













Turing und mögliche Leistungsverbesserung in den bestehenden Spielen
Es gibt indes nicht wenige Skeptiker, die, basierend auf diversen Leaks, bereits ihre Bedenken dahingehend geäußert haben, dass Turing-basierte Karten ja nicht dramatisch höhere CUDA-Kernzahlen aufweisen als ihre Vorgängergenerationen und zudem auch nicht ganz so hohe Boost-Taktraten besitzen. Ganz so falsch lagen sie auf den ersten Blick damit dann ja auch gar nicht.
Leider gab sich Nvidia außerdem beim Auftaktevent zur Gamescom in Köln diesbezüglich etwas schmallippig und ging auch im Verlauf der Präsentation nicht weiter auf die Generationsverbesserungen in Bezug auf die aktuellen Spiele ein. Aber das Unternehmen hat sich durchaus einige Mühe gegeben, Turing für eine bessere Leistung pro Kern zu konstruieren. Allerdings ist diese Art der Kommunikation eben auch nicht geeignet, sinnlosen Spekulationen den Wind aus den Segeln zu nehmen.
Holen wir das Ganze nun einfach mal nach und werfen mal einen genaueren Blick auf die Details. Zunächst lehnt sich Turing so ziemlich genau an das Volta-Playbook an, um die gleichzeitige Ausführung von FP32- und INT32-Operationen zu unterstützen. Wenn man nun davon ausgeht, dass die Turing-Kerne bei einer bestimmten Taktfrequenz eine bessere Leistung erzielen können als Pascal, dann erklärt auch und vor allem diese spezielle Fähigkeit weitgehend, warum das wirklich so ist.
