












I don't want to spoil the end result at the beginning, but if you first benchmark the predecessor Quadro P4000 as a direct comparison, only to then have to reach unplanned but curiously on the shelf and also to flatten a Quadro P5000 with it gallantly, then pinch two times in the forearm. Especially since you can get this smallest RTX-Quadro for less than 900 euros and it is still cheaper than a Radeon Pro WX 8200, which is also significantly… No, I don't tell you anything anymore, because only reading yourself makes you smarter.
Today's test includes the Nvidia Quadro RTX 4000 and similarly rated cards such as the Quadro P4000 and P5000, as well as the AMD Radeon Pro WX 8200, the Radeon Vega Frontier Edition (FE) and the Radeon VII. I included the latter in the test because it is an interesting map and the press release from AMD's PR agency stated that the new all-in-one driver would continue to support The Radeon VII in professional applications in the future. That this was not quite so yet, at least this test proves and I will observe it when the driver comes soon for the Q2.

The Quadro RTX 4000
The card, which weighs only 480 grams, measures 24.4 cm in length from the outer edge of the slot panel to the end of the radiator cover and is only 10.5 cm high between the top edge of the PCIe slot and the top of the cooler. With a thickness of 1.4 cm, it is also a real single-slot card. You can't find RGB building. The radiator cover is a mix of matt black cast aluminum and a metallic cover plate.




The 8-pin power supply connection at the back is oversized, because for the maximum 125 watts, for which this card is designed by firmware, a 6-pin connection would have been easy. Unless you also use the board for a larger card, because the chip allows this. But more on that.

On the slot aperture you will find three DisplayPort 1.4 as well as a VirtualLink.

At the top of the card there are the sockets for VirOptional Stereo and Quadro Sync II.

The technical substructure of the Quadro RTX 4000
The Quadro RTX 4000 is currently the smallest of the Quadro RTX cards and it remains to be seen if and when e.g. on the basis of the TU106 and TU116 even smaller cards as Quadro with and without RTX. The Quadro RTX 4000 relies on the same TU104 as the GeForce RTX 2080, but was steded together by hardware strap on the technical data of the TU106 of a GeForce RTX 2070 and additionally has a significantly lower, maximum power limit of only 125 watts.
The card therefore does not use a fully developed TU106 GPU, which also consists of three GPCs with six TPCs each and which would have been obvious, but a significantly slimmed down, much larger TU104 with the same basic data as the TU106. This is something that is somewhat surprising. However, the rest of the specs are automatically generated, because of course the TPCs each contain two SMs, so this results in 36 SMs for the entire processor, which is designated as TU104-850.


These blocks remain unchanged between turing GPUs, so the Quadro RTX 4000 is equipped with 2304 CUDA cores, 288 tensor cores, 36 RT cores and 144 texture units, making it 1:1 equivalent to the GeForce RTX 2070, although it is based on the larger chip. The TU104-850 retains the same 256-bit memory bus and is also equipped with 8GB and 14Gb/s GDDR6 modules, which can shovel up to 416GB/s due to the lower 1625 MHz memory cycle. The 4 MB L2 cache and 64 ROPs are also applied.
The Quadro RTX 4000 is a successful attempt to integrate tensor and RT cores as deep as possible into the chip, so that these functions remain available despite downscaling. It will be very interesting to see how functional it can be in almost halved quantities compared to the larger RTX models in Zukunst. The only capability that the TU104-850 is blatantly lacking is NVLink. This is a pity, but due to the possible cannibalization of the next higher (and also more expensive) cards quite intentional.
Turing and possible performance improvement in traditional applications
The fact is that Turing-based cards do not have dramatically higher CUDA core numbers than their previous generations and also do not have quite as high boost clock rates. But the company has made some effort to design Turing for better performance per core. First, Turing leans pretty much on the Volta playbook to support simultaneous execution of FP32 and INT32 operations. If one assumes that the Turing cores can achieve a better performance at a certain clock frequency than Pascal, then also and above all this special ability explains to a large extent why this is really so.
