













Synthetic Benchmarks – AIDA64, Geekbench 3, SuperPI 32M, LinpackXtreme
In addition to the usual synthetic benchmarks in our RAM tests, AIDA64 and Geekbench 3, we also have SuperPI 32M and LinpackXtreme 10G again today. While the first two tests provide rather general indicators and theoretical values, the two new benchmarks are based on specialized mathematical problems. With different problems there are also different effects of the configuration properties on the final performance, but more about that in a moment.
AIDA64 uses version 6.50.5819 beta, which was the latest at the time of testing. Although this version still issues a warning that the software is not fully optimized for the new Intel Alder Lake platform, this is certainly suitable for comparing RAM configurations on the same platform. In the bandwidth tests, the result is as expected and DDR5 with its much higher clock speed is far ahead of DDR4.
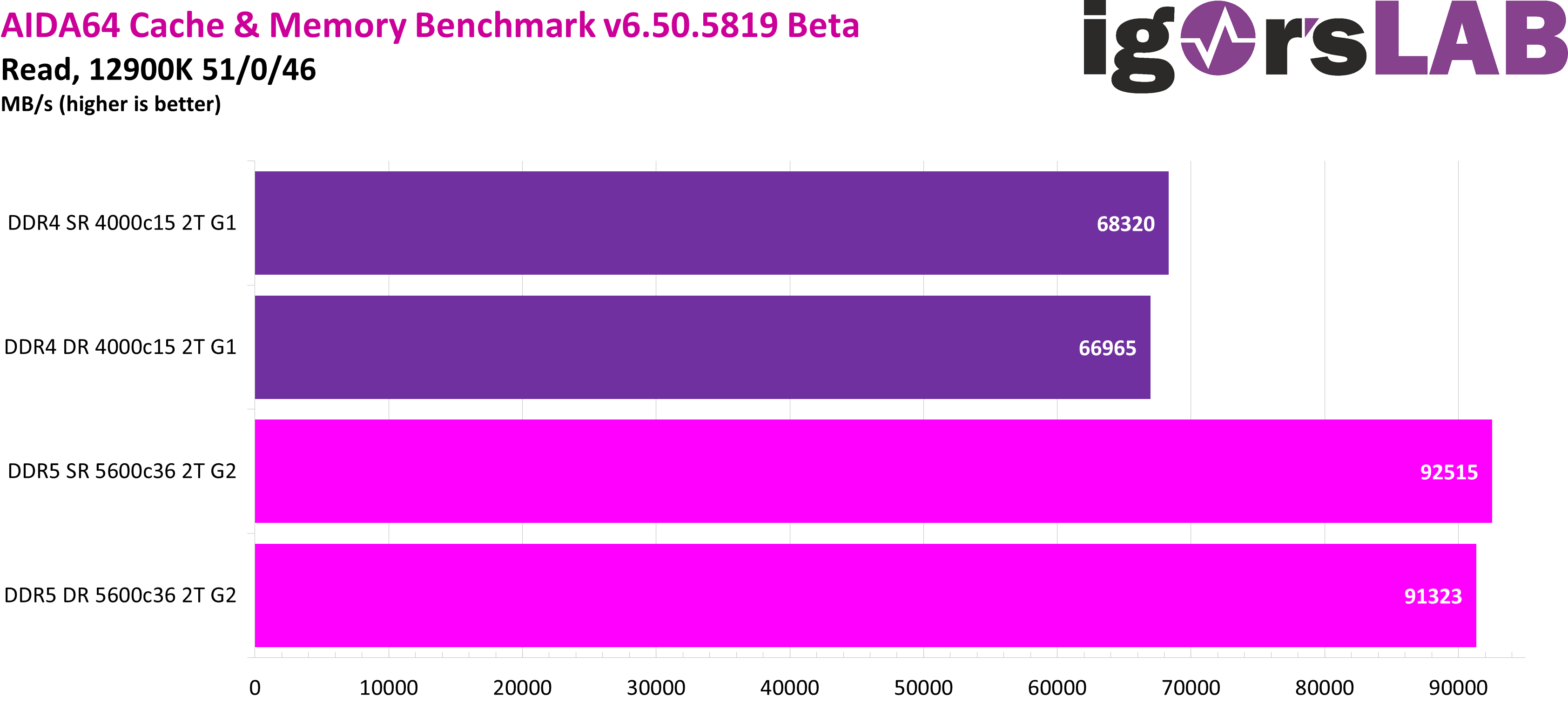
As with previous platforms, dual-rank configurations lose some measured read bandwidth compared to their single-rank counterparts. And even if the leap to over 90 GB/s already seems enormous, much higher results can already be achieved in single-rank with faster kits and correspondingly optimized mainboards.
