













Testsystem und Testvorbereitung
Zur Überprüfung der theoretischen Angaben aus den Specs nutze ich die üblichen Verdächtigen wie den CrystalDiskMark und Atto. Es handelt sich durch vorangegangene Workstation-Tests nicht mehr um ganz ladenneue SSDs, sondern um Alltags-Ware, die zudem schon mal ordentlich runtergerödelt wurde. Schauen wir mal, was nach der Abnutzung von der Theorie im Alltag so übrigbleibt. Die zu testenden SSDs befinden sich im ersten PCIe 5.0 NVMe-Slot des Motherboards und werden nicht als Systemplatte genutzt.
Dazu nutze ich noch AJA als Alltagstest, um das Encodieren größerer Ultra-HD Video-Streams zu simulieren und den Storage-Test des SPECwpc, der jede Menge echter Anwendungen beinhaltet und man darf gespannt sein, was dort bei den großen Workloads noch an Performance übrig bleibt. Allerdings pickte ich mir hier exemplarisch die Applikationen mit den größten Unterschieden und Lasten heraus. Die einzelnen Komponenten des Testsystems habe ich auch noch einmal tabellarisch zusammengefasst:
| Test System and Equipment |
|
|---|---|
| Hardware: |
AMD Ryzen 9 7950X |
| Cooling: |
Alphacool Eisblock XPX Pro Alphacool Eiswolf (modified) |
| Case: |
Raijintek Paean |
| Monitor: | BenQ PD3220U |
| Thermal Imager: |
1x Optris PI640 + 2x Xi400 Thermal Imagers Pix Connect Software Type K Class 1 thermal sensors (up to 4 channels) |
| OS: | Windows 11 Pro (all updates, current certified drivers) |
Sequentielle Leistung der gebrauchten SSDs
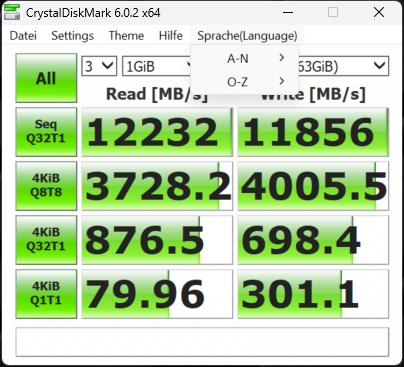
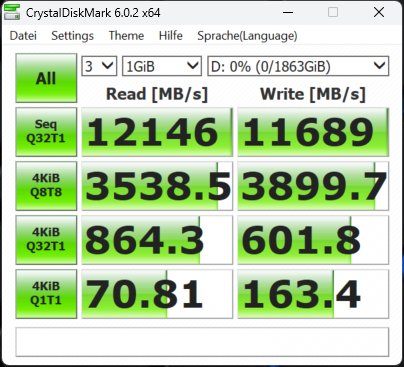
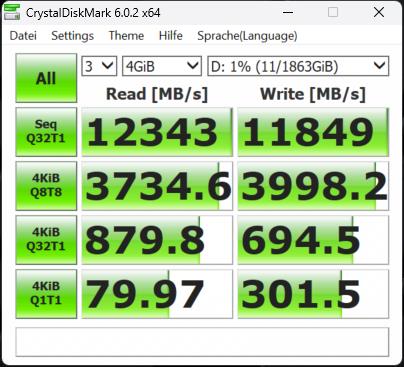
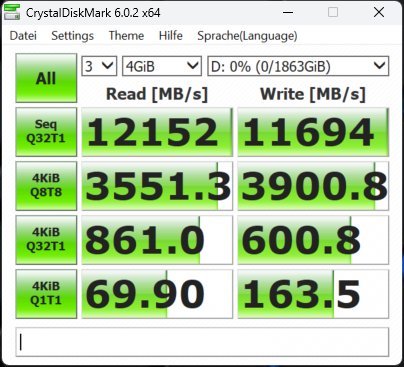
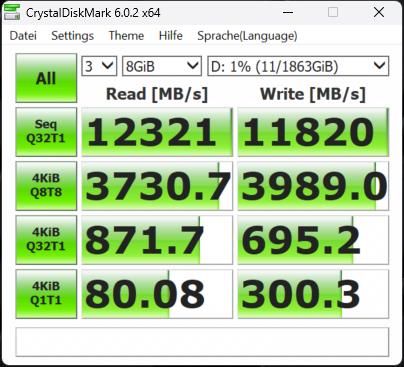
