












Ich will das Endergebnis ja eingangs noch gar nicht spoilern, aber wenn man als direkten Vergleich zunächst die Vorgängerin Quadro P4000 benchmarkt, nur um dann ungeplant aber neugierig ins Regal greifen zu müssen und auch noch eine Quadro P5000 damit galant zu plätten, dann kneift man sich schon zweimal verdutzt in den Unterarm. Zumal man diese kleinste RTX-Quadro schon für unter 900 Euro bekommt und sie immer noch günstiger ist, als eine Radeon Pro WX 8200, die zudem deutlich… Nein, ich verrate jetzt erst einmal nichts mehr, denn nur selbst lesen macht auch schlauer.
Zum heutigen Test treten an: die Nvidia Quadro RTX 4000 und als in etwa vergleichbar eingeschätzte Karten wie die Quadro P4000 und P5000, sowie die AMD Radeon Pro WX 8200, die Radeon Vega Frontier Edition (FE) und die Radeon VII. Letztere habe ich deshalb mit in den Test aufgenommen, weil es eine interessante Karte ist und die Pressemeldung von AMDs PR-Agentur ja verlauten ließ, der neue All-in-One-Treiber würde die Radeon VII auch in Zukunft bei professionellen Anwendungen unterstützen. Dass dem auch jetzt noch nicht ganz so war, beweist zumindest dieser Test und ich werde es beobachten, wenn der Treiber demnächst für das Q2 kommt.

Die Quadro RTX 4000
Die nur 480 Gramm schwere Karte misst in der Länge 24,4 cm von der Außenkante der Slotblende bis zum Ende der Kühlerabdeckung und sie ist zwischen der Oberkante des PCIe-Slots bis zur Oberseite des Kühlers nur 10,5 cm hoch. Mit 1,4 cm Dicke ist sie zudem eine echte Single-Slot-Karte. RGB-Gebammel findet man nicht. Die Kühlerabdeckung ist ein Mix aus mattschwarzem Aluminiumguss und einer metallischen Abdeckplatte.




Der 8-Pin Spannungsversorgungsanschluss an der Rückseite ist überdimensioniert, denn für die maximal 125 Watt, für die diese Karte per Firmware ausgelegt ist, hätte auch ein 6-Pin-Anschluss locker gereicht. Es sei denn, man nutzt die Platine auch noch für eine größere Karte mit, denn der Chip ließe dies ja zu. Doch dazu gleich mehr.

An der Slot-Blende findet man drei DisplayPort 1.4 sowie einen VirtualLink.

An der Oberseite der Karte gibt es dann dann noch die Buchsen für VirOptional Stereo und Quadro Sync II.

Der technische Unterbau der Quadro RTX 4000
Die Quadro RTX 4000 ist derzeit die kleinste der Quadro-RTX-Karten und es bleibt interessant abzuwarten, ob und wann z.B. auf Basis des TU106 und TU116 auch noch kleinere Karten als Quadro mit und ohne RTX folgen werden. Die Quadro RTX 4000 setzt auf den gleichen TU104, wie auch die GeForce RTX 2080, wurde jedoch per Hardware-Strap auf die technischen Daten des TU106 einer GeForce RTX 2070 zusammengestrichen und besitzt zusätzlich ein deutlich niedrigeres, maximales Power Limit von nur 125 Watt.
Die Karte nutzt demnach also keine vollausgebaute TU106-GPU, die ja ebenfalls aus drei GPCs mit jeweils sechs TPCs besteht und was eigentlich auf der Hand gelegen hätte, sondern einen deutlich abgespeckten, viel größeren TU104 mit den gleichen Eckdaten wie der TU106. Dies ist etwas, was durchaus einigermaßen verwundert. Der Rest der Specs ergibt sich dann jedoch automatisch, denn natürlich beinhalten die TPCs jeweils zwei SMs, so dass dies 36 SMs für den gesamten Prozessor ergibt, der als TU104-850 ausgewiesen wird.


Diese Blöcke bleiben zwischen den Turing-GPUs unverändert, so dass die Quadro RTX 4000 mit 2304 CUDA-Kernen, 288 Tensor-Kernen, 36 RT-Kernen und 144 Textureinheiten ausgestattet ist und damit auch 1:1 der GeForce RTX 2070 entspricht, obwohl sie auf dem größeren Chip basiert. Der TU104-850 behält den gleichen 256-Bit-Speicherbus bei und ist ebenfalls mit 8 GB und 14 Gb/s GDDR6-Modulen bestückt, die aufgrund des niedrigeren Speichertaktes von 1625 MHz hier bis zu 416 GB/s umschaufeln können. Die 4 MB L2-Cache und 64 ROPs werden ebenfalls übernommen.
