













Blender with different workloads
Blender is a powerful open source software for 3D graphics, animation, rendering, post-production, interactive creation and playback. It allows users to create, edit and render 3D models and animations. In addition to these 3D features, Blender also includes tools for video editing, sculpting, UV mapping, texturing, rigging, particle systems, physics and fluid simulations, and game development. Because of its extensive feature set and because it’s free, Blender is used by both amateurs and professionals throughout the media and entertainment industries. But I need to write something about CUDA, OptiX and HIP in advance to better frame the comparisons. That’s because CUDA, OptiX, and HIP are technologies developed specifically for the parallel and high-performance computing (HPC) space. Each of these technologies has its own advantages, target applications and underlying technologies.
CUDA (Compute Unified Device Architecture) is developed and supported by NVIDIA. It is a parallel computing platform and programming interface that gives developers direct access to the NVIDIA GPU virtual machine. Applications written with CUDA can take advantage of the massive parallel computing power of modern GPUs to accelerate performance-intensive applications.
OptiX is also from NVIDIA and is a ray tracing engine designed for creating images by tracking rays. It is widely used for visual applications such as rendering, scientific simulation, and gaming. OptiX beget specialized functions for ray tracing and allows ray tracing to be combined with traditional raster methods in real-time graphics applications.
HIP (Heterogeneous-compute Interface for Portability) was initiated and developed by AMD. Both NVIDIA GPUs (via a compatibility layer) and AMD GPUs can be addressed, but HIP in Blender is AMD-exclusive. HIP allows developers to write portable GPU code that can run on both NVIDIA and AMD GPUs. It was designed to provide an alternative to CUDA for those who need cross-platform portability. This is because HIP code can be converted to CUDA, making it easier for developers who have already written in CUDA to port their applications to AMD GPUs.
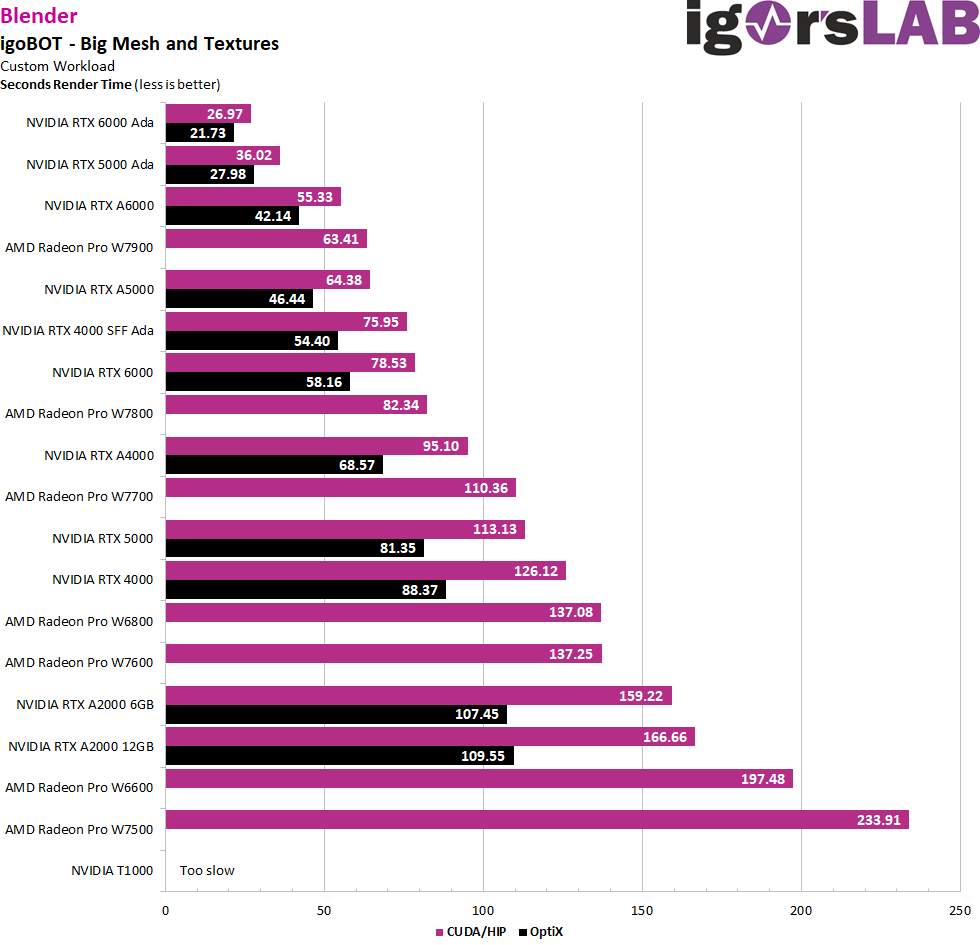
The first model is my old familiar igoBOT, which you know from YouTube videos and various animations. It is quite a complex mesh, but the scene is rather simple and also the textures are kept simple. The project doesn’t use special filters either, so you can measure the maps as pure number crunchers here. But even something like that has its charm.