Doch um was geht es genau? In früheren Generationen bedeutete ein einziger mathematischer Datenpfad, dass ungleiche Befehlsarten nicht gleichzeitig ausgeführt werden konnten, so dass die Fließkomma-Pipeline stillstand, wenn z.B. in einem Shader-Programm Nicht-FP-Operationen benötigt wurden. Bei Volta versuchte man schließlich dies zu ändern, indem man getrennte Pipelines schuf.
Obwohl Nvidia die zweite Dispositionseinheit, die jedem Warp-Scheduler zugeordnet war, eliminierte, stieg der einst problematische Durchsatz der Instruktionen. Turing verfolgt nun einen ähnlichen Ansatz, indem es eine Warp-Scheduler- und Dispositionseinheit pro Quad (vier pro SM) gibt und man gleichzeitig Anweisungen für die INT32- und FP32-Pipeline erteilen kann.
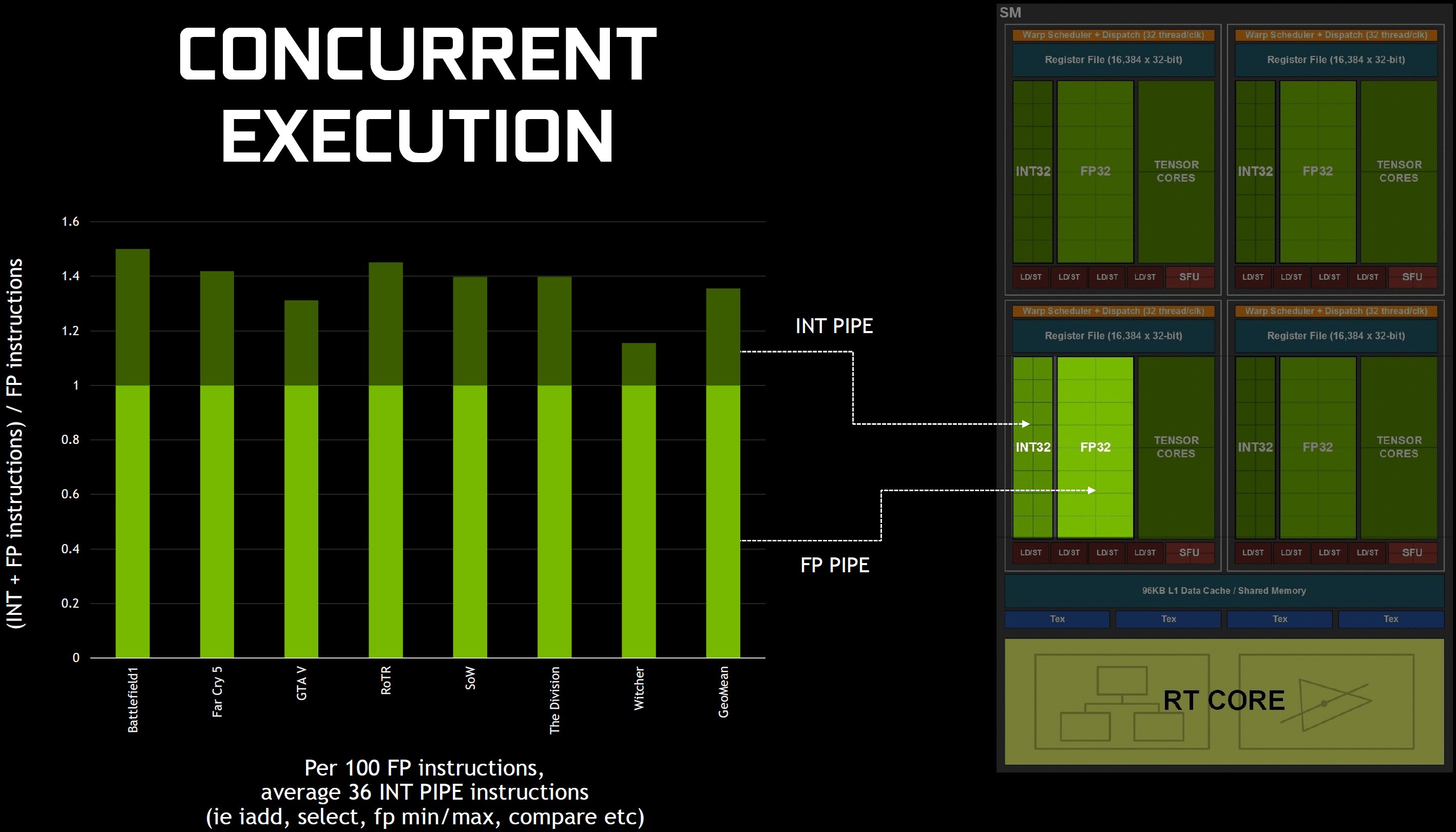
Laut Nvidia sind die potenziellen Gewinne signifikant. In einem Spiel wie Battlefield 1 gibt es auf 100 Gleitkomma-Anweisungen z.B. 50 Nicht-FP-Anweisungen im Shader-Code. Andere Titel tendieren noch stärker zur Gleitkomma-Mathematik. Aber Nvidia meint auch, dass es durchschnittlich 36 ganzzahlige Pipeline-Anweisungen gibt, die die Fließkomma-Pipeline für jeweils 100 FP-Anweisungen blockieren würden. Diese werden nun auf die INT32-Cores entladen. Zumindest in der Theorie.