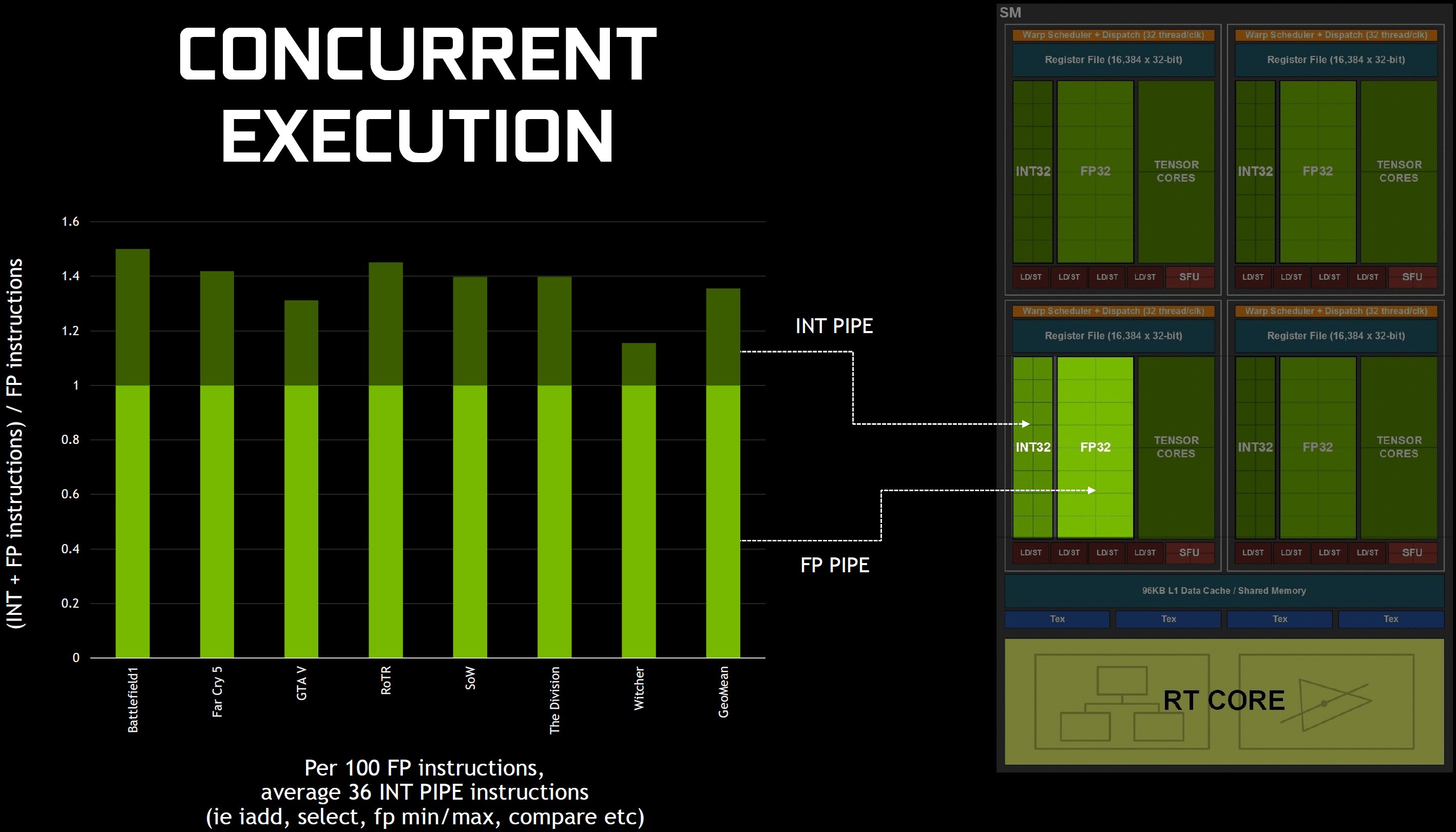
But what exactly is at stake? In previous generations, a single mathematical data path meant that unequal command types could not be executed at the same time, so that the floating-point pipeline stopped when, for example, non-FP operations were required in a shader program. In Volta's case, they eventually tried to change this by creating separate pipelines. Although Nvidia eliminated the second disposition unit associated with each warp scheduler, the once problematic throughput of the instructions increased. Turing now takes a similar approach by providing one warp scheduler and disposition unit per quad (four per SM) while giving instructions for the INT32 and FP32 pipelines at the same time.