Die Quadro RTX 4000 ist ein gelungener Versuch, Tensor- und RT-Kerne so tief wie möglich in den Chip zu integrieren, damit diese Funktionen trotz Downscaling noch verfügbar bleiben. Es wird sehr interessant sein zu sehen, wie funktionell sie in fast halbierten Mengen gegenüber den größeren RTX-Modellen in Zukunst bestehen kann. Die einzige Fähigkeit, die dem TU104-850 eklatant fehlt, ist NVLink. Das ist zwar schade, aber aufgrund der möglichen Kannibalisierung der nächsthöheren (und auch teureren) Karten durchaus beabsichtigt.
Turing und mögliche Leistungsverbesserung in herkömmlichen Anwendungen
Fakt ist ja, dass Turing-basierte Karten nicht dramatisch höhere CUDA-Kernzahlen aufweisen als ihre Vorgängergenerationen und zudem auch nicht ganz so hohe Boost-Taktraten besitzen. Aber das Unternehmen hat sich durchaus einige Mühe gegeben, Turing für eine bessere Leistung pro Kern zu konstruieren. Zunächst lehnt sich Turing so ziemlich genau an das Volta-Playbook an, um die gleichzeitige Ausführung von FP32- und INT32-Operationen zu unterstützen. Wenn man nun davon ausgeht, dass die Turing-Kerne bei einer bestimmten Taktfrequenz eine bessere Leistung erzielen können als Pascal, dann erklärt auch und vor allem diese spezielle Fähigkeit weitgehend, warum das wirklich so ist.
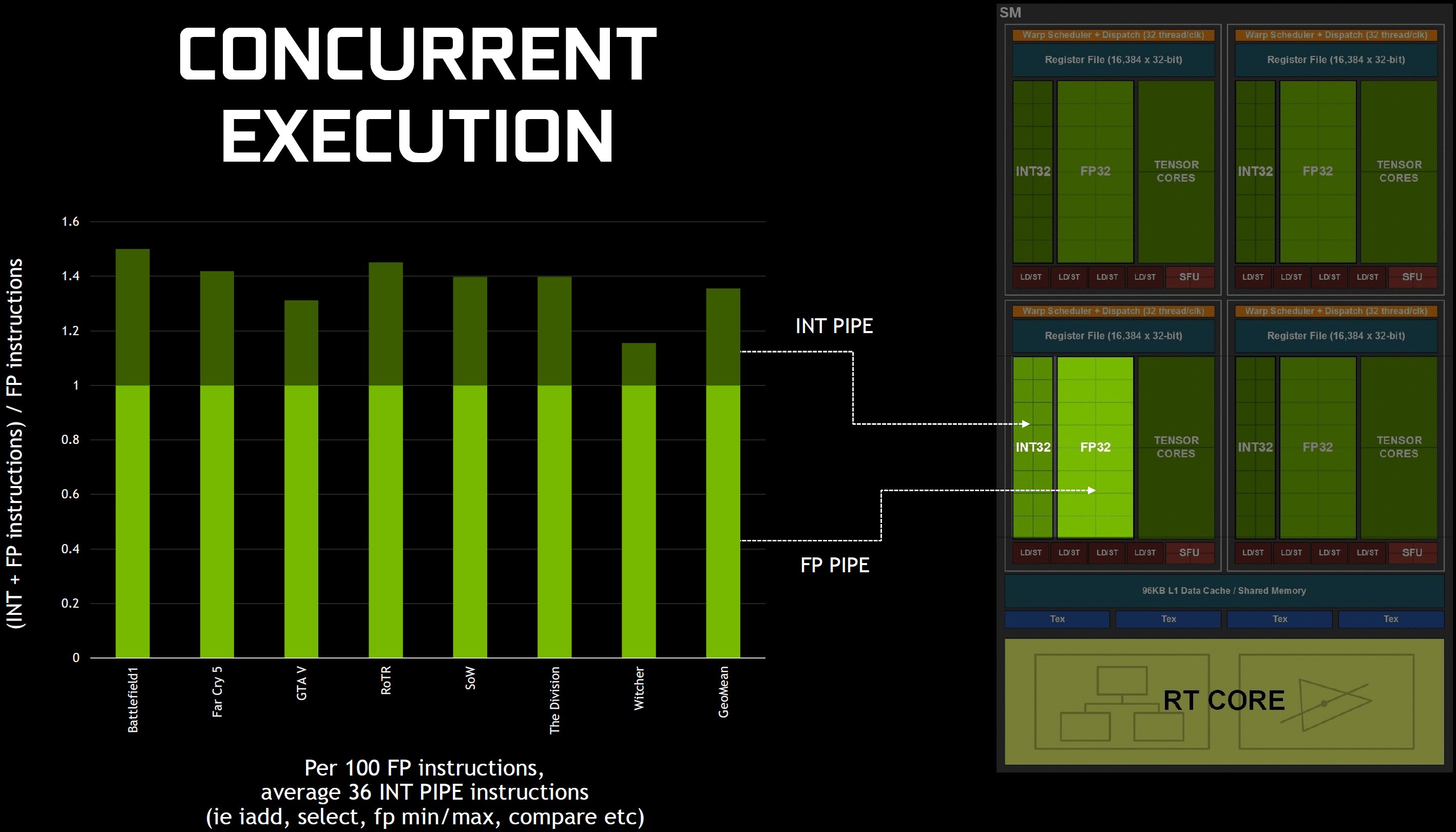
Doch um was geht es genau? In früheren Generationen bedeutete ein einziger mathematischer Datenpfad, dass ungleiche Befehlsarten nicht gleichzeitig ausgeführt werden konnten, so dass die Fließkomma-Pipeline stillstand, wenn z.B. in einem Shader-Programm Nicht-FP-Operationen benötigt wurden. Bei Volta versuchte man schließlich dies zu ändern, indem man getrennte Pipelines schuf. Obwohl Nvidia die zweite Dispositionseinheit, die jedem Warp-Scheduler zugeordnet war, eliminierte, stieg der einst problematische Durchsatz der Instruktionen. Turing verfolgt nun einen ähnlichen Ansatz, indem es eine Warp-Scheduler- und Dispositionseinheit pro Quad (vier pro SM) gibt und man gleichzeitig Anweisungen für die INT32- und FP32-Pipeline erteilen kann.