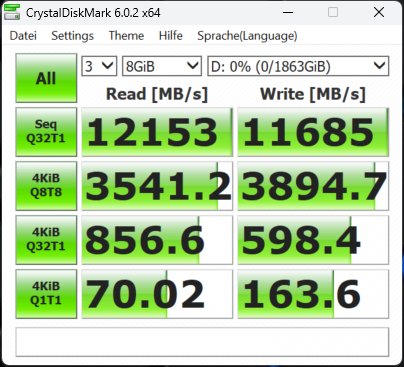
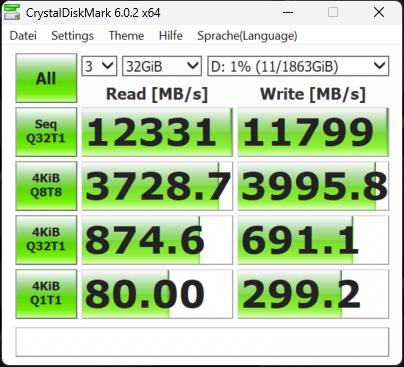
Die Synthetics sind eine gute Möglichkeit, die großen Zahlen einmal so richtig auszufahren. Wie gut das dann in der Realität bei den echten Anwendungsbenchmarks funktioniert, sehen wir dann später noch. Deshalb beginne ich mit dem CrystalDiskMark und vier verschiedenen Dateigrößen. Die SSDs waren zum Testzeitpunkt nicht mehr neu (ich mache diese Tests aus gewissen Gründen immer erst zum Schluss) und ich hatte vor dem mehrmaligen Löschen der Daten auch schon einmal Füllstände von reichlich 50%.
Das erklärt sicher auch, dass man beim Schreiben ein ganz klein wenig an den Maximalwerten vorbeischrammt, aber immer noch beeindruckende Zahlen aufweisen kann. Deshalb sicher auch die Formulierung mit dem „bis zu“. Vergleichen wir nun die MSI SPATIUM M570 Pro und die Corsair MP700 Pro mit jeweils 2 TB Speichergröße. Wir sehen, dass die SSDs in etwa gleich schnell sind. Fast, denn wir sehen auch, dass Corsair bei den kleinsten Blöcken leichte Vorteile hat.
| Corsair MP700 Pro 2TB | MSI SPATIUM M570 Pro 2TB |
 |
 |
 |
 |
 |
 |
 |
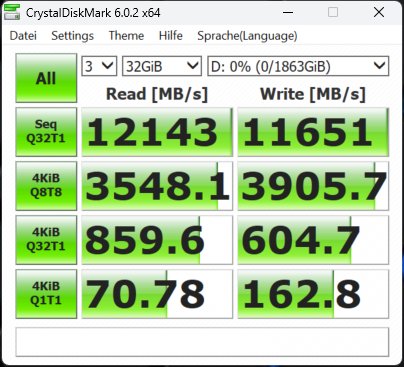 |
Man erkennt sehr gut, dass der dynamische pSLC genau das macht, was er soll, wohlgemerkt bei einer leeren (wenn auch nicht jungfräulichen) SSD. Das Schöne an der 2 TB SSD ist ja, dass jede Menge Platz bleibt und man sie deshalb besser nie mehr als 2/3 mit Daten füllen sollte. Dem Lesen tut eine höhere Auslastung keinen Abbruch, nur beim Schreiben gerät der dynamische SLC dann mit Sicherheit irgendwann an seine Grenzen. Und wenn man es immer und immer wieder tut, wird auch der Switch der Speichermodule zwischen beiden Methoden irgendwann nicht mehr möglich sein.