Despite the separation of FP32 and INT32 paths in the block diagrams, Nvidia writes in the technical explanations that each Turing SM contains 64 CUDA cores to keep things as simple as possible. The Turing SM also includes 16 load/storage units, 16 special function units, 256 KB register file storage, 96 KB shared memory and L1 data cache, four texture units, eight tensor cores, and an RT core.
This increase in on-die memory plays another, very critical role in improving performance, as does the hierarchical organization. As with the GP102 and GP104, the TU104's streaming multiprocessors are divided into four blocks. But while the Pascal-based GPUs 24 KB L1 data and texture cache scan between each pair of blocks and 96 KB of shared memory share over the SM, the TU104 unifies these units in a flexible 96 KB structure.
The advantage of unification is that whether a workload is optimized for L1 or shared memory, on-chip memory is used instead of remaining idle as before. Moving the L1 functionality down has the added benefit of placing it on a wider bus, doubling the L1 cache bandwidth (while keeping the shared memory bandwidth unchanged).
Compared from TPC to TPC (i.e. with the same number of CUDA cores) pascal 64B/clock cache supports hits per TPC, Turing supports 128B/clock cache hits, i.e. here, too, the performance is twice as high. And because these 96 KB can be freely configured as 64 KB L1 and 32 KB of shared memory (or vice versa), the L1 capacity per SM can also be 50% higher. By the way, Turing's cache structure looks very similar at first glance to Kepler, where one had a configurable 64 KB Shared Memory/L1 cache.