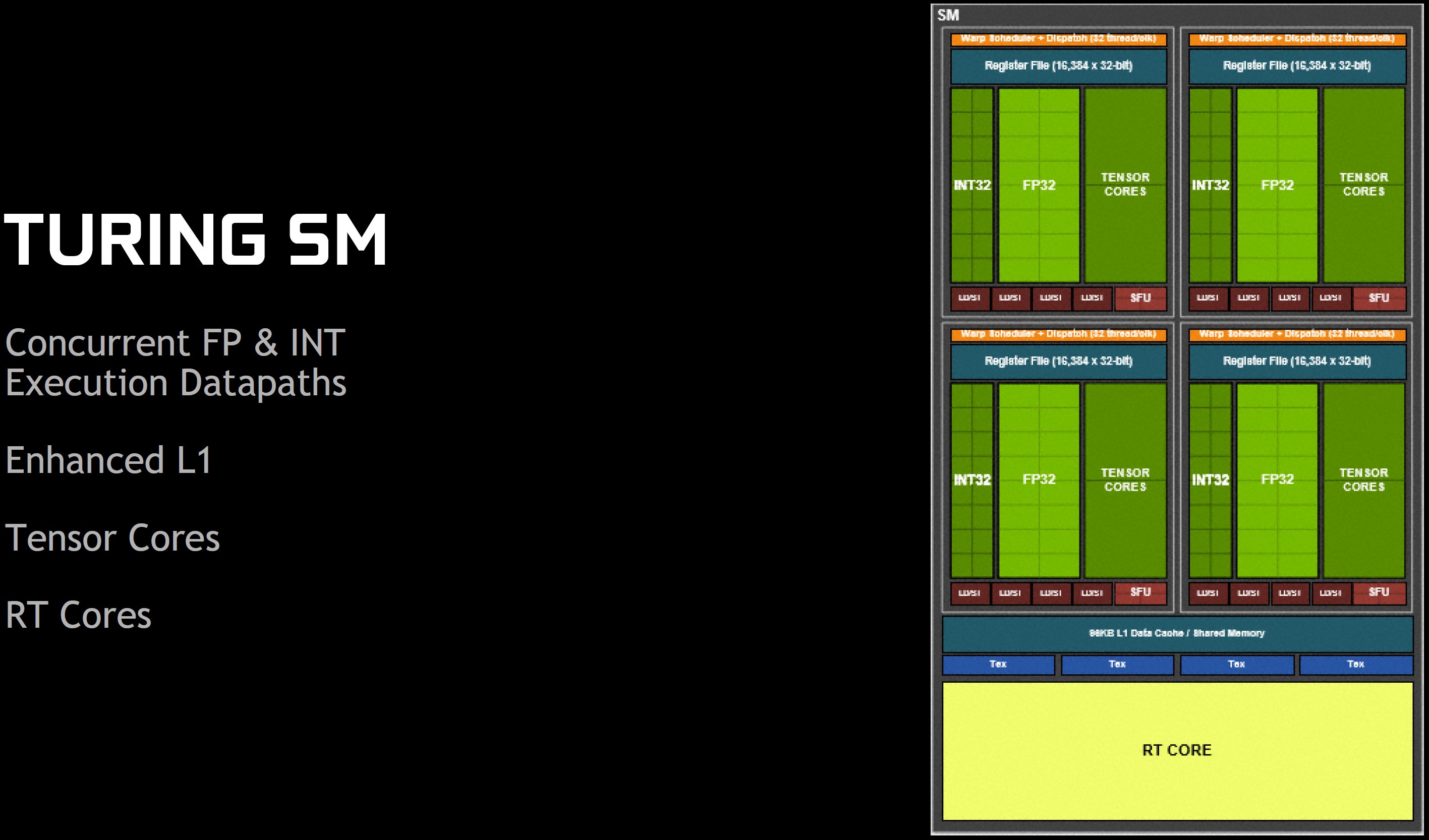
Trotz der Trennung von FP32- und INT32-Pfaden in den Blockdiagrammen, schreibt Nvidia in den technischen Erklärungen, dass jeder Turing SM 64 CUDA-Cores enthält, um die Dinge möglichst einfach zu halten. Der Turing SM umfasst zudem noch 16 Lade-/Speichereinheiten, 16 Spezialfunktionseinheiten, 256KB Registerdateispeicher, 96KB Shared Memory und L1 Data Cache, vier Textureinheiten, acht Tensor-Kerne sowie einen RT-Kern.
Auf dem Papier erscheint ein SM beim Pascal-Vorgänger GP102 komplexer und bietet doppelt so viele CUDA-Cores, Lade-/Speichereinheiten, SFUs, Textureinheiten, genauso viel Kapazität für Registerdateien und sogar mehr Cache. Aber man muss auch berücksichtigen, dass der TU102 über bis zu 72 SMs verfügt, während der GP102 mit 30 SMs auskommen muss. Das Ergebnis ist ein Turing-basiertes Flaggschiff mit 21% mehr CUDA-Cores und Textureinheiten als die GeForce GTX 1080 Ti, aber auch viel mehr SRAM für Register, Shared Memory und L1-Cache, ganz zu schweigen von 6 MB L2-Cache, der die 3 MB des GP102 sogar verdoppelt.
