













It should be noted in advance that the differences between the configurations are extremely small and therefore difficult to represent in the form of bars. However, I didn’t want to present the Excel wallpaper to you completely unprocessed, which is why I decided to use a hybrid with corresponding data labels. These are already the calculated average values of several runs, which are actually reproducible, despite run-to-run variance of the software and relatively loud Windows background noise.
Geekbench 3: Memory and Total Multi-Core
We are already familiar with Geekbench 3 from the RAM kit reviews, but we only evaluate the multi-core memory score. In order to have another perspective on any interactions in the benchmark, the entire multi-core score is now also included in the evaluation in the data this time. As we know, the benchmark mainly focuses on throughput, but it can also notice larger differences in latency.
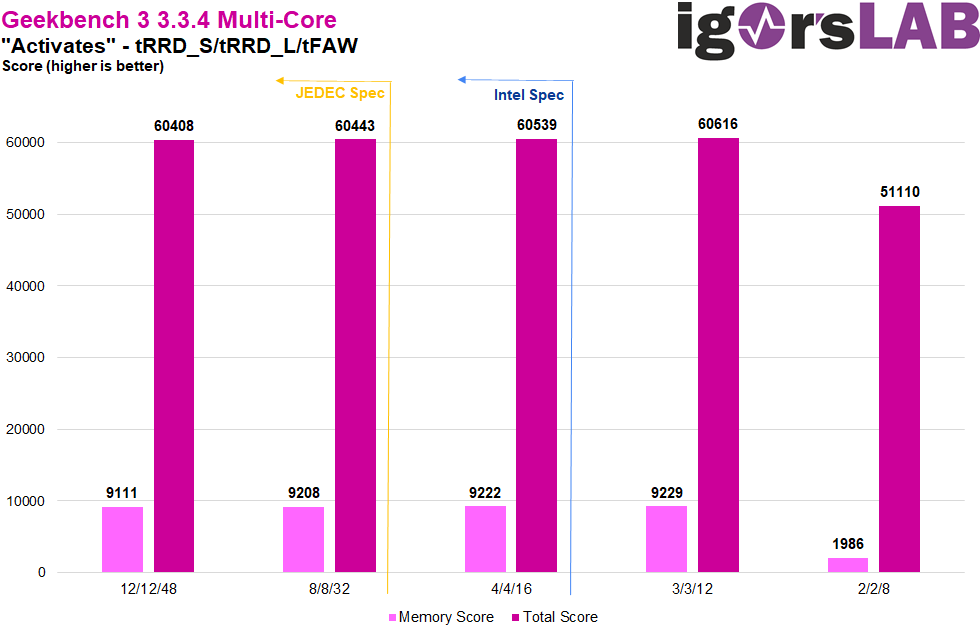
In fact, the Activates can already be seen in the results here. While 12/12/48 is clearly the worst performer, lower values can achieve better performance. The performance scales even below the specifications of JEDEC and Intel, with 3/3/12 as the fastest configuration. The only catch is that these timings below the Intel spec cannot be set in the BIOS, at least in the Z690 Tachyon. Instead, “Realtime Memory Timings” must be enabled and the setting made in Windows with Memtweakit. however, 2/2/8 is too far away from the shot, so that there is a clear drop in performance from here on.
SuperPi 32M
SuperPi is known to be an extremely latency-sensitive benchmark that almost doesn’t care about bandwidth. As noted at the beginning, hyperthreading is disabled because the communication between threads causes a relatively high inconsistency of the results and would thus distort the average. In addition, the Large Process Memory option was enabled and the process was pinned to the second of the 8 Golden Cove cores. Thus, differences in the range of seconds can be measured with the longest 32M preset.