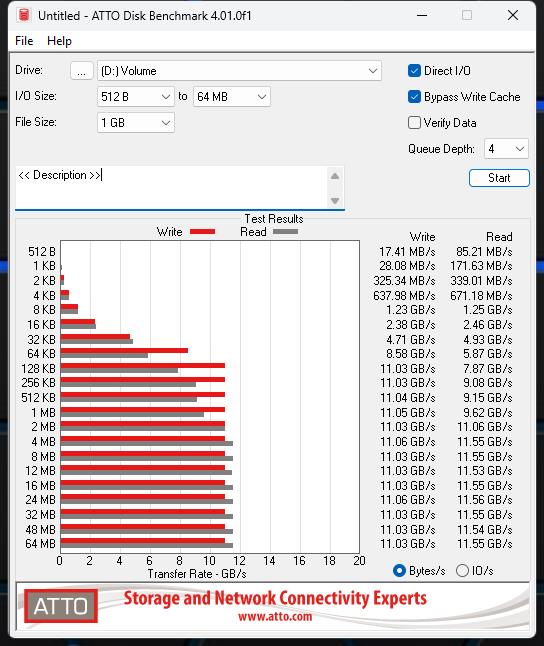
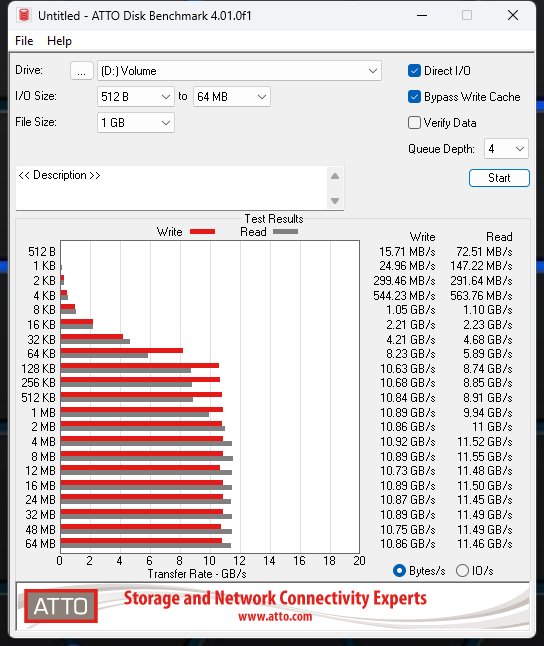
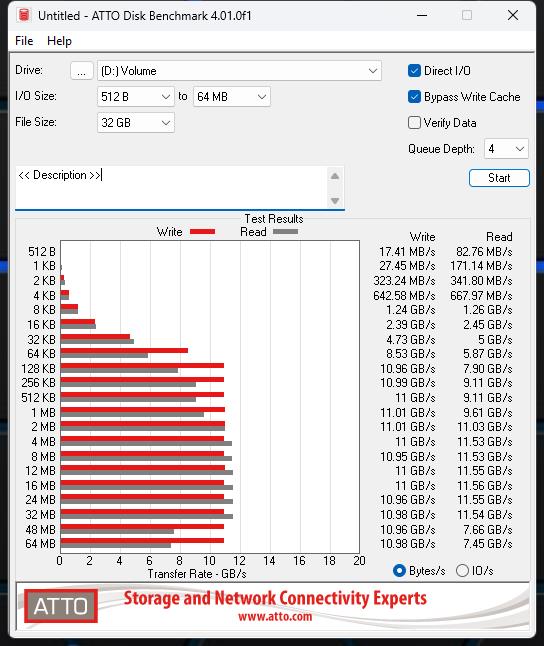
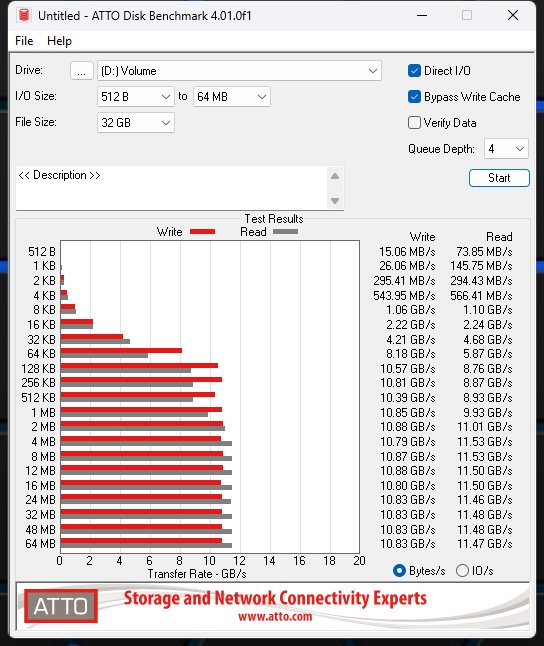
Sehr ähnlich agiert auch ATTO, wobei ich hier mit nur zwei Größen arbeite, was am Ende aber aufs Gleiche rausläuft. Man verfehlt die Grenze von 12000 MB/s nur knapp, aber es reicht auch so für ein beeindruckendes Ergebnis. Aber: die SSD von Corsair bricht bei der Dateigröße oberhalb von 32 GB beim Lesen auf PCIe 4.0 Tempo ein, während die MSI-SSD locker