Trotz der Trennung von FP32- und INT32-Pfaden in den Blockdiagrammen, schreibt Nvidia in den technischen Erklärungen, dass jeder Turing SM 64 CUDA-Cores enthält, um die Dinge möglichst einfach zu halten. Der Turing SM umfasst zudem noch 16 Lade-/Speichereinheiten, 16 Spezialfunktionseinheiten, 256 KB Registerdateispeicher, 96 KB Shared Memory und L1 Data Cache, vier Textureinheiten, acht Tensor-Kerne sowie einen RT-Kern.
Diese Erhöhung des On-Die-Speichers spielt eine weitere, sehr entscheidende Rolle bei der Leistungssteigerung, ebenso wie die hierarchische Organisation. Wie beim GP102 und GP104 sind auch die Streaming Multiprozessoren des TU104 in vier Blöcke unterteilt. Aber während sich die Pascal-basierten GPUs 24 KB L1 Daten- und Textur-Cache zwischen jedem Blockpaar und 96 KB gemeinsamem Speicher über die SM teilen, vereinheitlicht der TU104 diese Einheiten in einer flexiblen 96-KB-Struktur.
Der Vorteil der Vereinheitlichung besteht darin, dass unabhängig davon, ob ein Workload für L1 oder Shared Memory optimiert ist, On-Chip-Speicher genutzt wird, anstatt wie bisher untätig zu bleiben. Das Verschieben der L1-Funktionalität nach unten hat den zusätzlichen Vorteil, dass sie auf einen breiteren Bus gelegt wird, wodurch die L1-Cache-Bandbreite verdoppelt wird (während die Bandbreite des gemeinsamen Speichers unverändert bleibt).
Im Vergleich von TPC zu TPC (d.h. bei gleicher Anzahl von CUDA-Cores) unterstützt Pascal 64B/Takt-Cache Hits pro TPC, Turing unterstützt 128B/Takt-Cache Hits, d.h. auch hier liegt die Leistung doppelt so hoch. Und da diese 96 KB als 64 KB L1 und 32 KB Shared Memory (oder umgekehrt) frei konfiguriert werden können, kann die L1-Kapazität pro SM ebenfalls um 50% höher sein. Übrigens sieht Turings Cachestruktur auf den ersten Blick sehr ähnlich aus wie Kepler, wo man über einen konfigurierbaren 64 KB Shared Memory/L1-Cache verfügte.
