













Let’s now start with the performance tests, starting with the synthetic benchmarks, which are all run 3 times each, with the best result being used. In the case of full LinpackXtreme, a run with 5 loops and the average result output from this is used in each case. The AIDA64 Cache and Memory Benchmark in version 6.60.5900 is well suited as a theoretical indicator for the bandwidth and latency of a configuration.
In the AIDA64 tests for Copy, Read and Write, the clock rate is of course the main factor, since it is primarily responsible for the data throughput. But the timings are not to be neglected either, as you can see well in the difference between the Kingston Fury Beast and the Teamgroup VULCAN modules. At least on paper, these should in theory be identical.
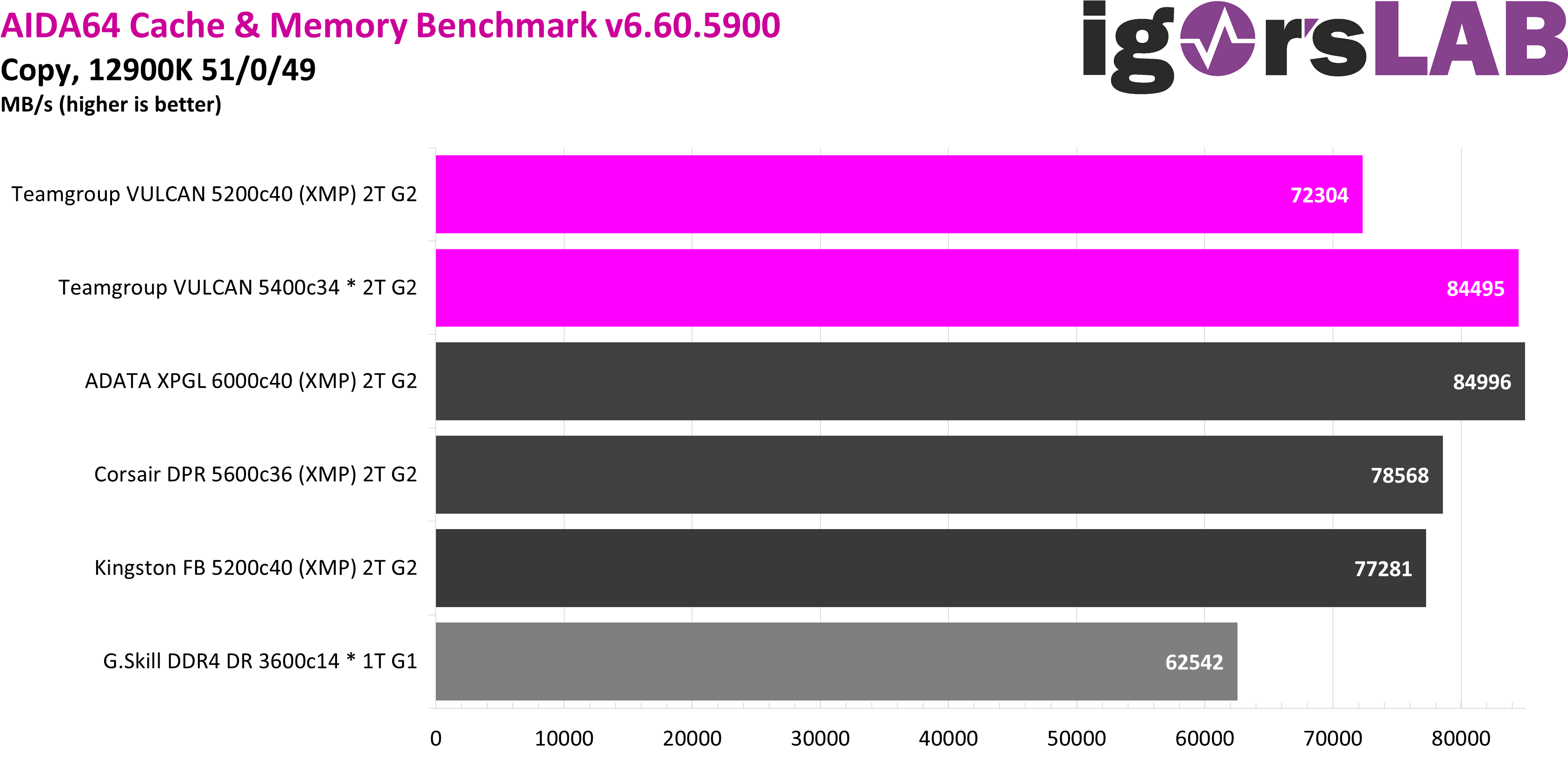
In return, the ADATA XPG kit with 6000 Mbps can almost be caught up and the Corsair Dominator kit with 5600 Mbps can be overtaken, both in XMP, by manually optimizing the timings in DDR5-5400.