To explain, there are three different datastores – the texture cache for textures, the L1 cache for generic LD/ST data, and shared memory for calculation. In the Kepler generation, the texture was separate (the read-only data cache), while L1 and Shared were combined. In Maxwell and Pascal there were also two separate structures, only slightly modified. Now all three are combined into a common and configurable storage pool.
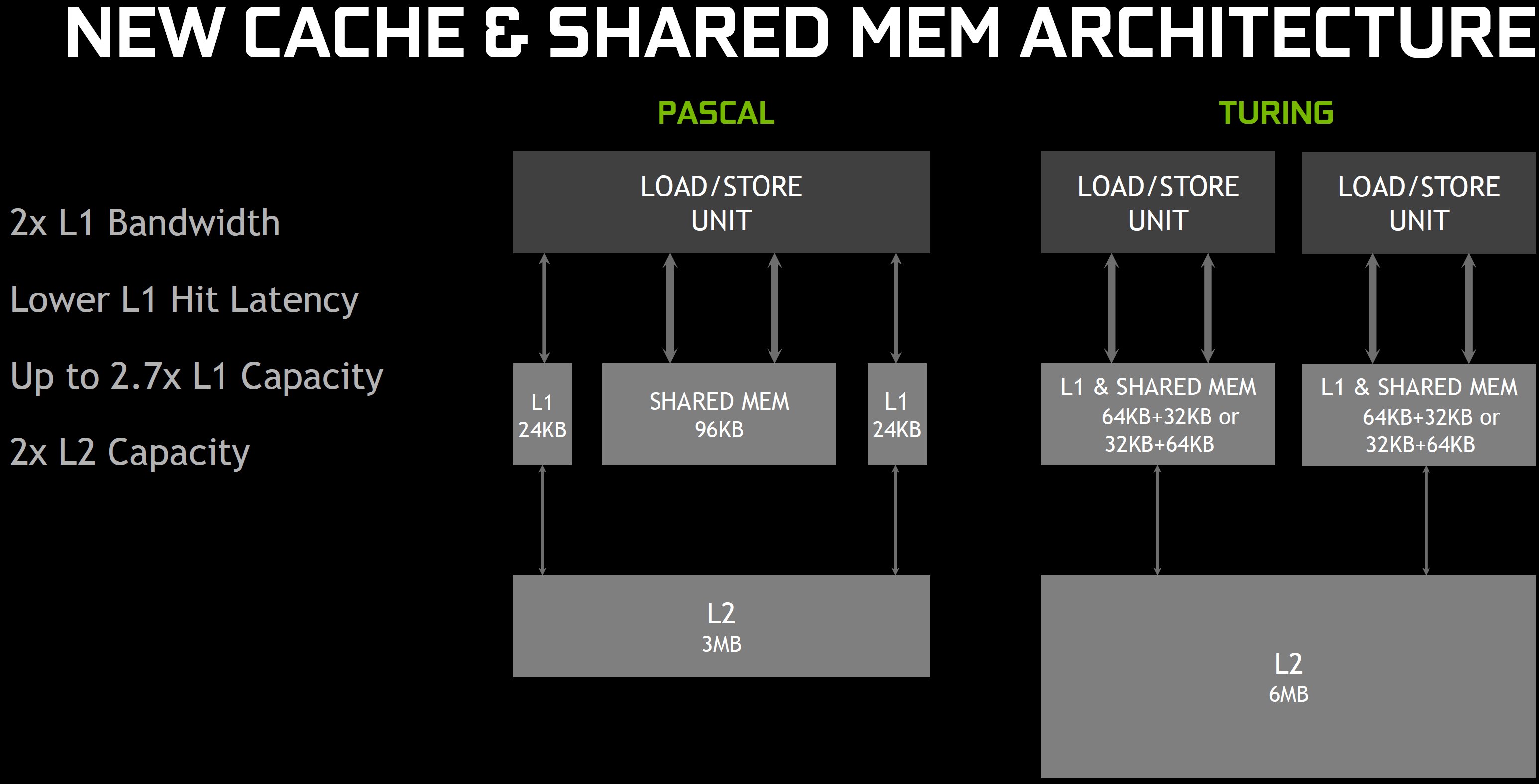
In summary, Nvidia suggests that the impact of the redesigned mathematical pipelines and storage architecture will increase performance by 50% per CUDA core! To more effectively power these data-intensive cores, Nvidia has paired the TU104-850 with GDDR6 memory and developed the technologies to reduce data flows (such as delta color compression).
Tensor cores and DLSS
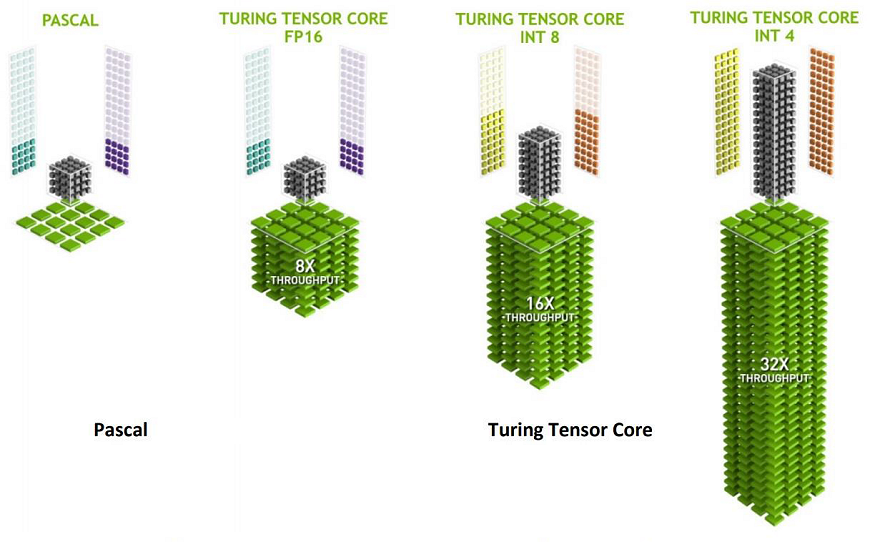
Although the Volta architecture was otherwise full of significant changes compared to Pascal, the addition of tensor cores was the most important indication of the actual purpose of the GV100: the acceleration of 4×4 matrix operations with FP16 input, which The basis for training and inference (reasoning to make explicit statements from implicit assumptions) form neural networks. Like the Volta SM, Turing has two tensor cores per quad or eight per streaming multiprocessor. The targeted targeting of FP16, INT8, and INT4 operations requires fewer transistors than building wide pathways for high precision. Performance also benefits from this realignment to a fair extent.