Zur Erklärung: es gibt drei verschiedene Datenspeicher – den Textur-Cache für Texturen, den L1-Cache für generische LD/ST-Daten und Shared Memory für die Berechnung. In der Kepler-Generation war die Textur getrennt (der schreibgeschützte Daten-Cache), während L1 und Shared kombiniert wurden. In Maxwell und Pascal hatte man auch noch zwei getrennte Strukturen, nur etwas modifiziert. Nun werden alle drei zu einem gemeinsamen und konfigurierbaren Speicherpool zusammengefasst.
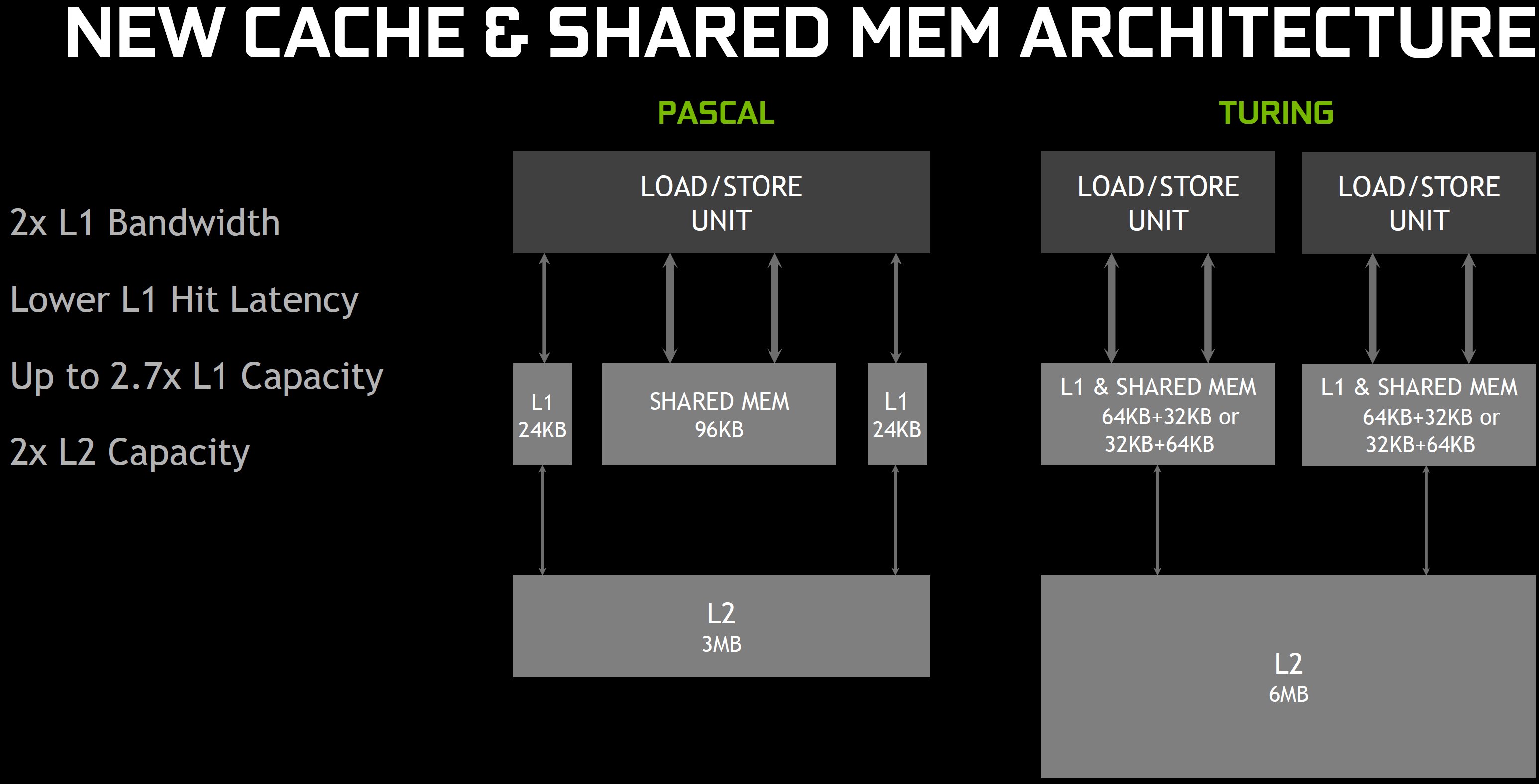
Zusammenfassend stellt Nvidia in den Raum, dass die Auswirkungen der neu gestalteten mathematischen Pipelines und Speicherarchitektur eine Leistungssteigerung von 50% pro CUDA-Kern ermöglichen! Um diese datenintensiven Kerne effektiver zu versorgen, hat Nvidia den TU104-850 mit GDDR6-Speicher gepaart und die Technologien zur Reduzierung der Datenströme (wie z.B. die Delta-Farbkompression) weiter optimiert.