In the write test, the manually adjusted VULCAN modules can even come close to the top with almost 85000 MB/s. In the XMP, the kit is again almost as fast as the Kingston kit with the same ICs.
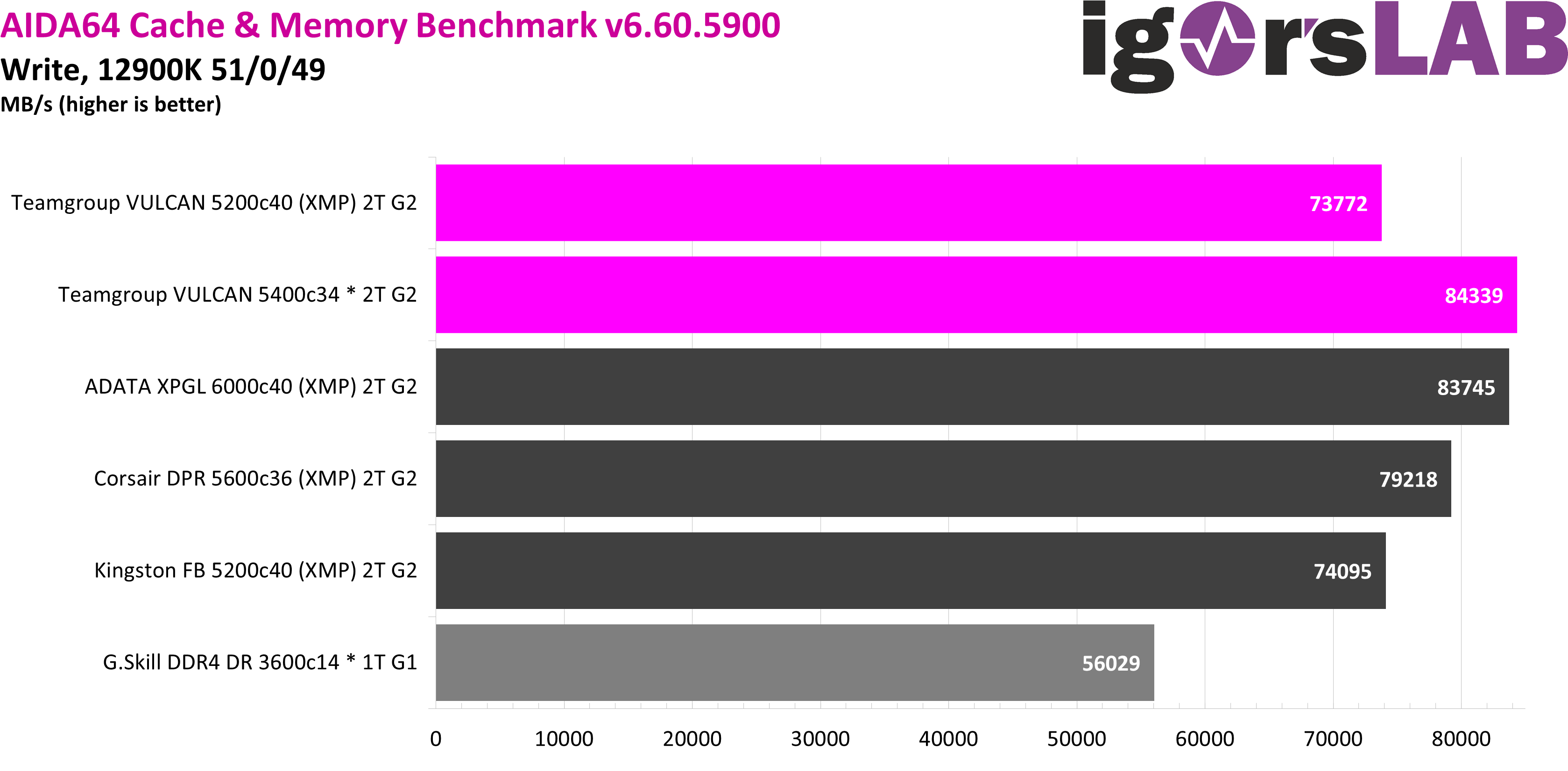
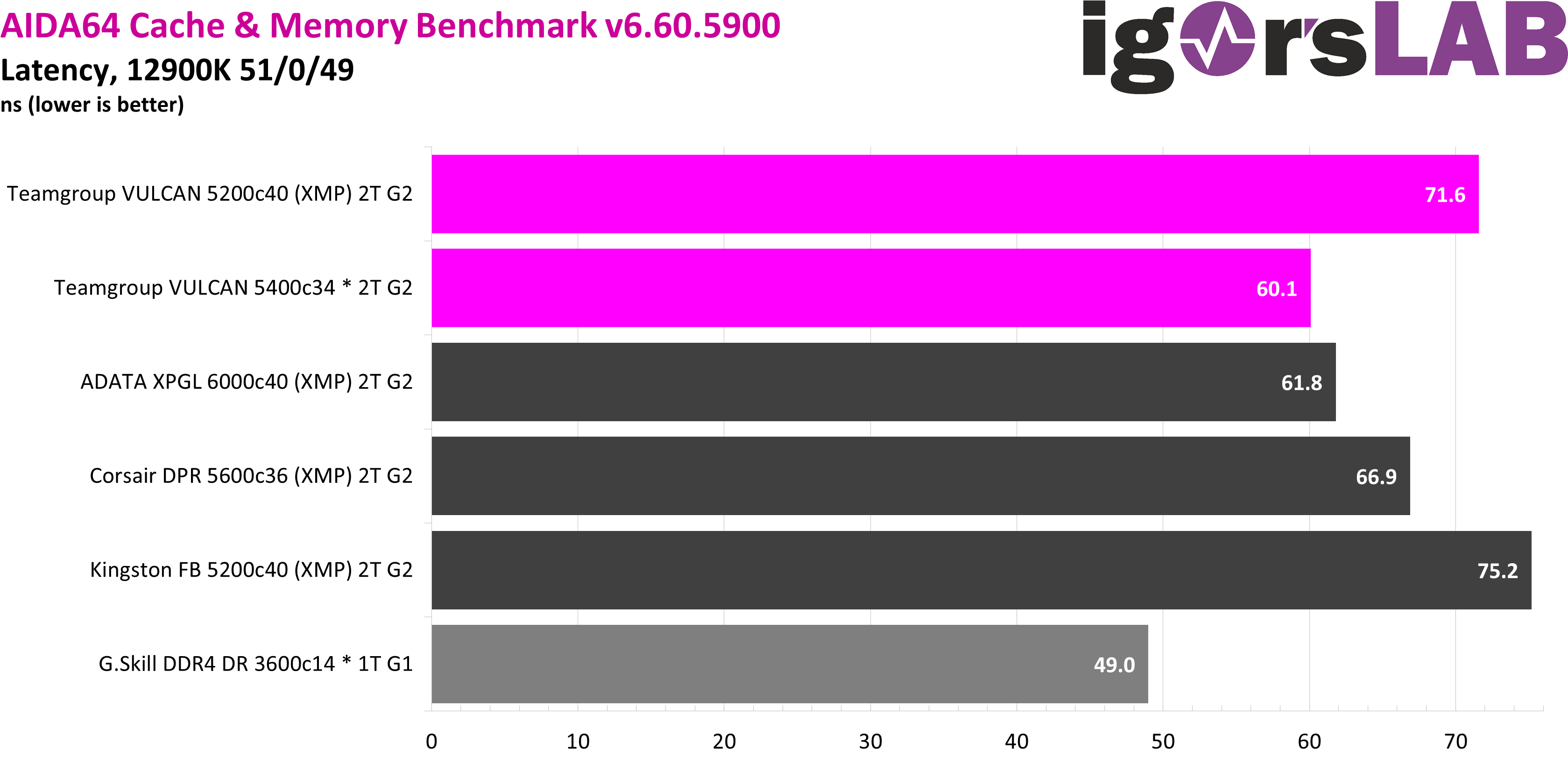
In the latency test, the two kits are in the last two places with 5200 CL40, as you would actually expect from such sluggish DDR5 on virtual paper. However, the first place among the DDR5 configurations can immediately be achieved by manually optimizing the timings, about 1.5 ns in front of the ADATA kit with an 800 Mbps clock advantage. Only the manually optimized DDR4 config is even faster.
In LinpackXtreme as a compute benchmark, the effects on the overall result are quite low, but these are equally made up of latency and bandwidth. With the manual optimization, the VULCAN modules still manage around 616 GFlops, which puts them in second place behind the significantly faster clocking ADATA modules.