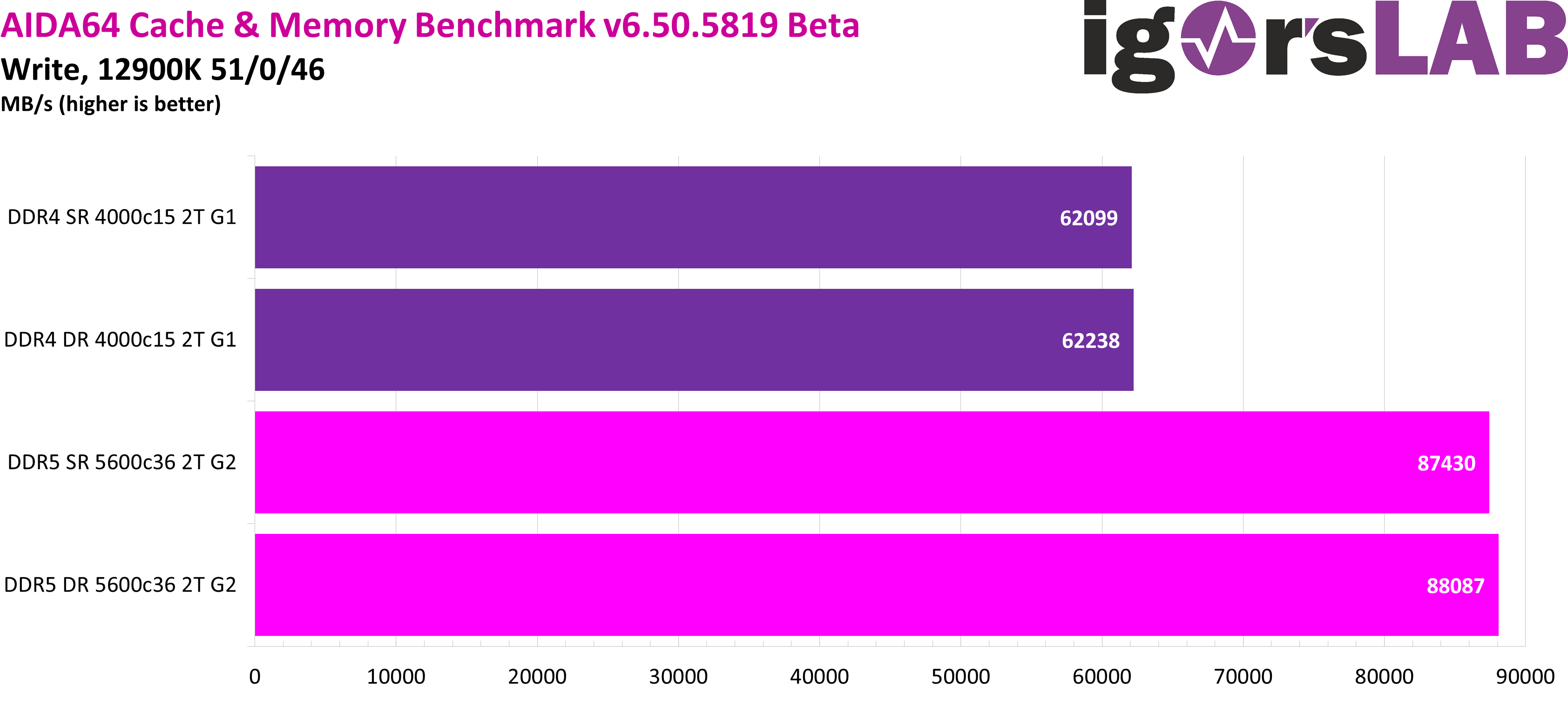
The picture is almost identical in the write test, whereby the dual-rank configurations have a small advantage here.
