











Ich habe heute etwas ziemlich Aufregendes für Eure Leser; etwas, das fast jeder bei großen Getöse um die Apple M1-Benchmark-Vergleiche verpasst zu haben scheint. Was wäre, wenn ich Euch sagen würde, dass so ziemlich alle Single-Core-Benchmark-Vergleiche zwischen dem Apple M1 und modernen x86-Prozessoren, die Ihr online sehen könnt, grundlegend fehlerhaft sind (vorausgesetzt, Ihr wollt sehen, welcher Kern der schnellste ist)? Denn wie Ihr seht, nutzen die meisten Einzelkern-Benchmarks, die im Umlauf sind, einen modernen x86-Kern nicht einmal vollständig aus – aber wahrscheinlich die des M1.

Warum x86-“Single-Core”-Benchmarks beim Vergleich mit einer Nicht-SMT-Architektur wie des Apple M1 keine tatsächliche Single-Core-Leistung anzeigen
Unsere Geschichte beginnt mit einer Industrie, die von x86-Prozessoren dominiert wird. Fast alle heute auf dem Markt erhältlichen x86-Prozessoren (mit Ausnahme einiger älterer CPU-Modelle, bei denen diese Funktion absichtlich deaktiviert wurde) würden in ihrer Architektur eine SMT-Implementierung verwenden. Enthusiasten kennen diese Funktion durch Intels Hyper-Threading und analog dazu auch AMDs SMT, denn AMD nutzt ja ebenfalls eine eigene Implementierung. Man sieht also, moderne x86-Kerne sind sehr breit aufgestellt und ein einziger Thread in Windows reicht normalerweise gar nicht aus, um den Kern wirklich komplett auszulasten und all seine Ressourcen zu nutzen. Aus diesem Grund werden ja jedem Kern eigentlich zwei Threads zugewiesen, in denen er dann den Workload abarbeitet. Hier ist eine kleine technische Erklärung:
It is worth noting that SMT philosophy is embedded in the design. The decode to uOP, and subsequent optimizations for scheduling through retirement (including intermediate issues instruction dependencies, pipe-line bubbles and flushing, etc.), are a large part of why x86 embraced SMT. RISC load/store architectures simply have less front-end decoding complexity, versus decoupled CISC, and thus are able to obtain better Instruction per Thread, per clock. This is why dispatching multiple threads is required to maximize the performance of a single core (in x86).
-A friendly architect who wishes to not be named.
Die “Single-Core”-Option in Cinebench (und so ziemlich alle anderen Benchmarks) ist damit genauer gesagt eigentlich eine “Single-Thread”-Konfiguration.

Hier kommt nun der x86-dominierte Teil der Industrie ins Spiel. Aktuelle Benchmarks, die im “Single-Core”-Modus ausgeführt werden, legen die gesamte Last tatsächlich auf einen einzigen Thread. Da man ja normalerweise Vergleiche zwischen SMT-basierten Architekturen anstellt, handelt es sich um einen Vergleich von Äpfeln zu Äpfeln (*hust*), da beide Kerne in ähnlicher Weise behindert werden. Wenn man jedoch von einer völlig anderen, nicht SMT-basierten Architektur spricht, wird es eine ganz andere Geschichte (Birnen). Im Gegensatz zu x86 ist Apples M1 nämlich nicht SMT-basiert und benötigt damit auch nur einen Thread, um den Kern wirklich auszulasten (oder zumindest glaubt Apple dies aufgrund seiner Designphilosophie).