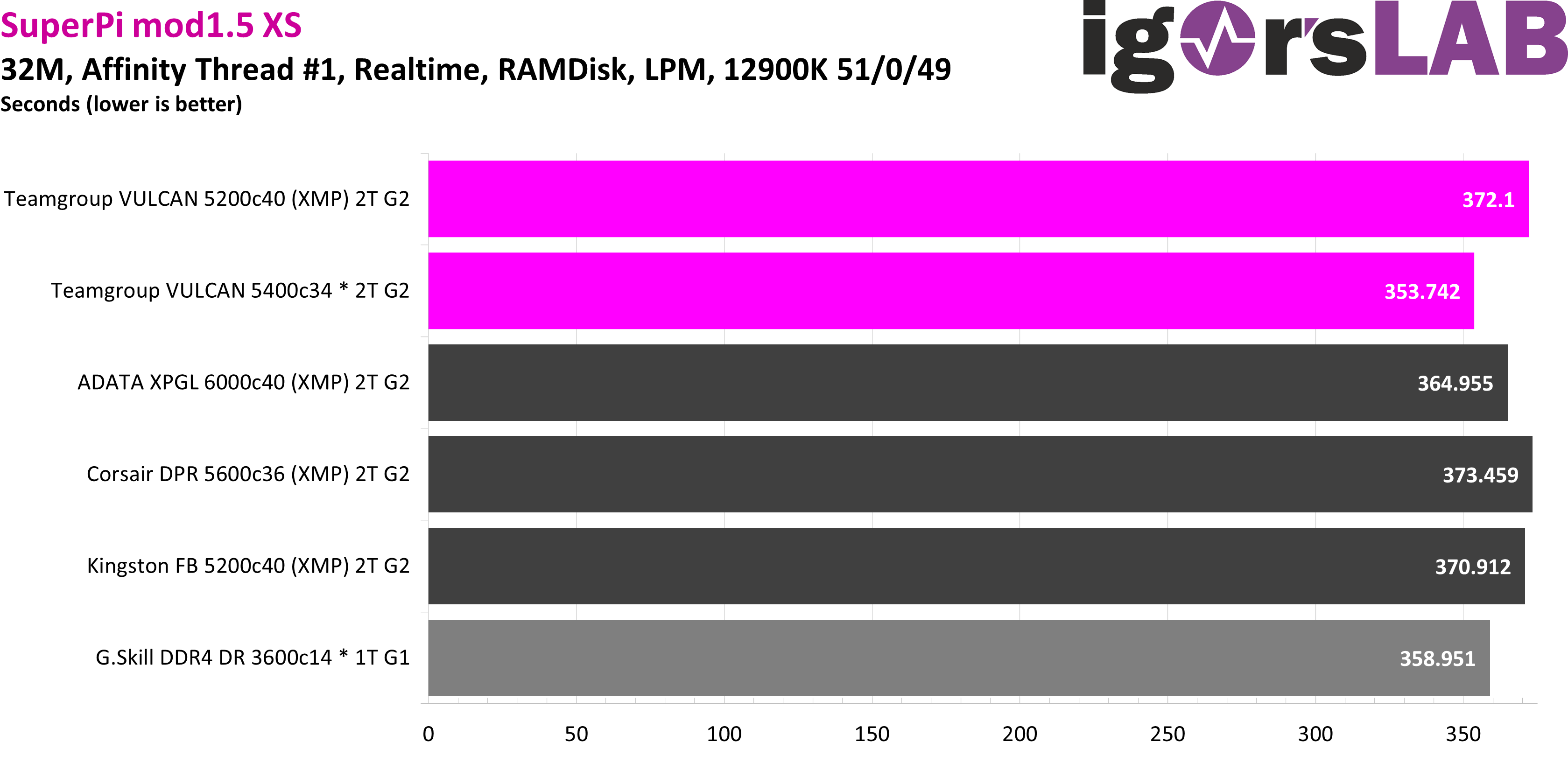
Of course, latency is what primarily counts in the SuperPi 32M, which is why the two configurations with manually set timings are clearly ahead of the others. After all, almost 20 seconds and thus 5% of the total time can be gained from the modules by overclocking. This is not groundbreaking, but nothing to sneeze at either.