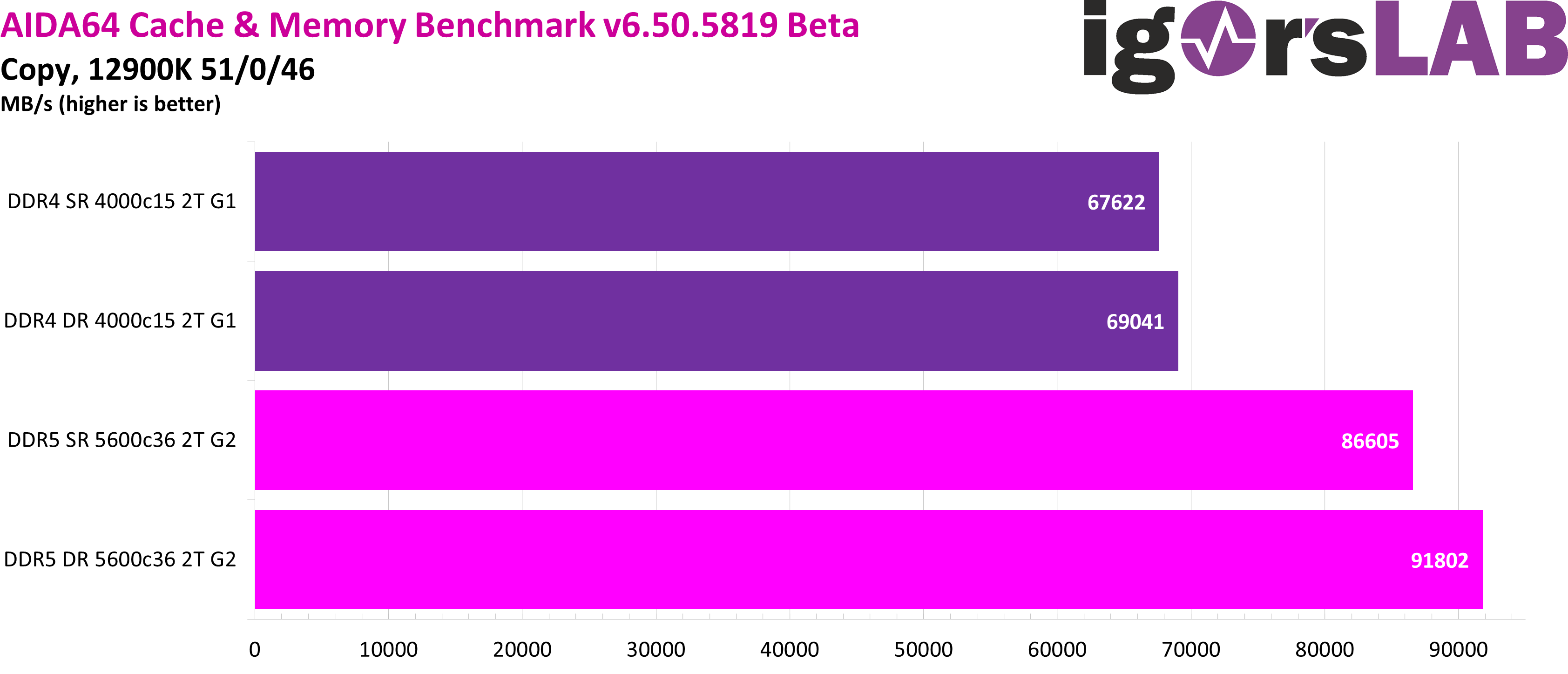
In the copy test, the often-talked-about rank interleaving now comes into play, allowing the ranks to effectively take turns at work and thus utilize the CPU’s two memory channels much more efficiently.
