












Verschiedene Binnings bei NVIDIAs GeForce RTX 4070 – MSRP-Karten mit unbeabsichtigtem OC-Feature und die technischen Hintergründe (von Boost) | Exklusiv
Das Binning als Vorabselektion und die Rolle von „Speedo“
So, jetzt kommt die angedrohte Theorie, aber ich will es so einfach wie möglich halten und Euch auch die wichtigsten Begriffe gleich mit erklären. Zunächst bleiben wir recht allgemein. Das sogenannte Binning bezieht sich bei den GPUs auf das Einsortieren dieser GPUs in verschiedene Qualitätsklassen („Buckets“) innerhalb eines gewissen Von-Bis-Bereiches. Die einzelnen GPUs aus so einem „Bucket“ können also auch noch einmal jeweils untereinander und voneinander abweichen, aber nur im Rahmen der vorgegebenen Toleranzen (sogenanntes „GPU-Lotto“ beim Kunden).
Wenn man eine Grafikkarte erwirbt, dann können es Produkte mit unterschiedlich beworbenen Taktraten sein, aber sie besitzen alle das gleiche Design und denselben Herstellungsprozess. Die GPUs werden jedoch aufgrund der Prozessvariation (Qualitätsschwankungen) voneinander getrennt. Sie haben jedoch alle etwas gemeinsam: eine maximale Leistungsspezifikation, die als TGP (auch bekannt als Total GPU Power) bezeichnet wird. Womit ich an die Umkehrung dieser Tatsache bei den MSRP-Karten auf Seite Eins erinnern möchte, die auch etwas mit dem „Virtuellen Binning“ zu tun hat.
Das ist dann nämlich nächsthöhere Schritt. Hier stellt man im Allgemeinen verschiedene Buckets mit identischen Taktraten zusammen. Die AIC und der Endkunde legen allerdings stets den größten Wert auf das Verhältnis von Performance zu benötigter Energie, so dass NVIDIA den Abnehmern deshalb „Buckets“ anbietet, die jeweils nur Chips umfassen, die bei ähnlicher TGP auch die gleiche Performance bieten. Das kann sparsamer oder durstiger sein, aber innerhalb des Buckets sind alle GPUs zumindest mehr oder weniger gleich schnell. Da unterscheiden sich die „Buckets“ nur durch die unterschiedliche Leistungsaufnahme.
Diese „Buckets“ können dann, je nach Qualitätsstufe, bei sehr unterschiedlichen Spannungen betrieben werden. Die Leistungsspezifikation ist das Maximum einer virtuellen Performance so eines „Buckets“. Die tatsächliche Implementierung besteht in der Endkonsequenz dann einzig und allein darin, langsamere Chips mit höherer Spannung und schnellere Chips mit niedrigerer Spannung zu betreiben, damit die beste Leistung für ein gegebenes Leistungsumfeld erzielt werden kann. Die Taktrate des Chips (langsam vs. schnell) wird durch eine Variable namens „Speedo“ gesteuert, die während des ATE-Flusses als Teil der FT (Final Test) Phase in die GPU eingebrannt wird.
Genau jetzt muss ich aber wohl noch Einiges erklären. ATE steht für „Automated Test Equipment“ (Automatisierte Testausrüstung). Es handelt sich dabei um Systeme, die elektronische Bauteile oder Leiterplatten automatisch auf Funktionsfähigkeit und Qualität prüfen (Erhöhung der Produktionseffizienz zu erhöhen und Reduzierung der Fehlerquote). Die „Final Test Phase“ ist die letzte Testphase in einem Produktions- oder Entwicklungsprozess, wo alle zuvor identifizierten Fehler behoben und das Produkt auf seine Funktionsfähigkeit, Leistung und Qualität geprüft wird.