The NVIDIA cards use both CUDA and OptiX, while the AMD cards use HIP. You can see that AMD has made a huge performance leap by switching from OpenCL to HIP! However, OptiX is still unchallengeably ahead. But they should already have more than caught up with CUDA.
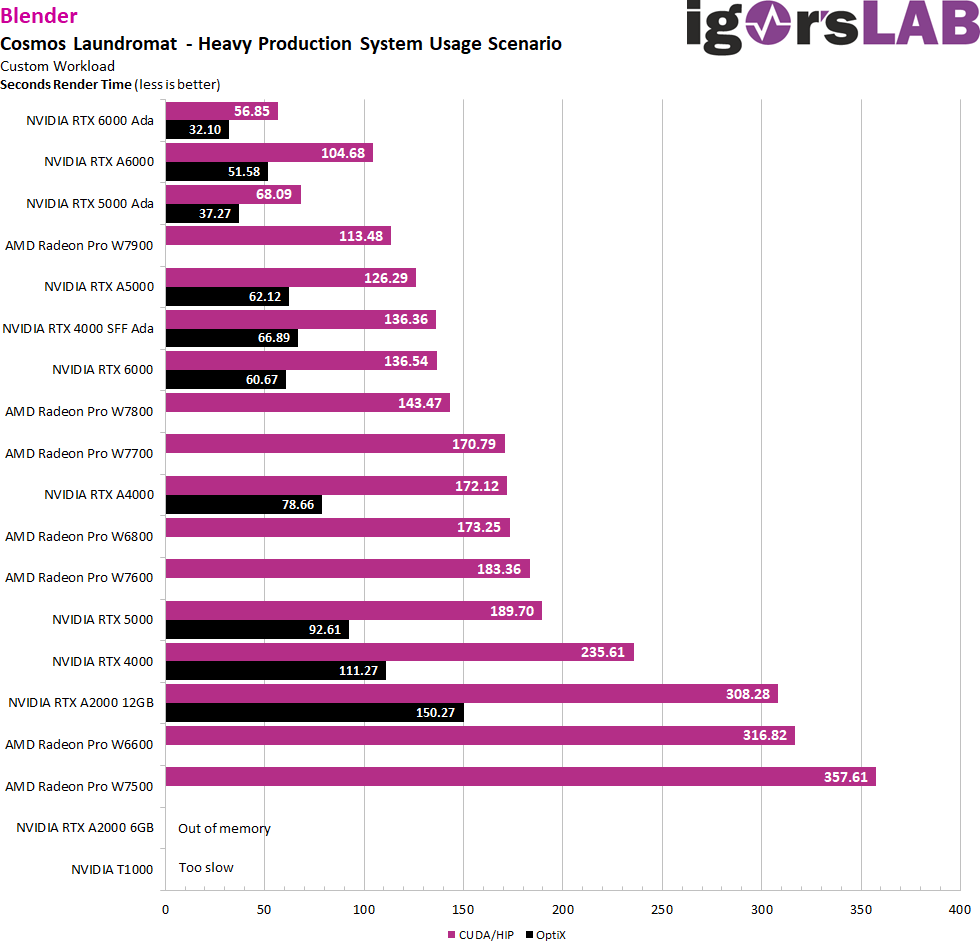
But what does it look like when you want to render a more complex task? This workload from “Cosmos Laundromat” uses Blender’s latest algorithms and enhancements to measure its full performance potential in a production system deployment scenario. “Cosmos Laundromat” is not only an impressive example of the capabilities of open source software in 3D animation, but also serves as a benchmark to test the efficiency and performance of hardware and software in professional production environments.
