













Der Einfluss von P-States auf die Performance
In etlichen unserer Gaming-Benchmarks bemerkten wir Performance-Ergebnisse, die niedriger ausfielen als erwartet, und nutzten nach Rücksprache mit AMD Windows‘ High-Performance-Power-Profil, um die Gaming-Performance zu verbessern. Diese Einstellung brachte zwar Verbesserungen, aber die Ryzen-CPUs lagen immer noch unterhalb ihrer Intel-Konkurrenten.
P-States passen die CPU-Taktfrequenz und -Versorgungsspannung (DVFS – Dynamic Voltage Frequency Scaling) an, um Energie zu sparen, wenn der Prozessor nicht voll ausgelastet ist. Im ausbalancierten Windows-Profil passt das Betriebssystem die P-States der CPU durch EIST adaptiv an die Workload-Intensität an. Leider limitiert die Kommandolatenz zwischen CPU und Betriebssystem die Effizienz dieser Technik.
Die CPU kann zudem nicht direkt von einer niedrigen zur höchsten Taktfrequenz springen, sondern muss sich schrittweise durch die dazwischenliegenden Zustände arbeiten, bis sie dann den maximalen Takt erreicht (daher auch der Begriff „Speed Step“). Das Ganze resultiert in sukzessiv höheren Latenzen, wenn von niedrigen P-States zur maximalen Taktfrequenz gewechselt wird.