durchzieht. Diese ist zwar auch hier einen Tick langsamer, dafür aber durchgehend stabil in der Performance.
| Corsair MP700 Pro 2TB | MSI SPATIUM M570 Pro 2TB |
 |
 |
 |
 |
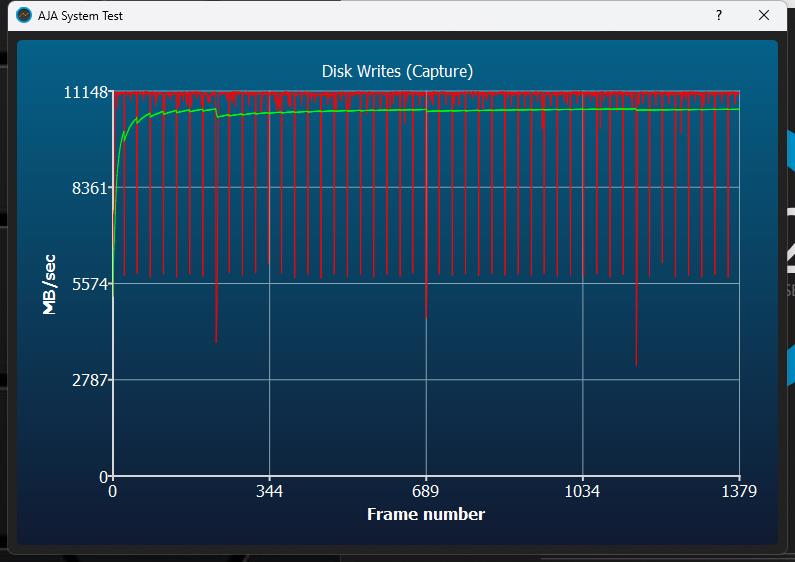
Doch was passiert, wenn man ein Video streamt? Dafür nutzt die Industrie den AJA Benchmark, der faktisch eine Schnittstelle zwischen synthetischen Benchmarks und praktischer Anwendung darstellt. Der Abstieg der Rate beim Schreiben unterscheidet sich deutlich, auch die leichten Absätze, die aber eher marginal sind.