„Speedo“ ist ein Begriff, der in der Halbleiterindustrie für Schaltungen verwendet wird, die die Prozess-, Spannungs- und Temperaturvariationen (PVT) in integrierten Schaltkreisen überwachen. Solche speziellen Speedo-Schaltungen ermöglichen es den GPUs, ihren Leistung und Energieverbrauch dynamisch anzupassen, indem sie die Reaktion der Chips auf Veränderungen in Prozess, Spannung und Temperatur berücksichtigen. Diese Anpassungen können beispielsweise durch das Ändern der Taktfrequenz und der Versorgungsspannung erreicht werden. Dazu komme ich gleich im nächsten Absatz.
Die Telemetrie aktueller NVIDIA-Grafikkarten
Jetzt will ich NVIDIAs Boost (und in gröberer Form auch AMDs Power Tune) beschreiben und das gerade Gelesene etwas allgemeinverständlicher in einen Zusammenhang bringen, auch wenn ich mich dabei sicher etwas wiederholen muss (Schema unten). Die Aufgabe der sogenannten Telemetrie ist es, die maximale Grafikperformance bei möglichst minimaler Leistungsaufnahme und der entstehenden Nebenwirkungen wie z.B. die Abwärme zu erreichen und die ganzen Überwachungsdaten dafür heranzuziehen. Das Hauptanliegen besteht darin, die Kernspannung der GPU in Echtzeit möglichst so anzupassen, dass nur so viel Leistung zugeführt wird, wie man für die aktuelle Auslastung der GPU und das Erreichen der optimalen Taktrate auch wirklich benötigt.
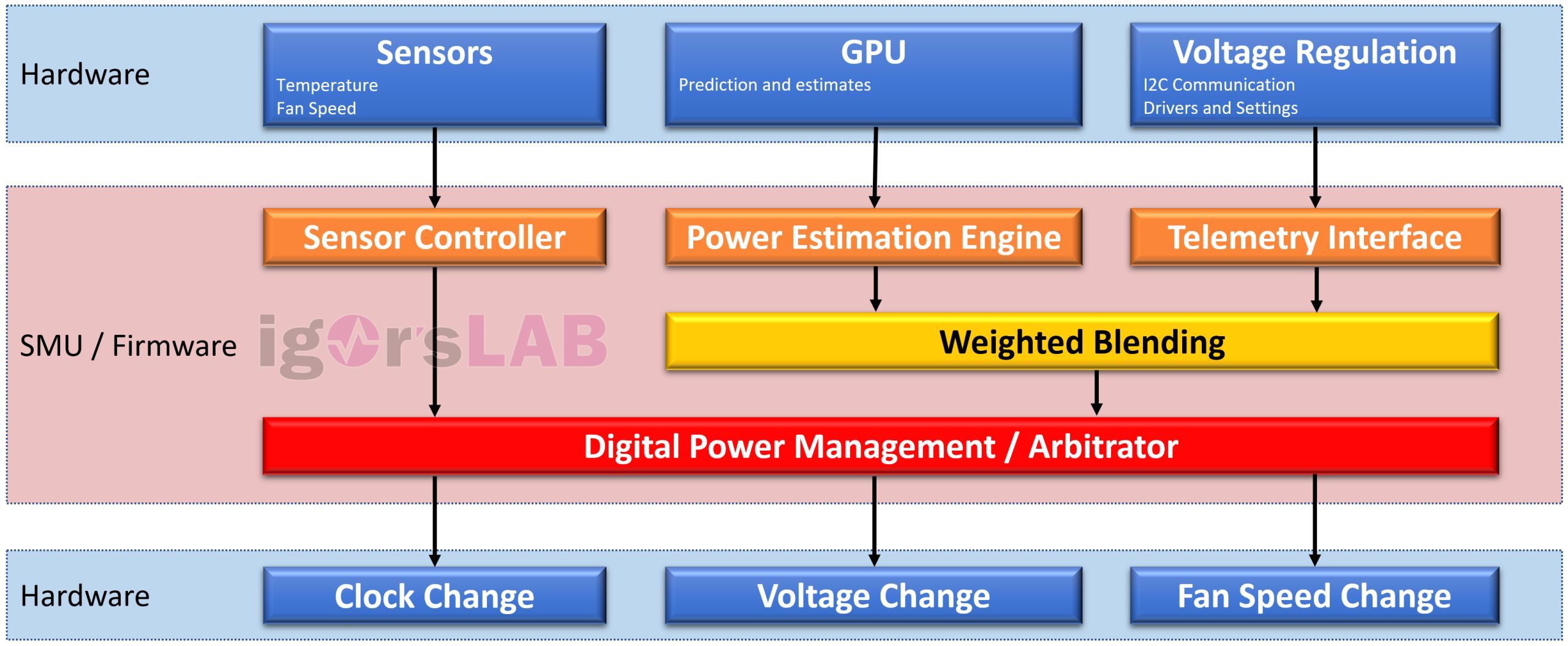
Nennen wir es zunächst erst einmal ganz einfach Spannungskurve (das hat sicher jeder schon einmal gehört), auch wenn ich später noch weiter ins Detail gehen muss. Um es einmal gebrauchsfertig zu formulieren: Es wurden die einzelnen Boost-Steps samt Vorgabespannung hinterlegt, wobei der Takt der untersten Boost-Stufe durch einen sogenannten Offset verschoben bzw. festgelegt wird und sich der Rest dann aus den Berechnungen des Arbitrators (Mittlers) ergibt. Bei AMD legt man die Taktraten und Spannungen für einige vorgegebene DPM-States fest, was deutlich ungenauer (granulärer) ist, aber am Ende so ähnlich funktioniert.