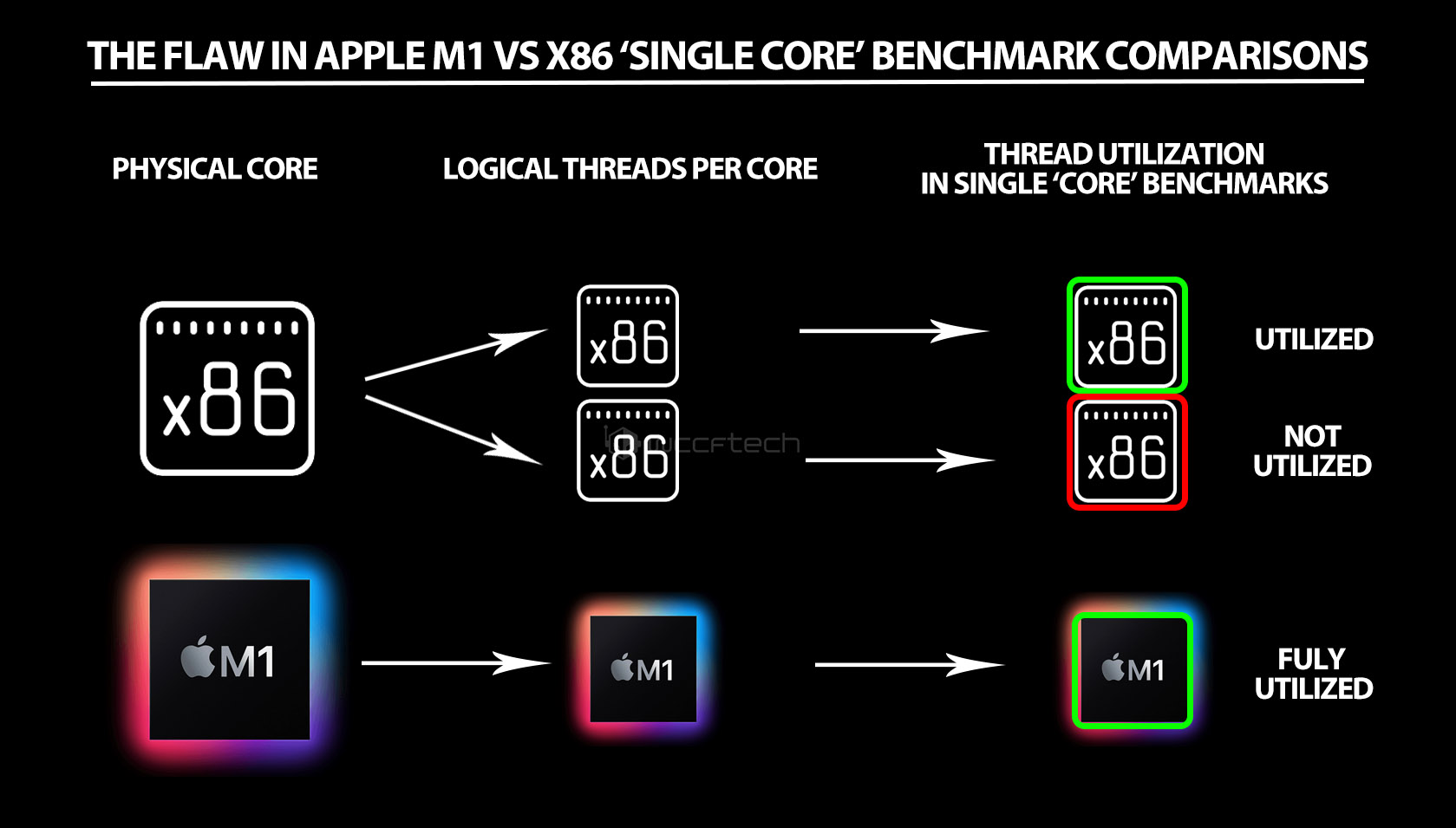
Inzwischen hätten die informierten Leser bereits begonnen, das Problem zu erkennen. Wenn man einen “Single-Core”-Benchmark auf einem Apple M1 durchführt, dann verwendet er alle Threads, die mit dem Kern verbunden sind, aber wenn Sie dasselbe auf einer modernen x86-CPU durchführen, dann verwendet er nur die Hälfte der Threads, die mit dem Kern verbunden sind. Denkt jedoch daran, dass die “halbe” Zahl etwas irreführend ist, da die SMT-Geschwindigkeit normalerweise im Bereich von 20-30% liegt. Nun gibt es zwei Möglichkeiten, mit diesem Problem umzugehen und die Ergebnisse auf eine gleichmäßigere Grundlage zu stellen.
Die erste Methode bestünde jetzt darin, SMT einfach auszuschalten, so dass jedem Kern nur ein Thread zugeordnet ist – genau wie bei Apple. Leider wäre dies jedoch unfair gegenüber dem genannten Prozessor, da moderne x86-Prozessoren grundsätzlich für die Verwendung mit SMT ausgelegt sind. Tatsächlich gibt es praktisch keinen Unterschied zwischen Single-Thread-Ergebnissen mit eingeschaltetem HT und ausgeschaltetem HT.
Die zweite Methode bestünde also darin, dem Benchmark zu erlauben, beide Threads, die mit einem einzigen Kern verbunden sind, zu verwenden. Für die Zwecke unserer Tests verwendeten wir Thread 0 und 1 (die beide auf Core 0 liegen) und konfigurierten Cinebench so, dass nur zwei Threads im Multicore-Modus verwendet werden, während gleichzeitig die oben erwähnte Affinität durch den Task-Manager angewendet wird. Die Ergebnisse waren, gelinde gesagt, aufschlussreich.