Tensor-Kerne und DLSS
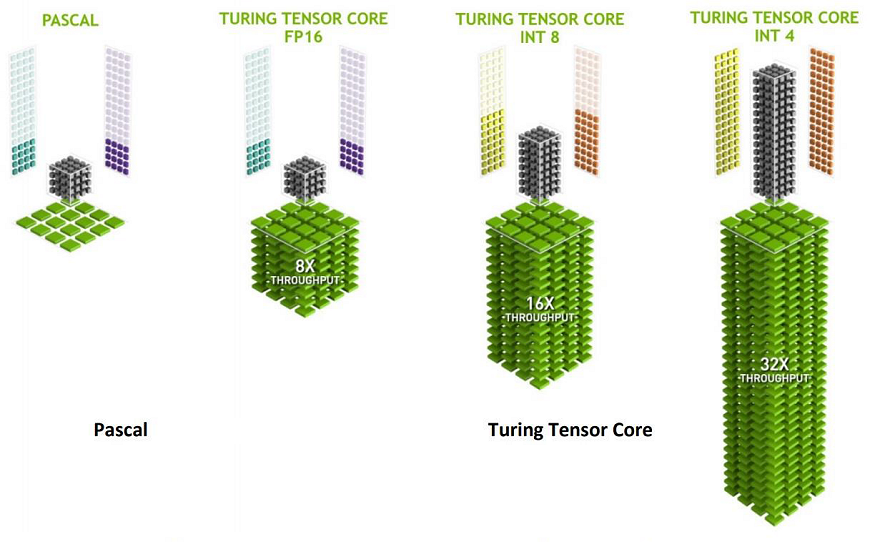
Obwohl die Volta-Architektur im Vergleich zu Pascal auch sonst voller bedeutender Änderungen steckte, war die Hinzufügung von Tensor-Kernen der wichtigste Hinweis auf den eigentlichen Zweck des GV100: die Beschleunigung von 4×4-Matrixoperationen mit FP16-Input, die die Grundlage für das Training und das Inferenzieren (Argumentation, um aus impliziten Annahmen explizite Aussagen zu machen) neuronaler Netze bilden. Wie der Volta SM besitzt Turing zwei Tensor-Kerne pro Quad oder acht pro Streaming-Multiprozessor. Durch die gezielte Ausrichtung der FP16-, INT8- und INT4-Operationen werden weniger Transistoren benötigt, als durch den Aufbau breiter Wege für hohe Präzision. Auch die Performance profitiert von dieser Neuausrichtung in ordentlichem Maße.
Diese Tensor-Kerne sind spezialisierte Ausführungseinheiten, die speziell für die Durchführung von Tensor-/Matrix-Operationen entwickelt wurden, die die zentrale Rechenfunktion im Deep Learning sind. Ähnlich wie die Volta-Tensor-Kerne, bieten die Turing-Tensor-Kerne enorme Beschleunigungen für Matrixberechnungen, die das Herzstück des zugrundeliegenden Trainings und der Inferenzoperationen neuronaler Netzwerke bilden. Turing-GPUs beinhalten eine neue Version des Tensor-Core-Designs, die für die Inferenzierung verbessert wurde. Die Turing-Tensor-Kerne fügen neue INT8- und INT4-Präzisionsmodi hinzu, um Workloads zu ermitteln.
Die meisten von Nvidias aktuellen Plänen für die Tensor-Kerne betreffen jedoch neuronale Grafiken. Der Prozess, mit dem z.B. DLSS implementiert wird, erfordert die Entwicklerunterstützung durch die NGX-API von Nvidia. NVIDIA NGX ist das neue tief lernende neuronale Grafik-Framework der NVIDIA RTX-Technologie und verwendet Deep Neural Networks (DNNs) und eine Reihe von “Neural Services”, um KI-basierte Funktionen auszuführen, die Grafiken, Rendering und andere Client-seitige Anwendungen beschleunigen und verbessern.