These tensor cores are specialized execution units specifically designed to perform tensor/matrix operations that are the central computing function in deep learning. Similar to the Volta Tensor cores, the Turing Tensor cores provide enormous accelerations for matrix calculations, which are at the heart of the underlying training and inference operations of neural networks. Turing GPUs include a new version of the Tensor Core design that has been improved for inference. The Turing Tensor cores add new INT8 and INT4 precision modes to determine workloads.
However, most of Nvidia's current plans for the tensor cores concern neural graphics. The process by which, for example, DLSS requires developer support from Nvidia's NGX API. NVIDIA NGX is the new deep-learning neural graphics framework of NVIDIA RTX technology and uses Deep Neural Networks (DNNs) and a number of Neural Services to perform AI-based functions that support graphics, rendering, and other client-side applications accelerate and improve.
The accelerated features of the Turing Tensor Core include ultra-high-quality NGX DLSS (Deep Learning Super-Sampling), KI InPainting (content-oriented image replacement), KI Slow-Mo (a very high-quality and fluid slow motion) and the intelligent Resizing the AI Super Rez resolution. The NVIDIA OptiX AI Denoiser takes advantage of Turing Tensor cores to enable rendering to intelligently improve image quality through a trained neural network to reduce image noise. This allows the renderer to create a clean image with fewer rendering samples, resulting in shorter rendering times. If you want to know more, refer to my very detailed article "Nvidia GeForce RTX 2080 Ti and RTX 2080 – what is really hidden behind Turing" on this topic.
Ray Tracing and the RT Cores
Real-time radiation tracking has long been considered the Holy Grail of graphics and is a computationally-intensive rendering technology that realistically simulates the illumination of a scene and its objects. Ray tracing is commonly used in film, product design, and architecture with offline rendering (not in real time). Beyond the scope of What Volta is about, and arguably the most promising chapter in the entire Turing story, are the Ray Tracing Cores (RT Cores) anchored to the bottom of each SM.
These RT cores are essentially pure accelerators with a fixed "pre-wired" function for the evaluation of cross and triangle sections of the Bounding Volume Hierarchy (BVH). Both operations are essential for the ray tracing algorithm. The BVH form boxes with geometry contents in a specific scene and help to narrow the position of triangles that cut the rays through a tree structure. Each time a triangle is in a box, it is divided into several more boxes until the last box can no longer be divided into triangles. Without BVHs, an algorithm would be forced to search the entire scene by burning tons of cycles that test each triangle for a possible crossing.
The 36 RT cores in the TU104 of the Quadro RTX 4000 accelerate the functions of bvH, as well as the traversal and ray/triangle intersection test (ray casting). The RT Cores work with a novel denoiser (noise reduction), a highly efficient BVH acceleration structure developed by NVIDIA Research, and RTX-compatible APIs to achieve real-time raytracing on a single Turing graphics card. Reach.