Bei AMDs Ryzen-7-Prozessoren gibt es eine 30-ms-Latenz, wenn Windows den P-State ändert. Und wenn AMDs Implementierung der von Intel ähnelt (wir haben nachgehakt, warten aber noch auf Antworten), müsste der Prozessor also durch multiple P-States wechseln, um seine volle Performance zu entfalten. Intels Skylake-Prozessoren waren ebenfalls von einer durch das Betriebssystem verursachten 30-ms-Verzögerung betroffen, was negative Auswirkungen auf die Reaktionsfreudigkeit bei der Ausführung von Workloads mit schnell wechselnden Lasten hatte.
Intel fügte bei seinen Skylake-Prozessoren mehr P-States ein und reduzierte bei seinen Kaby-Lake-CPUs die Schaltlatenz auf 15 Millisekunden. Dadurch benötigen AMDs Ryzen-7-Prozessoren doppelt so viel Zeit (30 ms) wie Intels Kaby-Lake-Prozessoren zum Wechsel zwischen P-States, wenn das Betriebssystem die P-States kontrolliert.
Zur Umgehung dieser Latenz erlaubt es Microsoft dem Betriebssystem, die P-States-Kontrolle an den Prozessor zu übergeben – egal ob der von Intel oder AMD stammt. Dies erlaubt es der CPU, ihre eigenen, internen Sensordaten zur Entscheidungsfindung zu nutzen, um die Performance entsprechend der Daten anzupassen und so die Latenz durch das Betriebssystem zu eliminieren. Die Wahl des Stromsparprofils „Höchstleistung“ aktiviert dieses Feature. Wenn dieses Profil aktiv ist, wechseln sowohl AMD- als auch Intel-Prozessoren innerhalb einer Millisekunde zwischen P-States. Nach AMDs Meinung stellt das gleiche Ausgangsbedingungen dar.
Wir testeten populäre Spiele auf Intel-Prozessoren mit dem „Ausbalanciert“-Profil, listen für AMDs Ryzen-Prozessoren aber sowohl die Ergebnisse unter „Ausbalanciert“ als auch unter „Höchstleistung“.
Wir bleiben natürlich an AMD dran, was die Thematik P-State-Hierarchie angeht.
Das Dilemma bei Cache-Tests
Der Reviewers Guide für Ryzen enthält eine interessante Anmerkung bezüglich L1-, L2- und L3-Messwerkzeugen. AMD deutet sinngemäß an, dass AIDA64 und SiSoft Sandra – beides sehr gebräuchliche Tools für Cache-Messungen – „noch nicht bereit sind, die Cache-Performance der Zen-Architektur akkurat zu messen“.
AMD lieferte seine eigenen, intern gemessenen Referenzwerte und merkte an, dass man mit den FinalWare- (AIDA) und SiSoft-Sandra-Teams zusammenarbeite, um in der Zukunft akkurate Methodologie von Zen-Cache-Messungen zu ermöglichen.
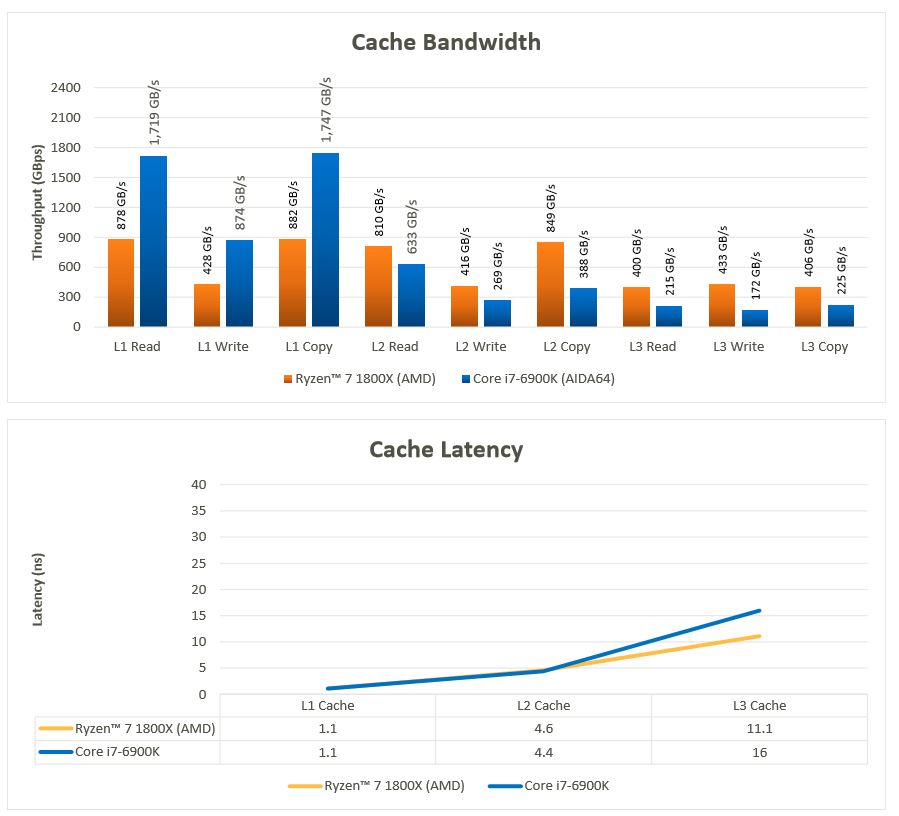
Wir maßen natürlich auch die Performance mit diesen Utilities und erzielten ähnliche Ergebnisse für Intels 6900K, bemerkten aber auch eine große Lücke zwischen den von AMD gelieferten Ryzen-Messungen und unseren Testergebnissen. Ryzens L3-Cache-Latenz maßen wir mit 20 bis 23 Millisekunden – doppelt so viel wie der von AMD gelieferte Wert.
Aufgrund der Performance-Charakteristika, die wir beim Benchmarking von Games bemerkten, testeten wir den Cache außerdem aktiviertem und deaktiviertem SMT, aber die Ergebnisse lagen innerhalb der zu erwartenden Schwankungsbreite. Wir maßen außerdem eine etwa 10 Nanosekunden große Speicherlatenzlücke zugunsten des Intel-Prozessors.
Viele gebräuchliche Utilities schreiben Nullen in den Cache, um dessen Performance zu messen. AMD antwortete auf unsere Anfragen und gab an, dass Intel eingehenden „Nullen“-Datenverkehr zusammenführt, bevor er an den Cache weitergegeben wird. Das könne in künstlich erhöhten Cache-Durchsatzmessungen resultieren – teilweise deshalb, weil solche Muster nicht in der Nutzung in der realen Welt vorkommen.
Unserer Meinung nach würde die Änderung der Zugriffsmuster in reduzierten Performance-Ergebnissen für die Intel-Prozessoren resultieren, aber sicherlich nicht AMDs Cache-Messungen verbessern. AMD antwortete, dass die aktuell verfügbaren Utilities nicht für Zens einzigartige Architektur optimiert seien und die Optimierung ihrer Codepfade mehr Performance aufzeigen würde.
Wir haben sowohl SiSoft als auch FinalWire kontaktiert und aktualisierte oder Beta-Versionen ihrer Utilities angefragt, um akkuratere Tests zu ermöglichen. Aktuell ist die Zusammenarbeit zwischen den beiden Firmen und AMD noch im vollen Gange und wir können an dieser Stelle leider keine Details dieser Konversation enthüllen.
Bis zu dem Zeitpunkt, an dem SiSoft, FinalWare und AMD sich darauf geeinigt haben, was genau passiert und welche Auswirkungen das auf Ryzen hat, wäre ein abschließendes Fazit unserer Messergebnisse unverantwortlich und im Endeffekt irreführend. Wenn wir finale, verifizierte und „echte“ Ergebnisse haben, werden wir diese nachliefern.
- 1 - Das Ryzen-Debüt
- 2 - AMD SenseMI Suite & XFR
- 3 - Die AM4-Plattform
- 4 - Overclocking und Test-Setup
- 5 - Power States und Cache-Tests
- 6 - Benchmarks: Ashes of the Singularity & Battlefield 4
- 7 - Benchmarks: Hitman, Project CARS & Metro: Last Light
- 8 - Ergebnisse: Desktop und Office
- 9 - Ergebnisse: Workstation
- 10 - Ergebnisse: Wissenschaftlich-technische Berechnungen und HPC
- 11 - Ergebnisse: Leistungsaufnahme und Abwärme
- 12 - Fazit















Kommentieren