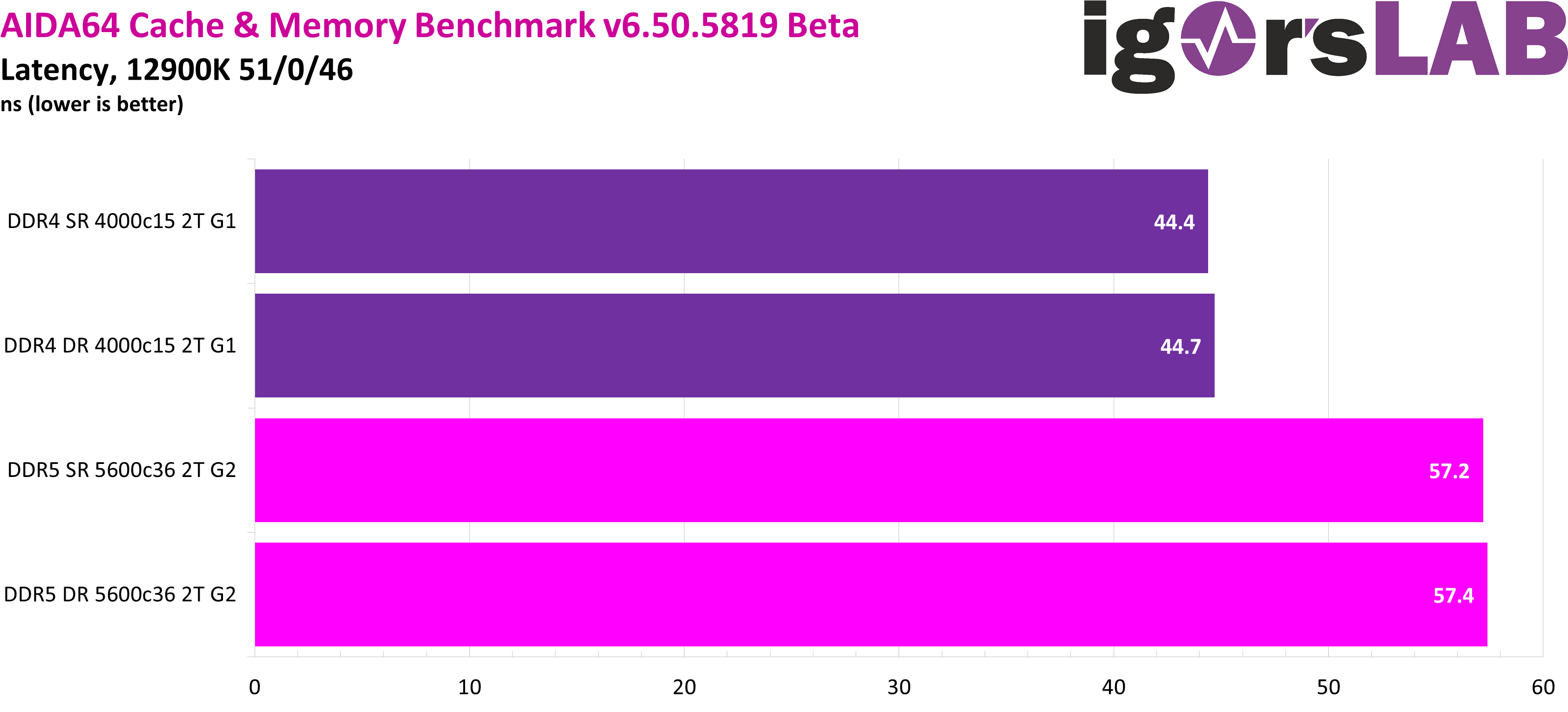
When it comes to latency, DDR5 has taken a big step backwards, and not just on paper. And even though various protocol optimizations were made under the hood – keywords burst length and bank groups – the increase in latency in our DDR5 configuration is almost 30% compared to DDR4. In addition, the higher “administrative effort” of Dual-Rank in each case brings an additional small but measurable disadvantage.
For those who have already researched DDR5 extensively over the past few weeks, none of this will come as a surprise. With the new generation, we get higher clock rates and thus higher bandwidths, at the expense of latency. To make the terms more tangible, I’ll use a race car analogy: with DDR5, we have higher top speeds on the straights, but are slower in the corners and when changing direction. In the end, it all depends on how the “race track” is structured and whether top speed or agility – high bandwidth or low latency – is favored more.