Die Firmware schätzt in sehr kurzen Intervallen ständig den Energieverbrauch (quasi in Echtzeit), fragt gleichzeitig die ganzen Sensoren sowie die GPU-Vorhersage ab und bezieht die Telemetrie-Daten des Spannungsreglers bzw. der Eingangsüberwachung (Shunts, Bild unten) mit ein. Diese Werte werden an das vorprogrammierten DPM (digitales Power-Management), also den Arbitrator (Mittler) gesendet. Dieser Regelkomplex kennt auch die Power-, thermischen und Stromstärken-Limits der GPU (BIOS, Treiber), die er aus den jeweiligen Registern auslesen kann. Innerhalb dieser Grenzen kontrolliert er nun also die Temperaturen, alle Spannungen, Taktfrequenzen sowie die Lüftergeschwindigkeiten und versucht dabei stets, die maximale Performance aus der Karte herauszuholen. Wenn auch nur eine der Eingangsgrößen überschritten wird, kann der Mittler Spannung oder Takt zurücknehmen.

Das Nachteilige an so einer öffentlich sichtbaren (und mit geeigneter Software auch anpassbarer) „Frequenz-/Spannungskurve“ ist, dass man sie eigentlich gar nicht so einfach pauschal festlegen kann. Das, was der Endanwender in Wirklichkeit nur modifizieren kann, ist eine gewisse partielle Verschiebung auf der Basis von zuvor errechneten, individuellen Grenz- und Richtwerten eines jeden einzelnen Chips unter den aktuellen Bedingungen! Hier kommt nun die sogenannte VFE ( Voltage Frequency Engine) ins Spiel, die einen flexiblen Rahmen bietet, um die Beziehung zwischen den Taktfrequenzen zu spezifizieren bzw. zu bewerten, die normalerweise eine Funktion von Spannung, Speedo und Temperatur ist. Oder um es kurz auf den Punkt zu bringen: Die ermittelte Spannung für jeden dieser Frequenzpunkte einer solchen Kurve ist eigentlich eine Funktion des Speedos der GPU, der durch das „Continuous Virtual Binning“ bestimmt wird.