| Corsair MP700 Pro 2TB | MSI SPATIUM M570 Pro 2TB |
 |
|
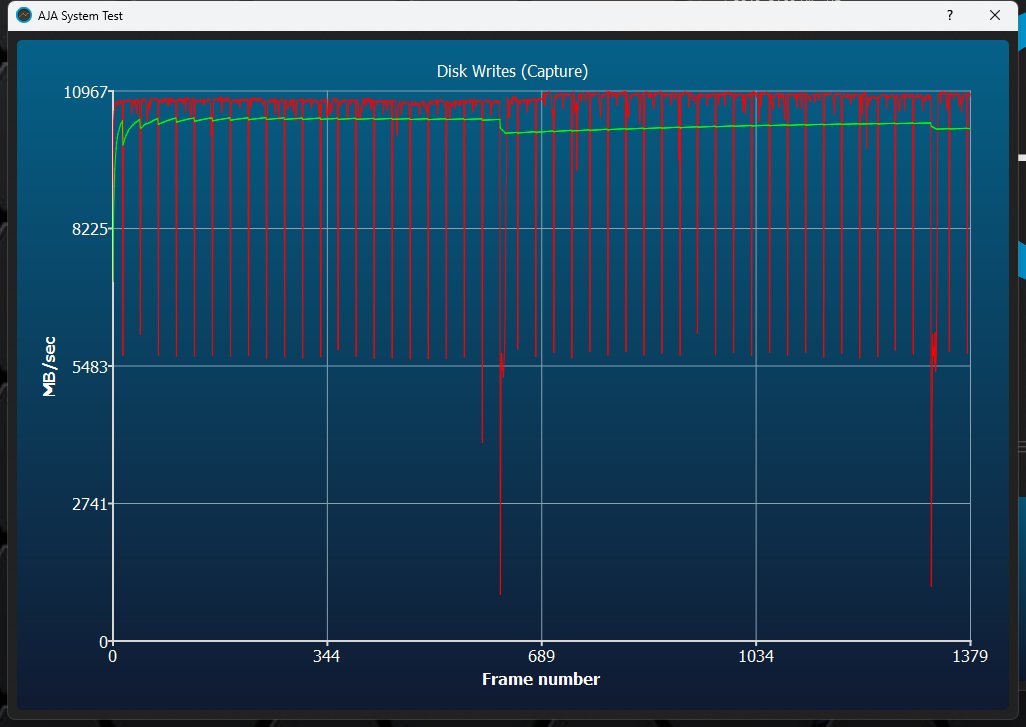
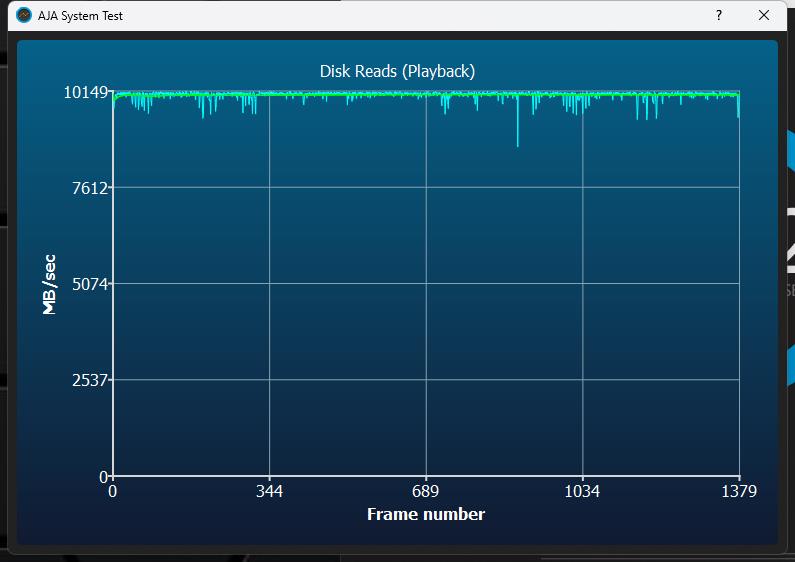
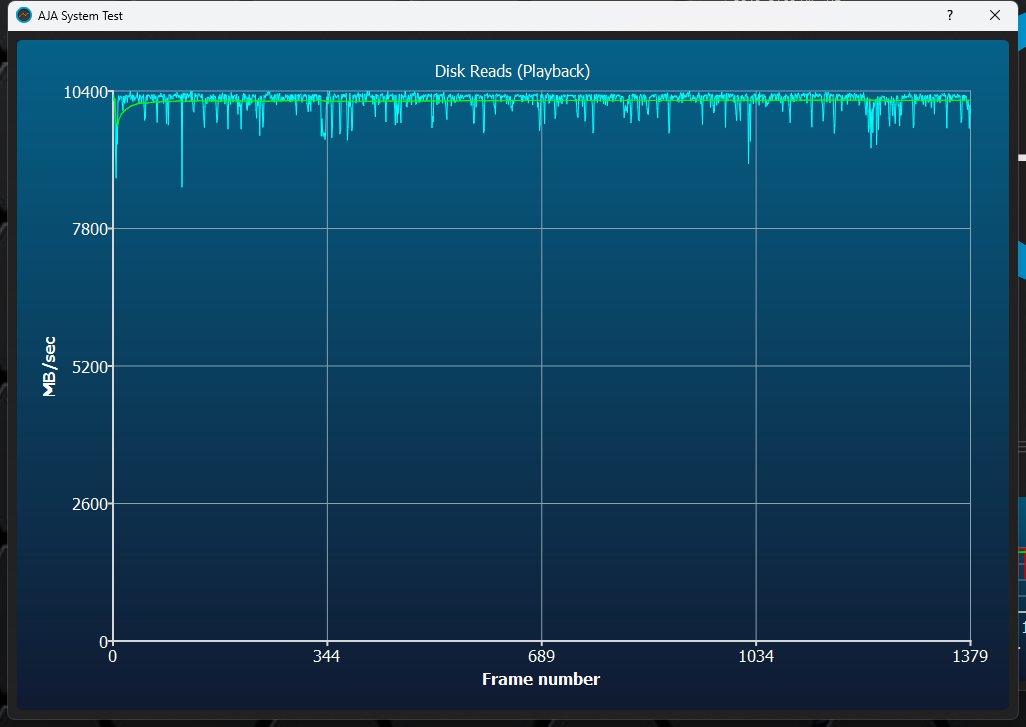
Das Lesen geht auch recht flott vonstatten, wobei man auch hier nicht die theoretisch mögliche Geschwindigkeit erreicht. Da hat die MSI SPATIUM M570 Pro 2TB sogar erstmals einen Vorteil. Wir erinnern uns schnell mal an ATTO, den hier geht es ja auch um einen 64 GB Stream.
| Corsair MP700 Pro 2TB | MSI SPATIUM M570 Pro 2TB |
 |
 |
Das Ganze habe ich noch einmal als detailliertes AJA-Protokoll für Euch angehängt:
BENCHMARK-TABLE
Wir sehen, dass die auf der vorigen Seite gemachten Anmerkungen zum dynamischen pSLC Cache und dem Verhalten bei den größeren Dateiblöcken vollends zutreffen. Kleinere Dateibewegungen wären nämlich durchaus noch schneller, wenn man den Overhead des Dateisystems mal weglässt.
















33 Antworten
Kommentar
Lade neue Kommentare
Veteran
Urgestein
Urgestein
1
Urgestein
Urgestein
1
Urgestein
Mitglied
Veteran
Urgestein
Veteran
Urgestein
Mitglied
Veteran
Neuling
Veteran
Alle Kommentare lesen unter igor´sLAB Community →