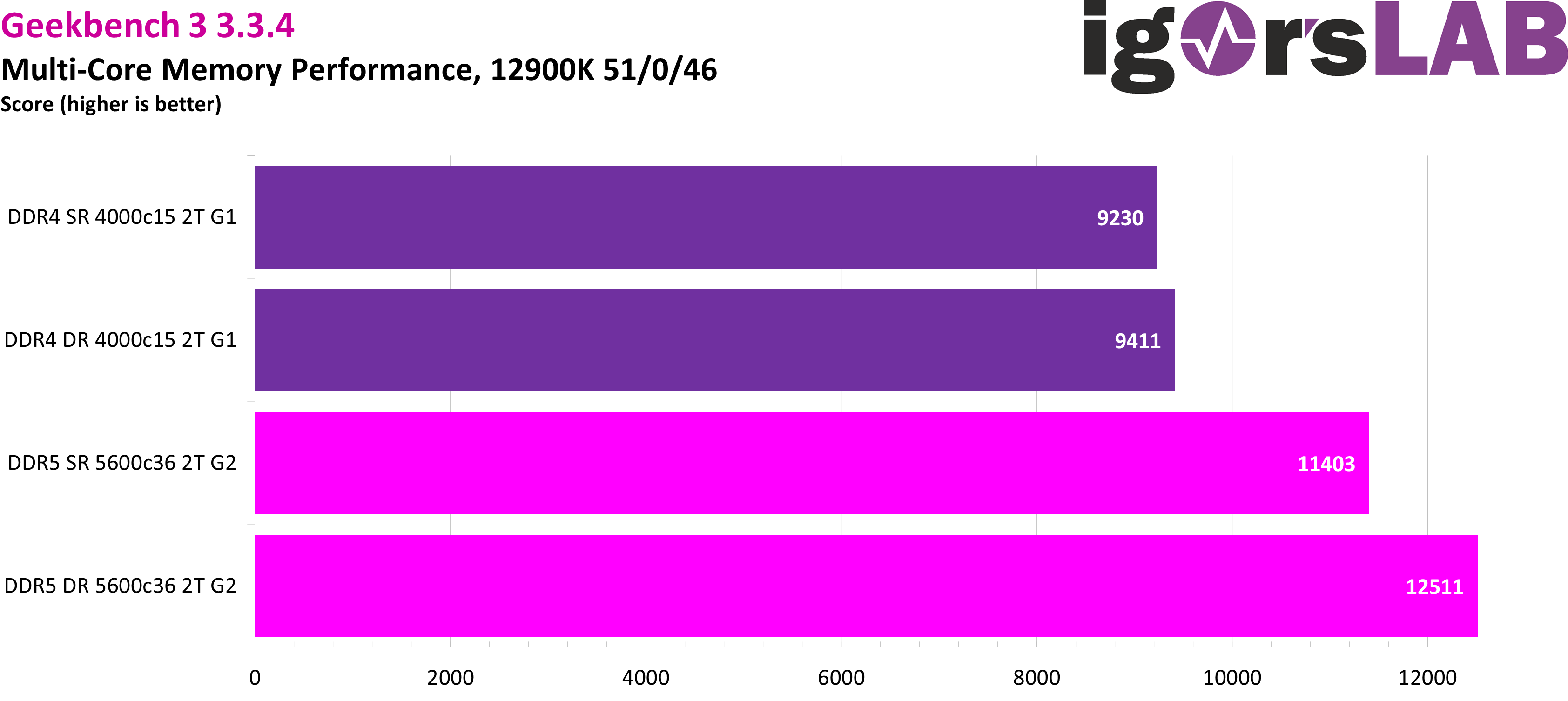
In Geekbench 3, we can see very nicely that the score scales very strongly in results with both bandwidth and ranks. This benchmark bascially can’t be bothered at all by the disadvantage in latency.
