











I had already written an article about the announcement of DLSS 2.0 at the end of March and Deep Learning. DLSS 2.0 has been very positive in all four games in which it is available. In contrast, the first implementation of Deep Learning Super Sampling weakened a little and rather shines with very mixed results. This then ranged from crisp to wivash and blurry, depending on the game and implementation. Even if the GTC did not take place in real life this year, there was probably an online version where you could also accredit yourself.
And for those curious who wanted to know more, NVIDIA’s lead research scientist Edwin Liu detailed what makes NVIDIA DLSS 2.0 such a big upgrade from the previous version in a presentation as part of the virtual GTC 2020, which was also recently released on the NVIDIA website. It was a very interesting presentation, from which you only have to extrahirl the most important thing in the end, so as not to get too lost in the detail.

Here you can watch the almost 50-minute video for yourself.
Let’s summarize it briefly There are two possible approaches for rendering images in superresolution, as a single frame or as a multi-frame. The former may be used more often and is therefore more well known, as pure interpolation filters are usually used. We also know this from the normal upscaling of video content in various software applications or hardware conversions (z.B.TV devices). Lately, however, deep neural networks have been used to “hallucinate” new pixels after training, i.e. to reproduce them. A very good example of this is ESRGAN, the Enhanced Super-Resolution Generative Adversarial Networks model, on which several AI-enhanced texture packages for older games are based.

The images reconstructed by simple interpolation filters are, simply put, too little detailed compared to the native image. DNNs do a better job in this regard, but since they “hallucinate” the new pixels, the result can be inconsistent with the native image. However, NVIDIA considers this unacceptable for DLSS, as the goal is to stay as close as possible to the “Ground Truth” image and the game developer’s original vision.
Another big problem is that the resulting image is often time unstable, so flickers and flickers. That’s why Nvidia chose a multi-frame super-resolution approach to DLSS 2.0. This allows multiple low-resolution frames to be combined into a high-resolution image, making it much easier to restore true detail. This is done with spatial-temporal upsampling techniques such as the now ubiquitous Temporal Antialiasing and checkerboard rendering.

Since these reconstruction techniques use samples from multiple frames, they are much less likely to encounter temporal instability problems such as flickering. In addition, while the shading rate is kept low for each frame to achieve strong performance, the effective sampling rate is dramatically increased due to the multi-frame reconstruction approach. This does not mean that there are no problems with TAA or CR. Because there are changes in content when rendering games in real time (the scenes are dynamic continuously, after all), the naive assumption that previous frames are correct could easily lead to artifacts such as ghost images or delays.
Typically, these issues are handled with a heuristically based history correction of invalid samples from previous frames. However, this also brings with it other problems, such as flickering, blurring and the hated moiré pattern. Nvidia solves these problems by taking advantage of the power of a supercomputer that trains offline on tens of thousands of extremely high-quality images. These so-called neural networks are simply much better suited for such a task than simple heuristics, as they can find the optimal strategy to combine insights collected over several images and thus provide a much higher-quality reconstruction.

It is therefore a data-driven approach that enables DLSS 2.0 to successfully reconstruct even complex situations such as those with the Moiré pattern. The following image comparisons are consistently impressive and in most cases outperform even native images at a 4-fold upscaling from 540p to 1080p.

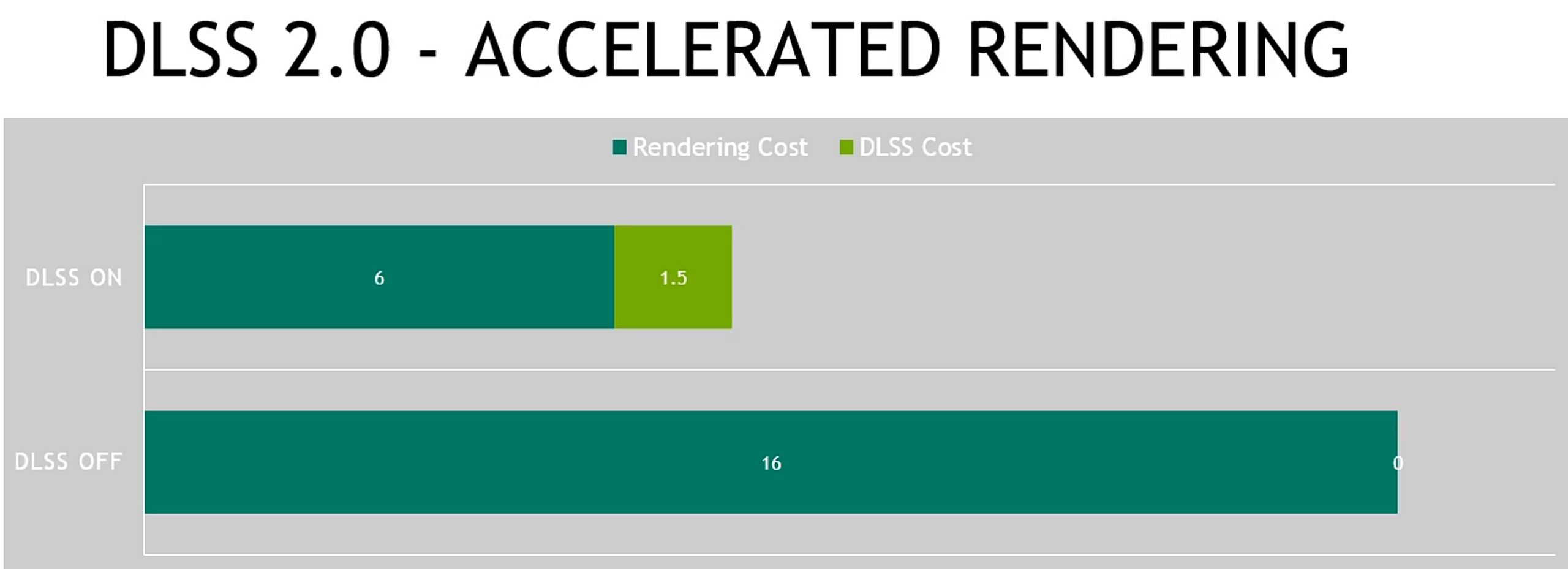
Of course, it is Nvidia’s declared maxim to achieve optimal performance with the lowest possible overhead with DLSS 2.0. The additional power required for this is almost insignificant, as it only takes 1.5 milliseconds on a GeForce RTX 2080Ti to render an image at a resolution of 4K. The fact is that adding DLSS 2.0 is much easier for game developers. And it’s not just about the Unreal Engine 4 and the fact that the generalized neural model no longer needs to be trained individually per game, but above all that the multi-frame approach allows to implement DLSS 2.0 in all those games and engines that already support Temporal Antialiasing (TAA).
It will be interesting how these techniques will evolve, so I think it’s really exciting.















Kommentieren