling
Mitglied
Mitglied
Urgestein
Mitglied
1
1
Alle Kommentare lesen unter igor´sLAB Community →