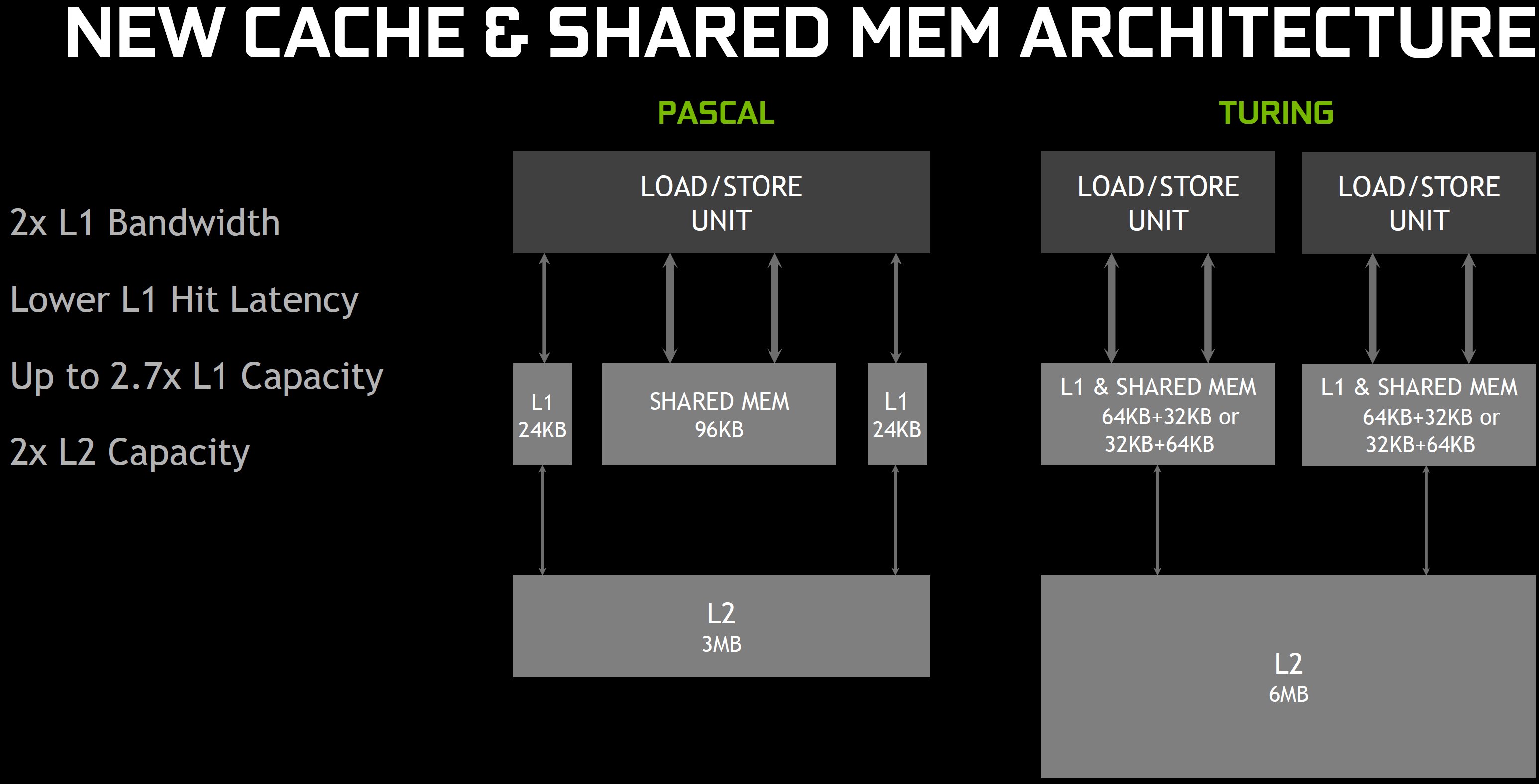
Diese Erhöhung des On-Die-Speichers spielt eine weitere, sehr entscheidende Rolle bei der Leistungssteigerung, ebenso wie die hierarchische Organisation. Wie beim GP102 und GP104 sind auch die Streaming Multiprozessoren des TU102 in vier Blöcke unterteilt. Aber während sich die Pascal-basierten GPUs einen 24KB L1 Daten- und Textur-Cache zwischen jedem Blockpaar und 96KB gemeinsamem Speicher über die SM teilen, vereinheitlicht TU102 diese Einheiten in einer flexiblen 96KB-Struktur.