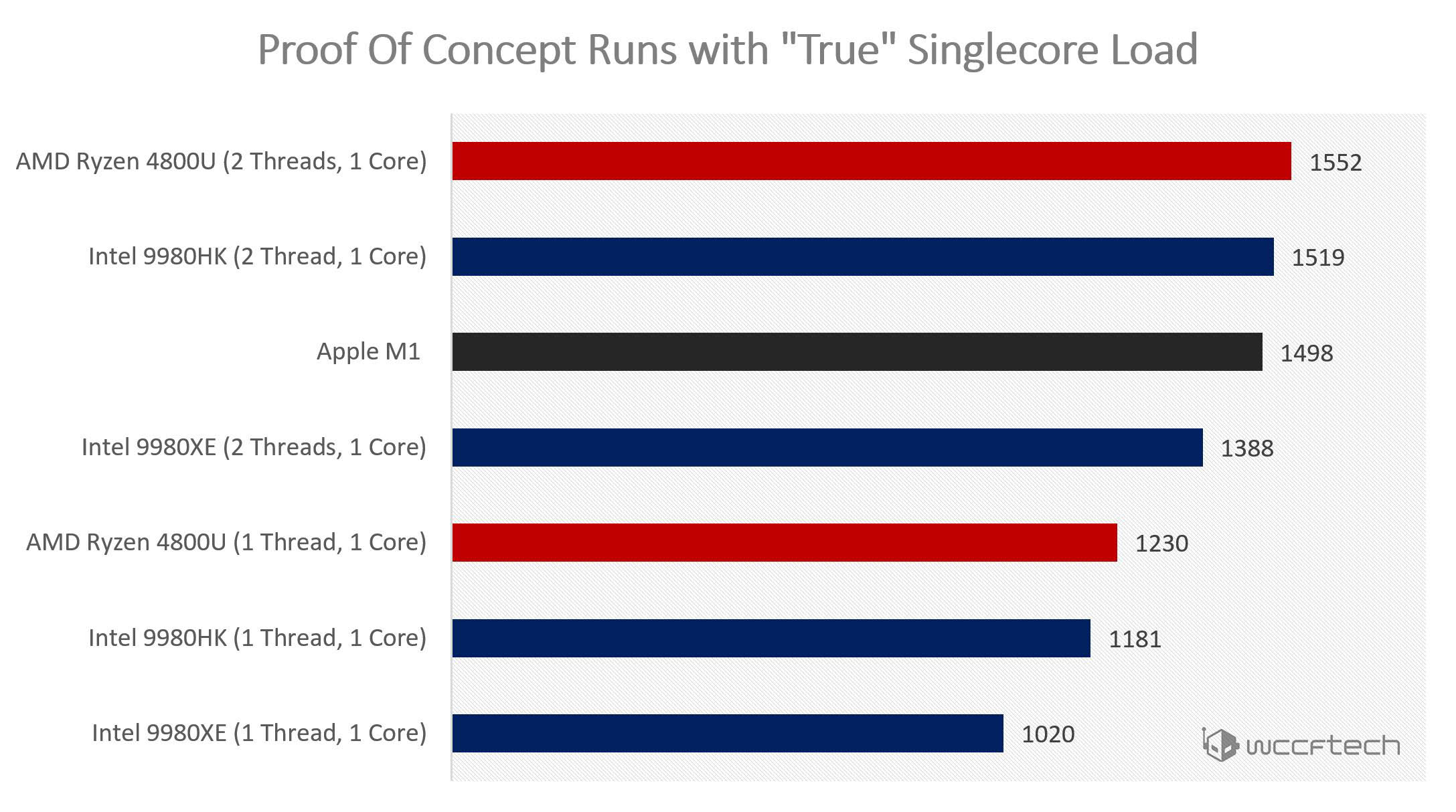
Wir konnten eine Verbesserung der “Single-Core”-Ergebnisse um 20 bis 30 % verzeichnen, wenn x86 SMT-basierte Prozessoren auch den zweiten Thread, der mit demselben Kern verbunden ist, nutzen konnten! Wen es interessiert, man kann beim Geekbench ebenfalls eine durchschnittliche Verbesserung von 20-25% mit derselben Technik feststellen. Ihr könnt Euch unseren verifizierten 9980XE-Vergleich hier ansehen. Ein großes Lob geht dabei auch an Joel Hruska von Extremetech dafür, dass er den Ryzen 4800U-Benchmark für uns während seines Urlaubs durchgeführt hat!