The algorithms and tools implemented in Blender are constantly changing and improving to meet the needs of artists and developers. With files like these, the industry can test the performance of their systems in real-world production conditions to ensure they are up to the ever-increasing demands of 3D rendering and animation. While the RTX A2000 6GB fails due to insufficient memory, the T1000 is simply too slow for the task.
GPU compute with synthetic tests
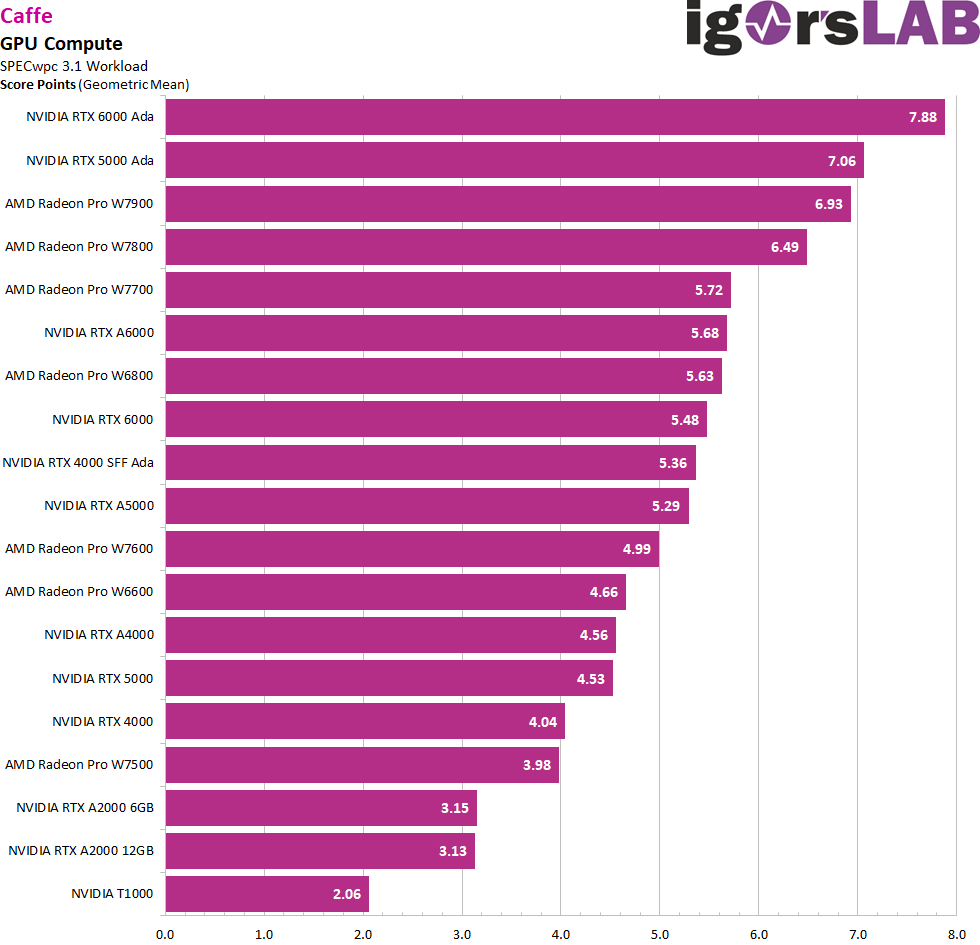
At the very end, I do unpack two of the synthetic bores, but somehow it’s part of the story. Caffe is an open source deep learning library originally developed by Yangqing Jia at UC Berkeley and later supported by the Berkeley Vision and Learning Center (BVLC). Caffe is particularly known for its performance on computer vision tasks, especially when working with Convolutional Neural Networks (CNNs).
The framework also provides Python and MATLAB bindings that make it easier for users to work with their models. Although once known for its simplicity and speed, other newer deep learning frameworks such as TensorFlow and PyTorch have grown in popularity but offer more flexible options for a broader range of deep learning tasks. Nevertheless, Caffe remains an important tool in the deep learning community.
FAH, or Folding@home, is a distributed computing project that aims to simulate protein folding processes. These simulations are important to deepen the understanding of many biological processes and diseases. What is unique about Folding@home is that it uses the unused computing power of computers from volunteers around the world. By installing the software on their computers, individuals can help run complex scientific simulations. This collaborative approach enables Folding@home to achieve computing power comparable to some of the world’s most powerful supercomputers. It was originally developed at Stanford University and over the years has become a significant tool for biomedical research, particularly in areas such as Alzheimer’s disease, Huntington’s disease and various forms of cancer.