Zu den beschleunigten Funktionen des Turing Tensor Core gehören ultrahochwertiges NGX DLSS (Deep Learning Super-Sampling), KI InPainting (inhaltsorientiertes Image-Replacement), KI Slow-Mo (eine sehr hochwertige und flüssige Zeitlupe) und die intelligente Größenanpassung der KI Super Rez-Auflösung. Der NVIDIA OptiX AI Denoiser nutzt die Vorteile der Turing-Tensor-Cores, um es Rendern zu ermöglichen, die Bildqualität durch ein trainiertes neuronales Netzwerk intelligent zu verbessern, um Bildrauschen zu reduzieren. Dies ermöglicht es dem Renderer, ein sauberes Bild mit weniger Rendering-Samples zu erzeugen, was zu kürzeren Renderzeiten führt. Wer noch mehr dazu wissen möchte, sei auf meinen sehr ausführlichen Artikel “Nvidia GeForce RTX 2080 Ti und RTX 2080 vorgestellt – was sich hinter Turing wirklich verbirgt” zu diesem Thema verwiesen.
Ray Tracing und die RT Cores
Die Echtzeit-Strahlenverfolgung gilt ja seit langem als der Heilige Gral der Grafik und ist eine rechenintensive Rendering-Technologie, die die Beleuchtung einer Szene und ihrer Objekte realistisch simuliert. Ray Tracing wird häufig in Film, Produktdesign und Architektur mit Offline-Rendering (nicht in Echtzeit) eingesetzt. Über den Rahmen dessen hinaus, was Volta betrifft und wohl das vielversprechendste Kapitel in der ganzen Turing-Story darstellt, sind die Ray-Tracing-Kerne (RT Cores), die an der Unterseite jedes SM verankert sind.
Diese RT-Cores sind im Wesentlichen reine Beschleuniger mit fest „vorverdrahteter“ Funktion für die Auswertung von Quer- und Dreiecksschnitten der Bounding Volume Hierarchy (BVH). Beide Operationen sind für den Raytracing-Algorithmus unerlässlich. Die BVH bilden Boxen mit Geometrieinhalten in einer bestimmten Szene und helfen, die Position von Dreiecken einzugrenzen, welche die Strahlen durch eine Baumstruktur schneiden. Jedes Mal, wenn sich ein Dreieck in einer Box befindet, wird diese solange in mehrere weitere Boxen unterteilt, bis die letzte Box nicht weiter in Dreiecke unterteilt werden kann. Ohne BVHs wäre ein Algorithmus gezwungen, die gesamte Szene zu durchsuchen, indem er Tonnen von Zyklen verheizt, die jedes einzelne Dreieck auf eine mögliche Kreuzung testen.
Die 36 RT-Kerne im TU104 der Quadro RTX 4000 beschleunigen die Funktionen der BVH, sowie die Traversal- und Ray/Dreieck-Schnittpunktprüfung (Ray Casting). Die RT Cores arbeiten zusammen mit einem neuartigen Denoiser (Rauschunterdrückung), einer von NVIDIA Research entwickelten hocheffizienten BVH-Beschleunigungsstruktur und RTX-kompatiblen APIs, um das Echtzeit-Raytracing auf einer einzelnen Turing-Grafikkarte zu erreichen.
Während die RT-Cores nun für die Implementierung von Echtzeit-Reflexionen und Schatten in PC-Spielen verwendet werden, arbeitet NVIDIA auch eng mit seinen professionellen Rendering-Software-Partnern zusammen, um die Vorteile der RT Core-basierten Raytracing-Beschleunigung in die professionelle Rendering-Software einzubringen. Echtzeit-Rendering ist keine Notwendigkeit für viele Raytracing-Workloads in professionellen Anwendungen, aber RT Cores und RTX-Softwaretechnologie können den Raytracing-Vorgang sowohl für Echtzeit- als auch für Nicht-Echtzeit-Anwendungsfälle erheblich beschleunigen.