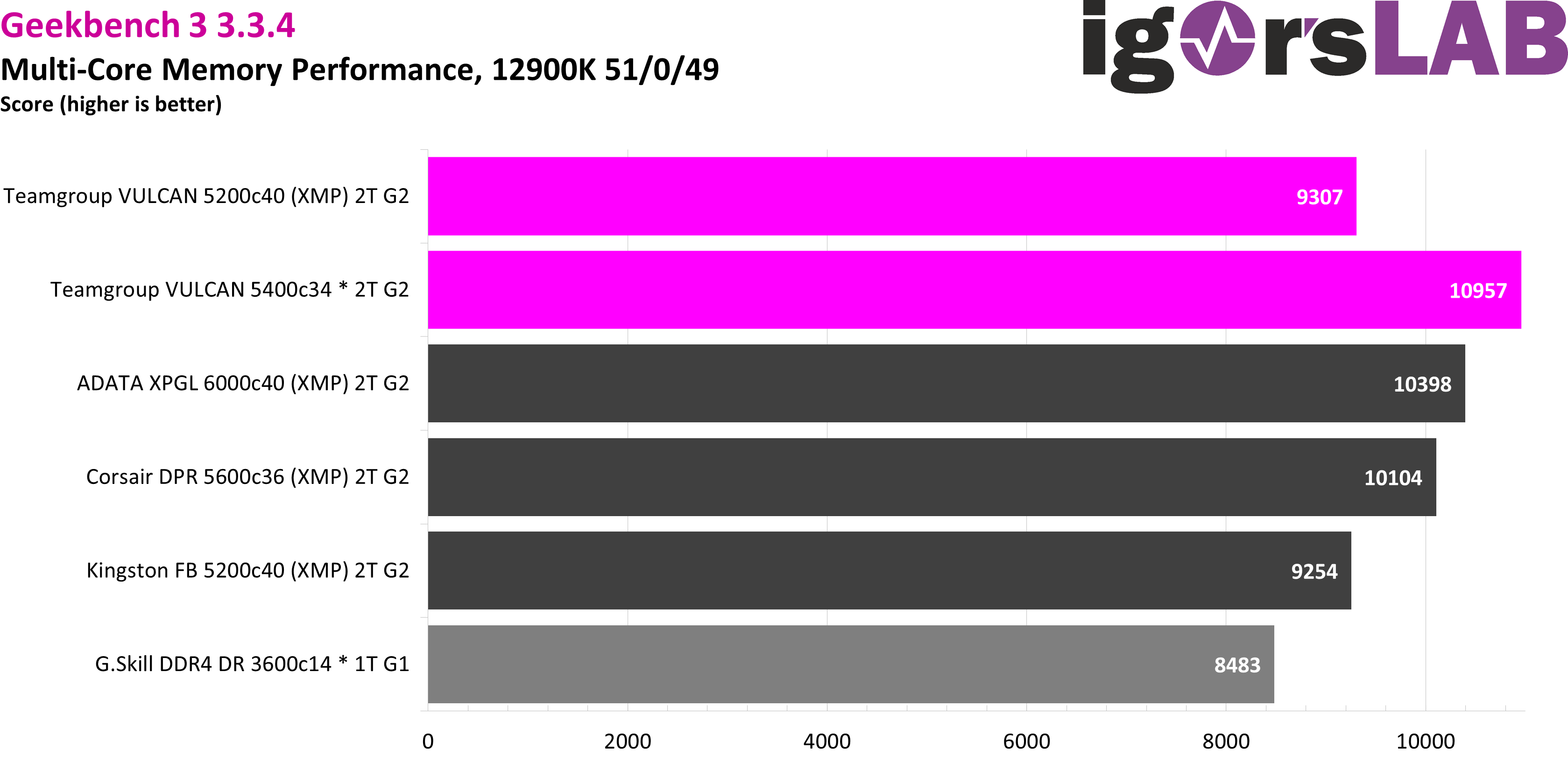
Finally, as always, there is the Geekbench 3 multi-core memory score. Here, clock rate and latency are almost equally important, with multiple sub-tests giving a good indicator of performance in a variety of use cases. DDR5 beats DDR4 here because of the clock rate alone, but not really in the same proportion because of the higher latency. Here, manual optimization really pays off, with almost 11000 points and 18% gain relative to the XMP.
















10 Antworten
Kommentar
Lade neue Kommentare
Urgestein
Urgestein
Veteran
Veteran
Veteran
Urgestein
Veteran
Urgestein
Veteran
Neuling
Alle Kommentare lesen unter igor´sLAB Community →