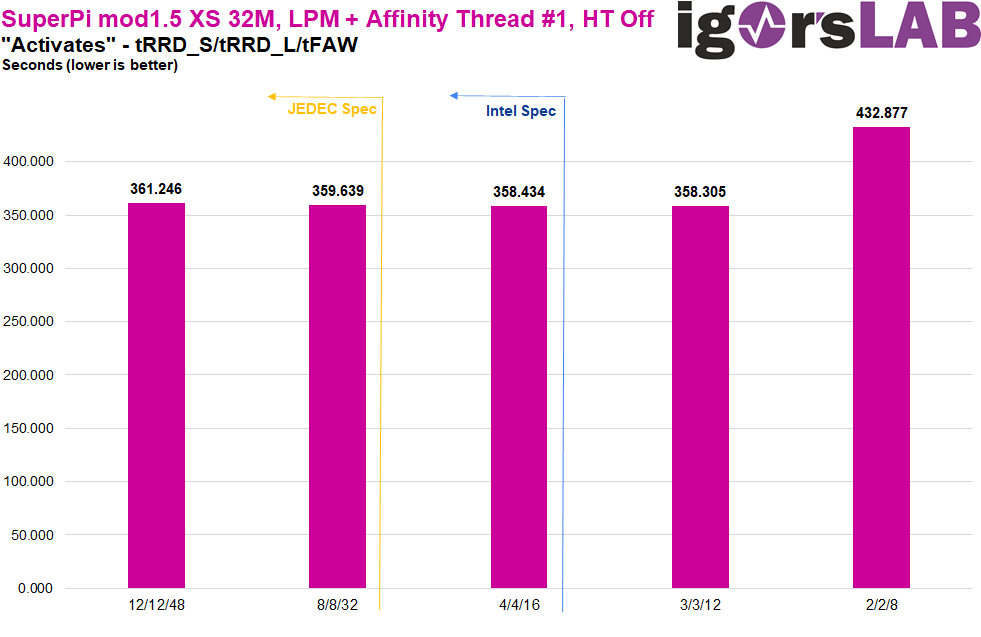
Similar to Geekbench 3, the performance scales beyond Intel and JEDEC specifications, with the climax at 3/3/12. 2/2/8 again runs into a kind of “emergency mode” with significantly worse performance. And even though the results are sometimes off by a second or two, the performance gain with lower timings is confirmed here in the average as well.
Bootable Linpack Xtreme 1.1.5 (Porteus)
The bootable Linpack Xtreme 1.1.5 is based on the Porteus operating system, which in turn is an extremely small and lightweight Linux distribution. This makes it perfect for the most accurate measurements possible with the Linpack Xtreme benchmark, which otherwise tends to fluctuate several percentage points between runs with Windows as the base. Unfortunately, the Linux OS also has a disadvantage, since Memtweakit doesn’t work here, so I can’t do timings below the Intel spec.
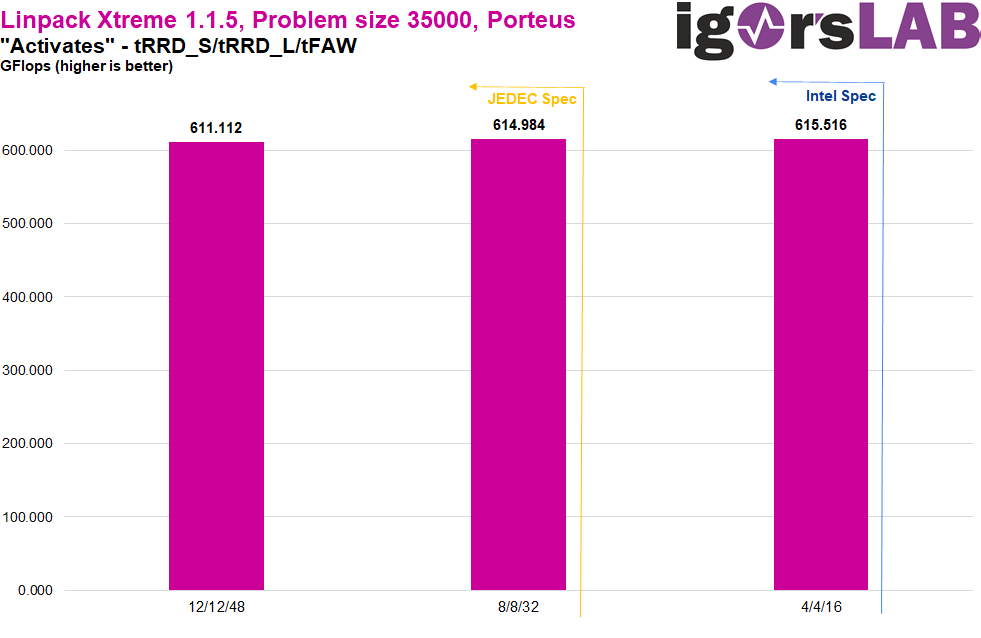
The picture of higher performance with lower activate timings is also confirmed in the Linpack Xtreme. Here, however, 12/12/48 is clearly worse relative to 8/8/32 than 8/8/32 is relative to 4/4/16. If we also take a closer look at the previous benchmarks, this phenomenon is also present there, only to a lesser extent. So there seem to be “diminishing returns” here, where the performance gain is not proportional to the theoretical timing savings.