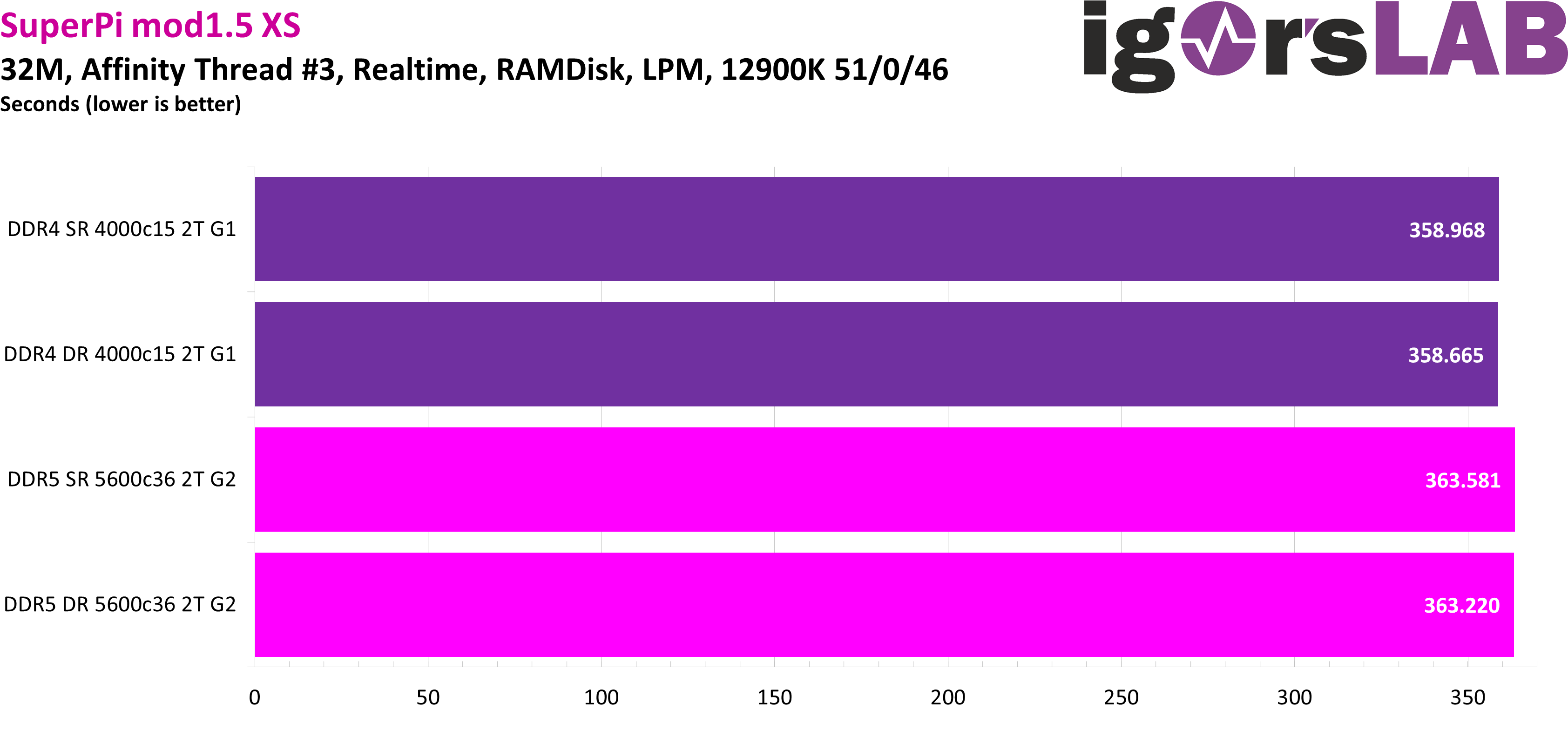
However, it looks quite different again in SuperPi 32M, where the bandwidth seems to be almost irrelevant, but the latency disadvantage of DDR5 becomes noticeable. 5 seconds difference in the result only by different RAM configurations are massive here! No wonder the current SuperPi world record was set with Alder Lake and DDR4.