Ihr ahnt es schon, jetzt wird es etwas kniffliger. Wir erinnern uns gern an die ersten Absätze zum Binning und dem ATE-Fluss: Continuous Virtual Binning (CVB) nutzt statistische Modelle und Algorithmen, um die Leistung von Halbleiterbauteilen kontinuierlich und virtuell zu analysieren, anstatt sie tatsächlich physisch zu testen. „Continuous Virtual Binning“ bedeutet in unserem Fall der GPU also, dass die Spannung bei einer Erhöhung des Speedos um denselben Betrag um 10 mV (reguläre Schrittgröße) abnimmt (basierend auf einer linearen oder quadratischen Gleichung). Die Spannung für jeden Frequenzpunkt ist eine Funktion der Temperatur der GPU.
Die Taktfrequenz und damit auch die Spannungen der GPU hängen von der Temperatur ab. Halbleiter (p-Typ und n-Typ) können entweder einen positiven oder negativen Temperaturkoeffizienten aufweisen und bei steigender Temperatur kann die Bewegung in MOS-Transistoren abnehmen. Diese Abnahme erhöht die Schwellenspannung (Threshold Voltage, Vt). Dies macht den Transistor langsamer. Daher wird eine Erhöhung der Temperatur die Taktfrequenz verringern und umgekehrt. Diese Temperaturabhängigkeit wird in derselben quadratischen Gleichung erfasst, die auch den Speedo des Chips nutzt. Da die in den Stufen vorgegebene Frequenz logischerweise gesperrt bleiben muss, erhöht sich die Spannung bei steigender Temperatur, um die angeforderte Frequenz noch zu erreichen (bzw. umgekehrt). Diese quadratische Gleichung, die die Beziehung zwischen den Frequenzen und ihren entsprechenden Spannungen erfasst, wird vom sogenannten VFE-Rahmen erfasst, der als Teil der Konfigurationsdaten in der VBIOS-Firmware auf dem EEPROM des Chips gespeichert ist und nicht mehr überschrieben werden kann.
Die Hauptfunktion der VFE besteht also darin, die Spannung und Frequenz der Prozessoren dynamisch anzupassen, um die Leistung und Energieeffizienz zu optimieren. Die VFE arbeitet eng mit der PMU (Power Management Unit) zusammen, um die richtigen Spannungs- und Frequenzwerte für verschiedene Betriebszustände und Lastbedingungen zu liefern. Dazu komme ich dann im nächsten Absatz. Zusammengefasst kann man sagen, dass die Voltage Frequency Engine und Speedo zusammenarbeiten, um die Leistung und Energieeffizienz zu optimieren. Die VFE ist für die Anpassung der Spannung und Frequenz verantwortlich, während Speedo die PVT-Variationen überwacht und die notwendigen Informationen für die VFE liefert, um die richtigen Anpassungen vorzunehmen.
So, jetzt holen wir besser erst einmal etwas Luft. Wobei es gar nicht so kompliziert ist, wie es sich vielleicht beim ersten Mal lesen mag. Um es kurz zu machen: Den Speedo kann man weder überlisten noch überschreiben. Was man manuell ändern kann, basiert immer auf dem jeweils hinterlegten Speedo und den Werten der VFE, auf die der Endkunde ebenfalls keinen Einfluss hat. Und nun wissen wir auch, dass eine gute Kühlung oft mehr wert ist als das brutalste OC. Es ist das gefürchtete Hund-Schwanz-Prinzip bei luftgekühlten Karten, wo eine Erhöhung des Power Limits für einen höheren Takt auch zu höheren Temperaturen und damit wieder niedrigeren Taktraten führt. Man kann das ewig treiben und die Karte wird doch nicht schneller. Nur durstiger. Genau deshalb ist das gegenteilige Untervolten ja so clever, weil es durch niedrigere Temperaturen höhere Boost Steps ermöglicht. Also quasi verlustfreies OC für lau.

Und wie wird das alles initialisiert und zur Laufzeit abgefragt?