While the RT cores are now used to implement real-time reflections and shadows in PC games, NVIDIA is also working closely with its professional rendering software partners to take advantage of RT Core-based Raytracing acceleration into the professional rendering software. Real-time rendering is not a necessity for many ray tracing workloads in professional applications, but RT Cores and RTX software technology can significantly speed up the ray tracing process for both real-time and non-real-time use cases .
| Architecture | NVIDIA Turing TU104-850 |
| GPU Memory | 8 GB GDDR6 |
| Memory Interface | 256-bit |
| Memory Bandwidth | Up to 416 GB/s |
| NVIDIA CUDA Cores | 2,304 |
| NVIDIA Tensor Cores | 288 |
| NVIDIA RT Cores | 36 |
| Single-Precision Performance | 7.1 TFLOPS |
| Tensor Performance | 57.0 TFLOPS |
| System Interface | PCI Express 3.0 x 16 |
| Power Consumption | 125W Max. Power Limit |
| Form Factor | 4.4" H x 9.5" L, Single Slot |
| Max Simultaneous Displays | 4x 3840×2160 x 120 Hz 4x 5120×2880 x 60 Hz 2x 7680×4320 x 60 Hz |
| Connectors | DP 1.4 (3x), VirOptional Stereo (1x), Quadro Sync II, VirtualLink (1x) |
| Graphics APIs | Shader Model 5.1 OpenGL 4.5 DirectX 12.0 Volcano 1.0 |
| Compute APIs | Cuda DirectCompute Opencl |
Test system and measurement methods
I have already described the new test system and the methodology in the basic article "How we test graphics cards, as of February 2017" (English: "How We Test Graphics Cards") in great detail and therefore, for the sake of simplicity, now only refers to this detailed Description. So if you want to read everything again, you are welcome to do so. however, in this case, the hardware of the workstation is completely different.

If you are interested, the summary in table form quickly provides a brief overview:
| Test systems and measuring rooms | |
|---|---|
| Hardware: |
Intel Core i9-7980XE Aorus X299 Master 32 GB (4x 8) Patriot Viper DDR4 3800 1x 1 TB Patriot Viper NVMe SSD 1x 14 TB Seagate Ironwolf (Storage) Be Quiet Dark Power Pro 11 2x 1 TB Seagate Fast SSD (Data Exchange, Portable Software) |
| Cooling: |
Alphacool Ice Block XPX 8x Be Quiet! Silent Wings 3 PWM 2x 480 radiator by Alphacool |
| Housing: |
Open Benchtable, Closed Case |
| Monitor: | Eizo EV3237-BK |
| Power consumption: |
non-contact DC measurement on the PCIe slot (Riser-Card) non-contact DC measurement on the external PCIe power supply Direct voltage measurement on the respective feeders and on the power supply 2x Rohde & Schwarz HMO 3054, 500 MHz multi-channel oscillograph with memory function 4x Rohde & Schwarz HZO50, current togor adapter (1 mA to 30 A, 100 KHz, DC) 4x Rohde & Schwarz HZ355, touch divider (10:1, 500 MHz) 1x Rohde & Schwarz HMC 8012, digital multimeter with storage function |
| Thermography: |
Optris PI640, infrared camera PI Connect evaluation software with profiles |
| Acoustics: |
NTI Audio M2211 (with calibration file) Steinberg UR12 (with phantom power for the microphones) Creative X7, Smaart v.7 own low-reflection measuring room, 3.5 x 1.8 x 2.2 m (LxTxH) Axial measurements, perpendicular to the center of the sound source(s), measuring distance 50 cm Noise in dBA (Slow) as RTA measurement Frequency spectrum as a graph |
| Operating system | Windows 10 Pro (current build, all updates) |
- 1 - Einführung und Datenblatt
- 2 - Tear Down: Platine und Kühler im Detail
- 3 - Visualize 2019, Arion, Luxmark
- 4 - Solidworks 2017
- 5 - Autodesk AutoCAD 2018 , Maya 2017 und 3ds Max 2015
- 6 - Creo 3 (M190)
- 7 - SPECviewperf 13
- 8 - GDI und Treiberdurchsatz
- 9 - Leistungsaufnahme, Lastspitzen und Netzteilempfehlung
- 10 - Takt und Temperaturen
- 11 - Lüfter und Lautstärke
- 12 - Zusammenfassung und Fazit

















Kommentieren