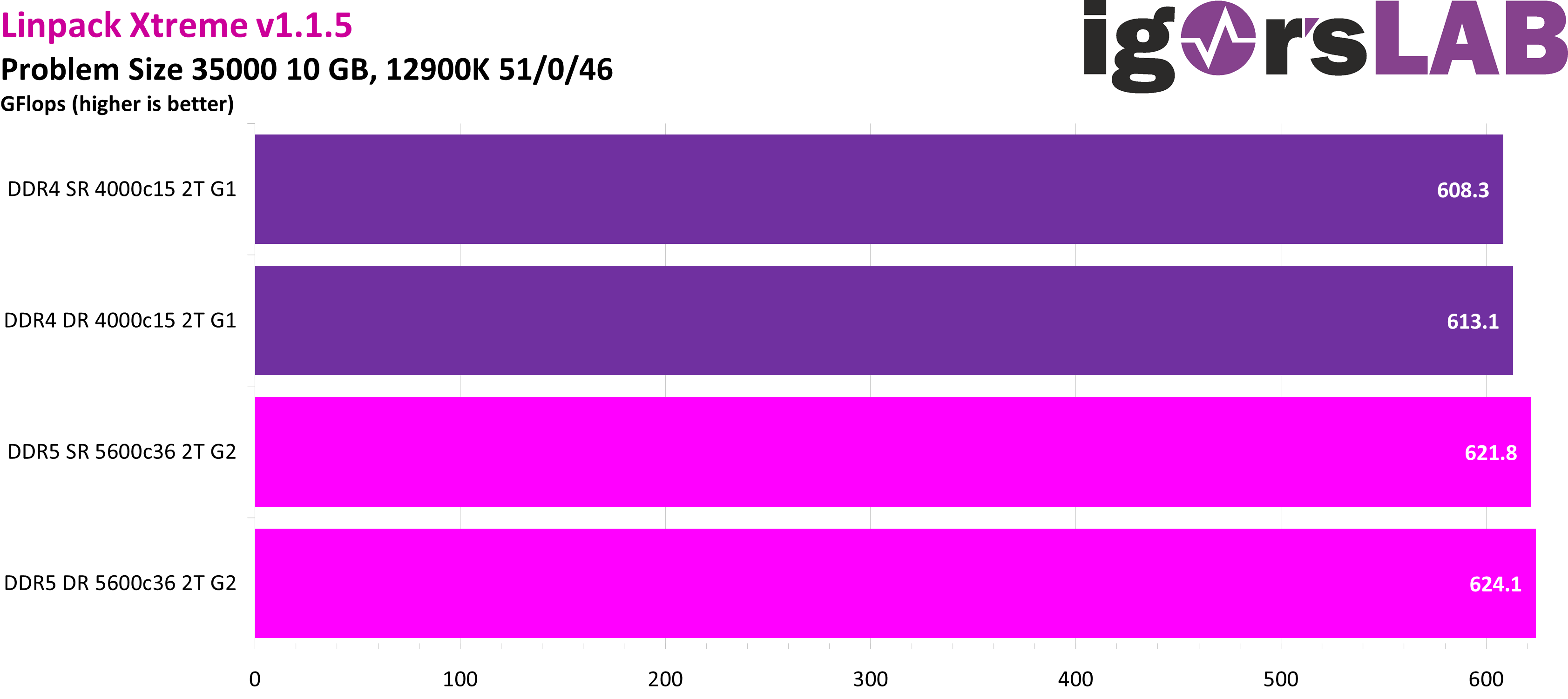
Finally, I have the LinpackXtreme up my sleeve. Even though the ratios seem identical to SuperPi 32M at first glance, more is better here for one thing, and this benchmark scales with bandwidth and latency for another. Because if we put the gain from the increased bandwidth, as measured with AIDA64, into perspective, it turns out to be rather meager. The reason for this is that the significantly higher latency clearly counteracts this. I wonder if this could already be a harbinger of what’s in store for us in gaming?



















19 Antworten
Kommentar
Lade neue Kommentare
Mitglied
Veteran
Urgestein
Veteran
1
Veteran
Veteran
Neuling
Urgestein
Urgestein
Neuling
Veteran
Neuling
Mitglied
Urgestein
Veteran
Mitglied
Veteran
Neuling
Alle Kommentare lesen unter igor´sLAB Community →