Hierfür steht die sogenannte PMU-Init-Phase (Power Management Unit Initialization Phase) im Fokus. Dabei handelt es sich um einen Schritt im Startvorgang von Systemen die auf einer Power Management Unit (PMU) basieren, welche die verschiedenen Spannungs- und Stromversorgungsstufen bereitstellt. Während dieser Phase werden die grundlegenden Funktionen der PMU initialisiert, also die Initialisierung der Spannungsregler, die Einstellung von Stromversorgungsschwellen, die Konfiguration von Power-On-Reset (POR) und die Initialisierung von Power-Good-Signalen.
Wie bei allen Konfigurationsdaten liest der NVGPU-Treiber diese Konfigurationsdaten zunächst aus der VBIOS-Firmware und leitet sie während der GPU-Initialisierungsphase an den PMU-Mikrocode-Perf-Task weiter. In der oben beschriebenen PMU-Init-Phase liest der Perf-Task auch den Speedo der GPU und speichert ihn im Cache. Anschließend werden Stichproben der GPU-Temperatur genommen und die VFE-Gleichung für jeden einzelnen Frequenzpunkt in der V/F-Kurve gelöst.
In der PMU-Laufzeitphase (siehe Schema am Anfang der Seite) nimmt der Perf-Task dann z.B. alle 200 ms (programmierbar) u.a. Stichproben der GPU-Temperatur. Wenn die Temperatur einen (programmierbaren) Hysterese-Wert überschreitet, wird die V/F-Kurve erneut ausgewertet, indem die entsprechende VFE-Gleichung gelöst und die AVFS-Hardware neu programmiert wird. Und diesen netten Loop wiederholt die Karte so lange, bis wir den Rechner wieder brav ausschalten.
Zusammenfassung und Fazit
Vor allem diese zweite Seite zeigt, dass die in dem GUI mancher Programme änderbaren „Kurven“ eine unveränderbare Basis besitzen und wir als Endkunden letztendlich nur ein paar Offsets hin- und herschieben dürfen. Die Gene sind bei allen Karten mit dem gleichen Chip identisch, nur die Performance bzw. die dafür benötigte Energie wird sich unterscheiden. Was man dann manuell ändern kann, lotet lediglich die Ober- und Untergrenzen des jeweiligen „Buckets“ aus, aus dem der Chip stammt. Denn da gibt es immer noch deutliche Unterschiede.
Und um noch einmal auf die GeForce RTX 4070 zurückzukommen: alles kann, aber nichts muss! Deshalb sollte man bei den 215-Watt-Karten eher verhalten optimistisch sein. Momentan scheint ja alles noch gut zu funktionieren, aber NVIDIA wäre auch sicher nicht NVIDIA, wenn es das ganze Jahr über solche Geschenke gäbe.

Danke für die Spende

Du fandest, der Beitrag war interessant und möchtest uns unterstützen? Klasse!
Hier erfährst Du, wie: Hier spenden.
Hier kannst Du per PayPal spenden.
You may also like





About the author
Igor Wallossek
Chefredakteur und Namensgeber von igor'sLAB als inhaltlichem Nachfolger von Tom's Hardware Deutschland, deren Lizenz im Juni 2019 zurückgegeben wurde, um den qualitativen Ansprüchen der Webinhalte und Herausforderungen der neuen Medien wie z.B. YouTube mit einem eigenen Kanal besser gerecht werden zu können.
Computer-Nerd seit 1983, Audio-Freak seit 1979 und seit über 50 Jahren so ziemlich offen für alles, was einen Stecker oder einen Akku hat.










49 Antworten
Kommentar
Lade neue Kommentare
Mitglied
Urgestein
1
Urgestein
1
Mitglied
Urgestein
1
Mitglied
1
Mitglied
1
Urgestein
1
Veteran
Urgestein
1
Urgestein
Urgestein
Alle Kommentare lesen unter igor´sLAB Community →