Der Vorteil der Vereinheitlichung besteht darin, dass unabhängig davon, ob ein Workload für L1 oder Shared Memory optimiert ist, On-Chip-Speicher genutzt wird, anstatt wie bisher untätig zu bleiben. Das Verschieben der L1-Funktionalität nach unten hat den zusätzlichen Vorteil, dass sie auf einen breiteren Bus gelegt wird, wodurch die L1-Cache-Bandbreite verdoppelt wird (während die Bandbreite des gemeinsamen Speichers unverändert bleibt).
Im Vergleich von TPC zu TPC (d.h. bei gleicher Anzahl von CUDA-Cores) unterstützt Pascal 64B/Takt-Cache Hits pro TPC, Turing unterstützt 128B/Takt-Cache Hits, d.h. auch hier liegt die Leistung 2x höher. Und da diese 96KB als 64KB L1 und 32KB Shared Memory (oder umgekehrt) frei konfiguriert werden können, kann die L1-Kapazität pro SM ebenfalls um 50% höher sein. Übrigens sieht Turings Cachestruktur auf den ersten Blick sehr ähnlich aus wie Kepler, wo man über einen konfigurierbaren 64KB Shared Memory/L1-Cache verfügte.
Zur Erklärung: es gibt drei verschiedene Datenspeicher – den Textur-Cache für Texturen, den L1-Cache für generische LD/ST-Daten und Shared Memory für die Berechnung. In der Kepler-Generation war die Textur getrennt (der schreibgeschützte Daten-Cache), während L1 und Shared kombiniert wurden. In Maxwell und Pascal hatte man auch noch zwei getrennte Strukturen, nur etwas modifiziert. Nun werden alle drei zu einem gemeinsamen und konfigurierbaren Speicherpool zusammengefasst.
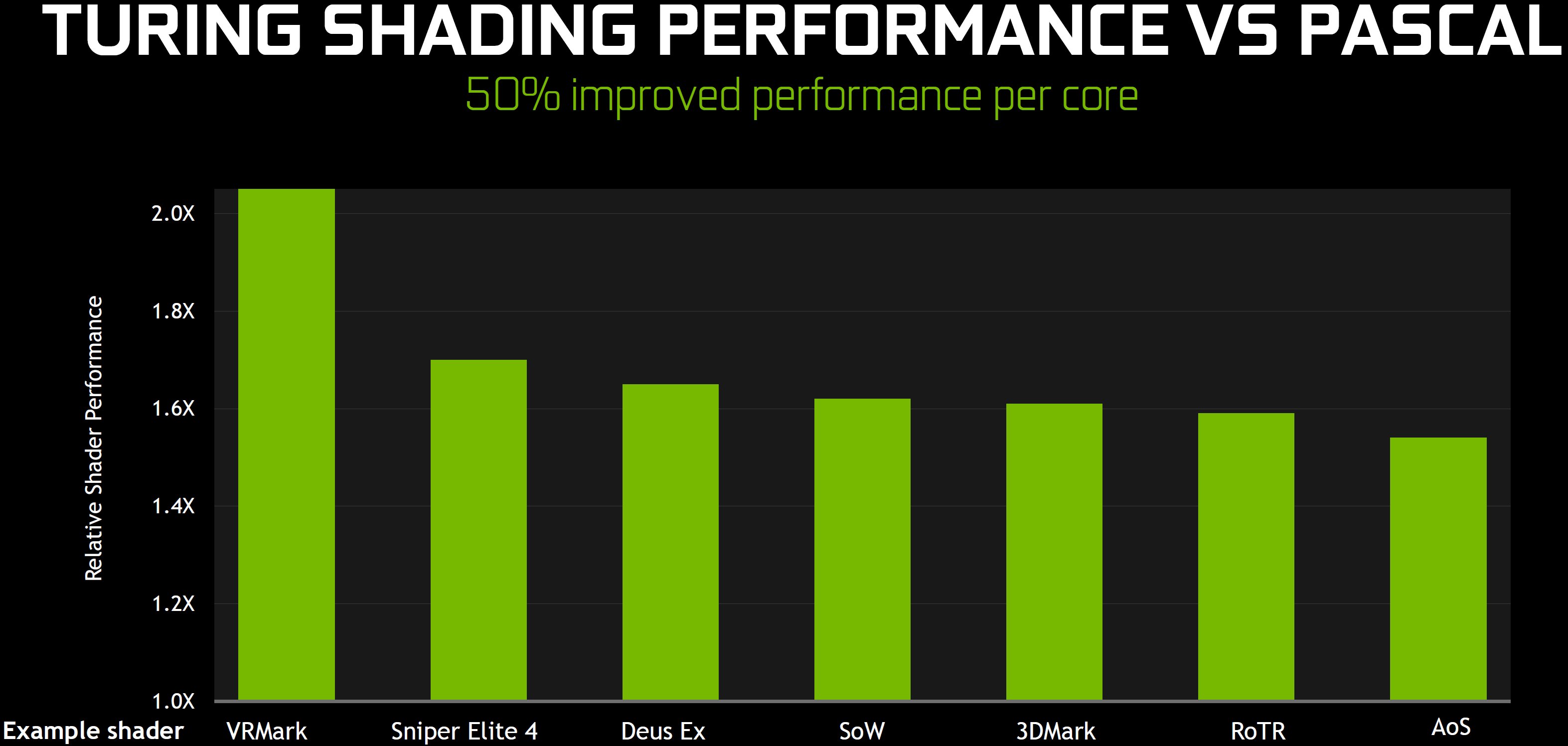
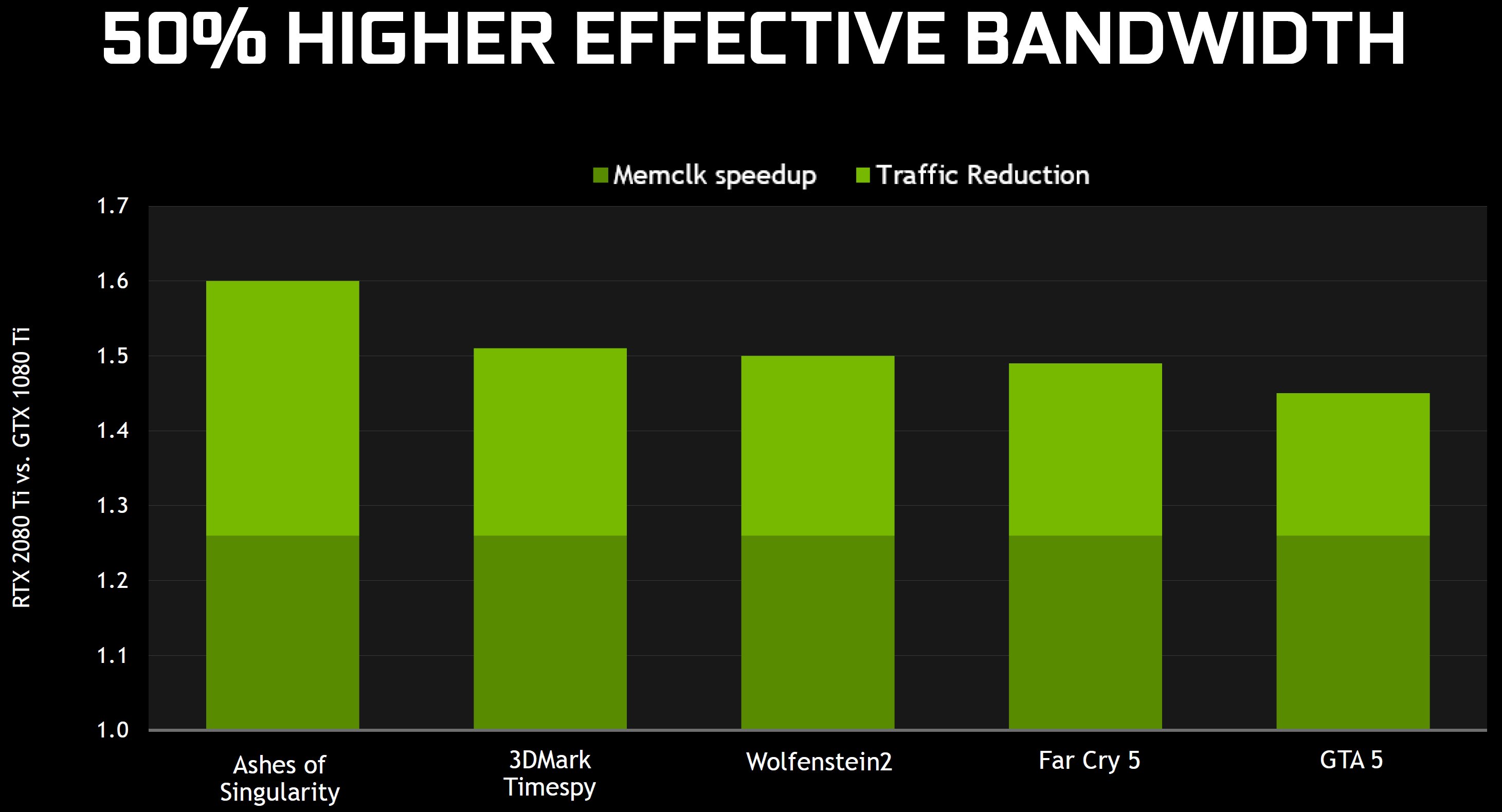
Zusammenfassend stellt Nvidia in den Raum, dass die Auswirkungen der neu gestalteten mathematischen Pipelines und Speicherarchitektur eine Leistungssteigerung von 50% pro CUDA-Kern ermöglichen! Um diese datenintensiven Kerne effektiver zu versorgen, hat Nvidia den TU102 mit GDDR6-Speicher gepaart und die Technologien zur Reduzierung der Datenströme (wie z.B. die Delta-Farbkompression) weiter optimiert.