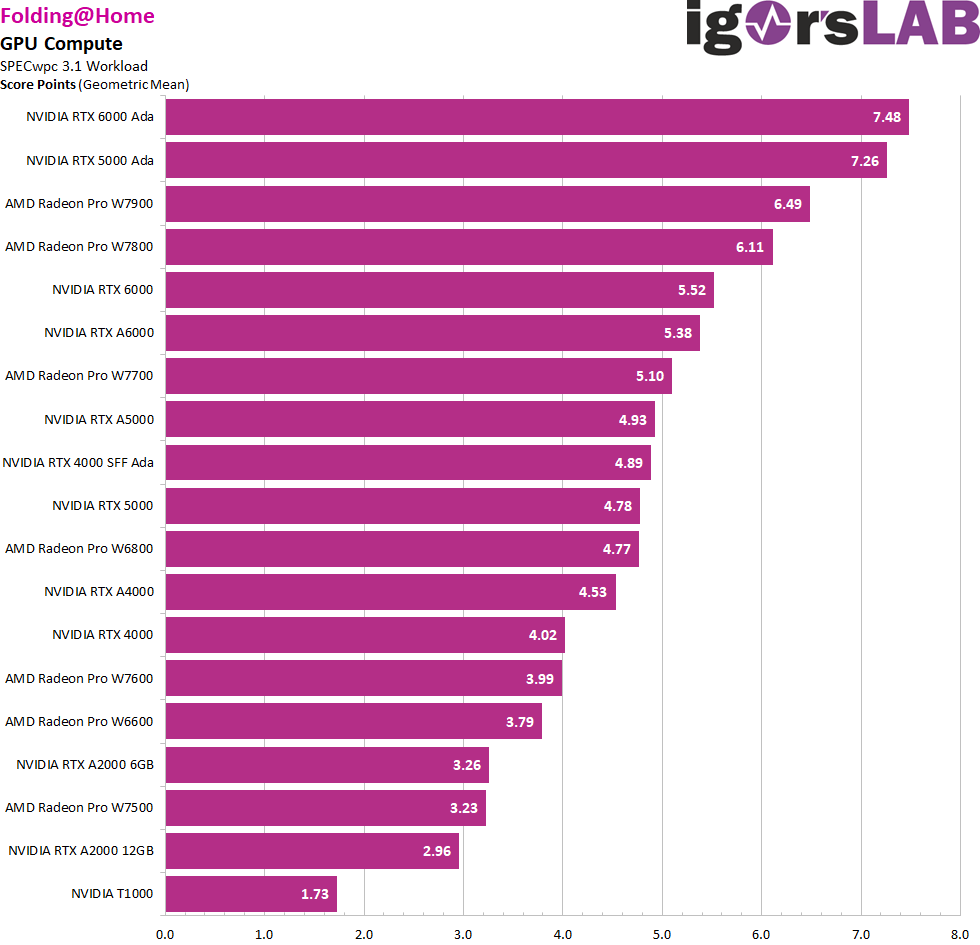
We can see from both applications that AMD has also made up ground here, even if the RTX 6000 Ada is the benchmark.

- 1 - Introduction, test system and software
- 2 - Autodesk AutoCAD 2024
- 3 - Autodesk Inventor Pro 2021
- 4 - PTC Creo 9 - No FSAA vs. FSAA
- 5 - Dassault Systèmes Solidworks 2022 - No FSAA vs. FSAA
- 6 - SPECviewperf 2020
- 7 - Adobe CC: Photoshop
- 8 - Adobe CC: Premiere Pro
- 9 - Adobe CC: After Effects
- 10 - Rendering and GPU compute
- 11 - Power consumption and conclusion


















57 Antworten
Kommentar
Lade neue Kommentare
Mitglied
Mitglied
1
1
Urgestein
Mitglied
Veteran
Urgestein
Urgestein
1
Veteran
1
Mitglied
Mitglied
Neuling
Veteran
Mitglied
1
Neuling
Alle Kommentare lesen unter igor´sLAB Community →