| Architecture | NVIDIA Turing TU104-850 |
| GPU Memory | 8 GB GDDR6 |
| Memory Interface | 256-bit |
| Memory Bandwidth | Up to 416 GB/s |
| NVIDIA CUDA Cores | 2,304 |
| NVIDIA Tensor Cores | 288 |
| NVIDIA RT Cores | 36 |
| Single-Precision Performance | 7.1 TFLOPS |
| Tensor Performance | 57.0 TFLOPS |
| System Interface | PCI Express 3.0 x 16 |
| Power Consumption | 125W Max. Power Limit |
| Form Factor | 4.4” H x 9.5” L, Single Slot |
| Max Simultaneous Displays | 4x 3840×2160 @ 120 Hz 4x 5120×2880 @ 60 Hz 2x 7680×4320 @ 60 Hz |
| Connectors | DP 1.4 (3x), VirOptional Stereo (1x), Quadro Sync II, VirtualLink (1x) |
| Graphics APIs | Shader Model 5.1 OpenGL 4.5 DirectX 12.0 Vulkan 1.0 |
| Compute APIs | CUDA DirectCompute OpenCL |
Testsystem und Messmethoden
Das neue Testsystem und die -methodik habe ich im Grundlagenartikel “So testen wir Grafikkarten, Stand Februar 2017” (Englisch: “How We Test Graphics Cards“) bereits sehr ausführlich beschrieben und verweise deshalb der Einfachheit halber jetzt nur noch auf diese detaillierte Schilderung. Wer also alles noch einmal ganz genau nachlesen möchte, ist dazu gern eingeladen. jedoch ist in diesem Fall die Hardware der Workstation eine komplett andere.

Interessierten bietet die Zusammenfassung in Tabellenform schnell noch einen kurzen Überblick:
| Testsysteme und Messräume | |
|---|---|
| Hardware: |
Intel Core i9-7980XE Aorus X299 Master 32 GB (4x 8) Patriot Viper DDR4 3800 1x 1 TB Patriot Viper NVMe SSD 1x 14 TB Seagate Ironwolf (Storage) Be Quiet Dark Power Pro 11 2x 1 TB Seagate Fast SSD (Data Exchange, Portable Software) |
| Kühlung: |
Alphacool Eisblock XPX 8x Be Quiet! Silent Wings 3 PWM 2x 480er Radiator von Alphacool |
| Gehäuse: |
Open Benchtable, Closed Case |
| Monitor: | Eizo EV3237-BK |
| Leistungsaufnahme: |
berührungslose Gleichstrommessung am PCIe-Slot (Riser-Card) berührungslose Gleichstrommessung an der externen PCIe-Stromversorgung direkte Spannungsmessung an den jeweiligen Zuführungen und am Netzteil 2x Rohde & Schwarz HMO 3054, 500 MHz Mehrkanal-Oszillograph mit Speicherfunktion 4x Rohde & Schwarz HZO50, Stromzangenadapter (1 mA bis 30 A, 100 KHz, DC) 4x Rohde & Schwarz HZ355, Tastteiler (10:1, 500 MHz) 1x Rohde & Schwarz HMC 8012, Digitalmultimeter mit Speicherfunktion |
| Thermografie: |
Optris PI640, Infrarotkamera PI Connect Auswertungssoftware mit Profilen |
| Akustik: |
NTI Audio M2211 (mit Kalibrierungsdatei) Steinberg UR12 (mit Phantomspeisung für die Mikrofone) Creative X7, Smaart v.7 eigener reflexionsarmer Messraum, 3,5 x 1,8 x 2,2 m (LxTxH) Axialmessungen, lotrecht zur Mitte der Schallquelle(n), Messabstand 50 cm Geräuschentwicklung in dBA (Slow) als RTA-Messung Frequenzspektrum als Grafik |
| Betriebssystem | Windows 10 Pro (aktueller Build, alle Updates) |
- 1 - Einführung und Datenblatt
- 2 - Tear Down: Platine und Kühler im Detail
- 3 - Visualize 2019, Arion, Luxmark
- 4 - Solidworks 2017
- 5 - Autodesk AutoCAD 2018 , Maya 2017 und 3ds Max 2015
- 6 - Creo 3 (M190)
- 7 - SPECviewperf 13
- 8 - GDI und Treiberdurchsatz
- 9 - Leistungsaufnahme, Lastspitzen und Netzteilempfehlung
- 10 - Takt und Temperaturen
- 11 - Lüfter und Lautstärke
- 12 - Zusammenfassung und Fazit

















Kommentieren