y-cruncher 2.5b
Finally, there is the y-cruncher with preset 2.5b, provided by Benchmate. The load on RAM and CPU is similar to Linpack Xtreme, except that we can test below 4/4/16 with Windows and Memtweakit again. Since this benchmark tends to get faster from run to run, a new instance was started for each test run. In addition, “Interleave NUMA Nodes” was used as the memory allocator and “C++11 async” as the parallel framework for maximum performance on the Z690 platform.
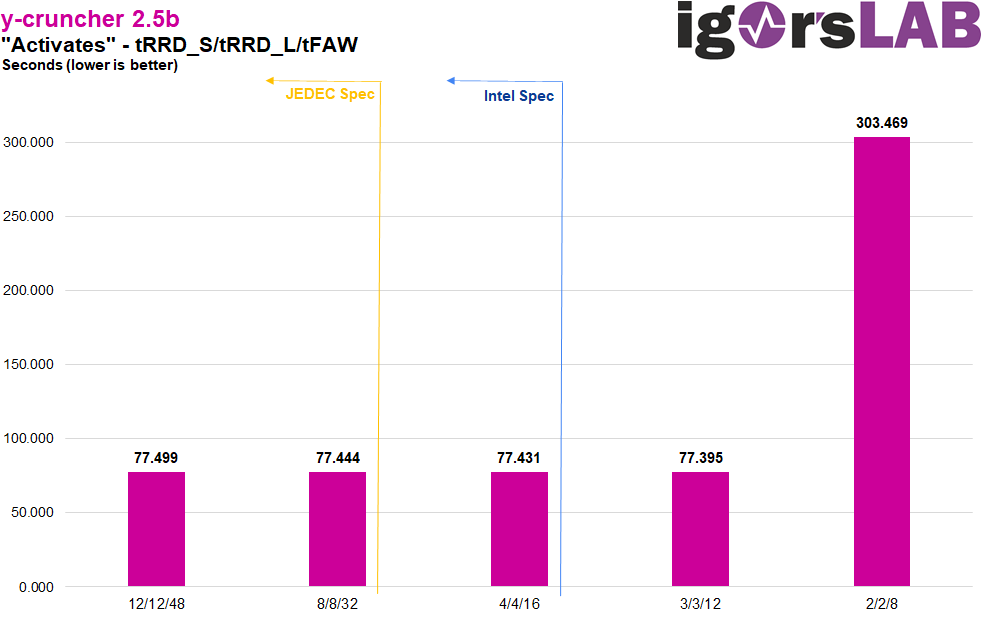
Again, the same pattern can be seen with performance scaling up to 3/3/12 and “diminishing returns” the lower the timings become. The emergency run at 2/2/8 also strikes again here, even stronger than in all other benchmarks. Since y-cruncher primarily prefers bandwidth and places less value on latency, a connection can be assumed here. Possibly, the IMC only allows 1 of 4 activates at all, which could explain a benchmark time that is about 4 times higher – but that is really only speculation on my part.


















Bisher keine Kommentare
Kommentar
Lade neue Kommentare
Artikel-Butler
Alle Kommentare lesen unter igor´sLAB Community →