Basierend auf unserem begrenzten Beispielsatz würden so ziemlich alle hocheffizienten x86-Prozessoren der aktuellen Generation (Mobile-CPUs) den ursprünglichen Single-Core/Single-Thread-Wert des Apple M1 übertreffen. Wir haben übrigens später auch noch einen Desktop-Prozessor der alten Generation, 9980XE, hinzugezogen, der ähnliche Gewinne erzielte.
Schlussfolgerung: Benchmark-Anbieter müssen zu SMT-fähigen Single-Core-Tests übergehen, um eine bessere Auslastung von x86-Kernen beim Vergleich verschiedener Architekturen zu gewährleisten
Die aufgetretene Performance-Steigerung basiert somit offensichtlich auf dem Boost-Verhaltens des Kerns, so dass die Ressourcen des Kerns dann auch voll ausgenutzt werden können. Wenn man bedenkt, dass es ja einer der Hauptvorteile des x86 im Vergleich zu ARM-basierten CPUs die eigentliche Taktgeschwindigkeit ist, dann wird die SMT-Unterstützung umso wichtiger, um ein viel klareres Bild der wahren Kernleistung zu liefern. Es versteht sich von selbst, dass sich dieser Fehler nicht auf Multi-Core-Ergebnisse auswirkt. Diese sind immer noch gültig, da Cinebench (und so ziemlich alle anderen Anbieter) alle verfügbaren Threads dafür verwenden.
Hier kommt nun der Moment der Wahrheit, auf den alle gewartet haben. Wenn Ihr Euch an unseren ursprünglichen Benchmark-Vergleich erinnert, haben wir ja gezeigt, wie Intels Tiger Lake-Plattform den Apple M1 bei den Single-Core/Single-Thread-Ergebnissen tatsächlich übertraf. Wir waren gespannt, was passieren würde, wenn wir dem Prozessor erlaubten, zwei Threads zu verwenden, und nicht überraschend – es war eine Liga für sich. Im Vergleich zu seinem ursprünglichen Ergebnis von 1510 erzielte er eine Geschwindigkeitssteigerung von 19%, womit er dem Apple M1 weit überlegen ist!

In Anbetracht der Tatsache, dass man Performance-Gewinne zwischen 20% und 30% sehen konnte, verwenden wir eine durchschnittliche (im schechtesten Fall) Steigerung von 20%, um die grobe Leistung von CPUs abzuschätzen, die wir nicht herumliegen hatten. Eine Warnung: Bei den mit einem Sternchen markierten Ergebnissen des Benchmarks (Bild oben) sollte man besser noch auf verifizierte Ergebnisse warten, denn diese Schätzungen sind nur enthalten, um Euch eine grobe Vorstellung von der Position zu geben, die die CPUs belegen könnten.
Zusammenfassung und Fazit
Eines ist nunmehr allen klar geworden: Benchmark-Anbieter müssten zumindest einen Testmodus hinzufügen, der es ermöglicht, beide Threads, die zu einem einzigen Kern gehören, zu nutzen. Es geht also nicht um einzelne Threads, sondern um Kerne! Dies ist sehr wichtig, um eine vollständige Kernauslastung und einen gleichmäßigeren Vergleich zwischen SMT-basierten und Nicht-SMT-Architekturen überhaupt erst zu gewährleisten. Da x86-Kerne nicht vollständig mit einem einzigen Thread ausgelastet sind, wäre ein Vergleich zwischen Nicht-SMT-Architekturen ein reiner Vergleich von Äpfeln und Birnen.
Wir mussten mit unserem Cinebench R23-Programm ringen, um es erst einmal dazu zu bringen, diese Last so zu akzeptieren (Threads auf 2 gesperrt, die Affinität musste nach Beginn des Laufs, aber vor dem eigentlichen Benchmark eingestellt und nach dem ersten Durchlauf erneut angewendet werden) und eine sauberere Umsetzung in den Settings der einzelnen Benchmarks wäre mit ziemlicher Sicherheit sehr zielführend. Sie würde es uns auch ermöglichen, Kerne so zu testen, dass sie ihr volles Potenzial überhaupt entfalten können. Ein letzter Dank geht jetzt noch an den Software-Ingenieur qjvar, der mir bei diesem Stück geholfen und unsere Hypothese auf architektonischer Ebene bestätigt hat.
Dieser Artikel wurde mit freundlicher Genehmingung von Usman Pirzada für die deutsche Übersetzung auf igor’sLAB freigegeben und als Gastartikel publiziert. Das Original wurde auf wccftech.com auf Englisch veröffentlicht.


















Kommentieren