Wenn man die 11 Gb/s GDDR5X-Module der GeForce GTX 1080 Ti mit dem 14 Gb/s GDDR6-Speicher der GeForce RTX 2080 Ti vergleicht, die beide auf einen aggregierten 352-Bit-Bus zugreifen können, dann ergibt sich eine um 27% höhere Datenrate und Spitzenbandbreite auf der gesamten Karte. Je nach Spiel, und vor allem dann, wenn die GeForce RTX 2080 Ti das Senden von Daten über den Bus reduzieren kann, steigt der effektive Durchsatz dann noch mehr um zweistellige Prozentsätze.
- 1 - Einführung und Vorstellung
- 2 - TU102 + GeForce RTX 2080 Ti
- 3 - TU104 + GeForce RTX 2080
- 4 - TU106 + GeForce RTX 2070
- 5 - Performance-Anstieg für bestehende Anwendungen
- 6 - Tensor-Kerne und DLSS
- 7 - Ray Tracing in Echtzeit
- 8 - NVLink: als Brücke wohin?
- 9 - RTX-OPs: wir rechnen nach
- 10 - Shading-Verbesserungen
- 11 - Anschlüsse und Video
- 12 - 1-Klick-Übertaktung
- 13 - Tschüss, Gebläselüfter!
- 14 - Zusammenfassung und Fazit

















Kommentieren