











Da Ihr wisst, dass auf unserer Seite die Community eine nicht unwesentliche Rolle spielt, haben auch die Forenmitglieder natürlich nicht nur eine eigene, private Meinung, sondern hier auch die Möglichkeit, sich in Form eines Editorials nach inhaltlicher Absprache der Grundregeln öffentlich zu äußern. Somit sind diese Artikel unabhängige Gastbeiträge unserer aktiven Foren-Mitglieder, die eine persönliche Meinung wiederspiegeln, die nicht zwangsläufig das gesamte Forum repräsentieren kann, es in gewissenn Teilen aber mit Sicherheit tut. Der heutige Gastbeitrag kommt von skullbringer, der sich sehr viel Mühe gegeben hat, um die letzten turbulanten Wochen rund um NVIDIAs Ampere-Launch noch einmal zusammenzufassen. Es ist seine Sicht der Dinge, die ich auch nicht weiter zu kommentieren habe.
Viele Faktoren treffen das übliche Click-Bait
Mit der Veröffentlichung des 456.55 Treibers von Nvidia wurden alle CTD (Crash to Desktop) Probleme gelöst, die von Ampere Nutzern seit der Markteinführung gemeldet wurden. Viele Medien kamen daher zu dem voreiligen Schluss, dass die Kondensatoren doch gar nicht die Ursache waren, sondern ein fehlerhafter, unausgereifter Boost-Algorithmus im Treiber. Eine einfache Lösung für ein einfaches Problem, super! Aber so einfach ist es in Wirklichkeit nicht. Wir müssen das große Ganze betrachten, um zu verstehen, was das Problem verursacht hat und wie so etwas in der Zukunft verhindert werden kann. Lasst mich das mal erklären.

POSCAPs – “Pieces of shit caps” oder nur ein missverstandener Kompromiss?
Als Igor zum ersten Mal einen möglichen Grund für die CTD Probleme beleuchtete, in Form der unterschiedlichen Kondensator Konfigurationen auf der Rückseite der RTX 3080 und 3090 GPUs, entwickelten sich ziemlich bald zwei Schlussfolgerungen im Kreise der Hardware Reviewer: „SP-CAPs sind keine POSCAPs!“ und „GPUs ohne MLCCs sind schlecht!“. Beide würde ich gerne kurz besprechen. Erstens, ihr kennt bestimmt „Tempos“? Genau, die Taschentücher. Im englischsprachigen Raum gibt es sowas ähnliches, nennt sich „Kleenex“. Selbes Prinzip, beide sind die Namen eines einzelnen Taschentuchproduktes, aber umgangssprachlich werden damit Taschentücher generell bezeichnet. Es klingt gut und es vor allem einfach. Ist es strenggenommen richtig? Nein. Aber macht es einen Unterschied. Auch nein.
Das gleiche lässt sich auch für POSCAPs und SP-Caps sagen. Obwohl das eine ein Produktname ist und das andere ein Begriff um eine bestimmte Kategorie von Kondensatoren zu bezeichnen, ist der Unterschied in diesem bestimmten Fall nicht wirklich wichtig. Falls das jetzt das OCD des einen oder anderen triggert, dann tut’s mir leid, aber so ist es.

Ziemlich bald nachdem Igor seinen ersten Artikel zum Thema veröffentlicht hatte (https://www.igorslab.de/en/what-real-what-can-be-investigative-within-the-crashes-and-instabilities-of-the-force-rtx-3080-andrtx-3090/), dass die Kondensator Konfiguration auf der Rückseite der GPU der „mögliche Grund“ – um das nochmal zu betonen – für die CTD Probleme sein könnte, veröffentlichte ein bekannter Youtuber ein Video, indem er „POSCAPs“ als billigere und schlechter Alternative zu MLCCs bezeichnete. Er schlussfolgerte daher, dass die Sparmaßnahmen der AIBs somit für das Auftreten der CTD verantwortlich wären. Selbstverständlich fehlte dieser Aussage Feingefühl und Tiefe, aber wenigstens brachte er so das Thema in der Industrie zur Sprache und kurz darauf brachen AIBs ihr Schweigen und veröffentlichten die ersten Stellungnahmen zum Thema. Also lasst uns ein paar dieser Statements ansehen. Zuerst EVGA:
“[…] During our mass production QC testing we discovered a full 6 POSCAPs solution cannot pass the real world applications testing. It took almost a week of R&D effort to find the cause and reduce the POSCAPs to 4 and add 20 MLCC caps prior to shipping production boards, this is why the EVGA GeForce RTX 3080 FTW3 series was delayed at launch. There were no 6 POSCAP production EVGA GeForce RTX 3080 FTW3 boards shipped. […] (ganze Stellungnahme hier: https://forums.evga.com/Message-about-EVGA-GeForce-RTX-3080-POSCAPs-m3095238.aspx)
Das ist der wichtigste Teil des Statements und lasst mich euch sagen wieso. Die Probleme traten nur im „“real world applications testing” auf, also wenn die Karten mit einem richtigen Treiber in einer echten Anwendung genutzt wurden. Und dieses Detail ist wichtig, da Nvidia, aus Angst vor Leaks, den AIBs Treiber erst eine Woche vor Markteinführung der RTX 3000 GPUs zur Verfügung stellte. Steve von GamersNexus meinte sogar, dass er die Treiber für sein Review bekommen hatte bevor sie AIBs zum Testen ihres eigenen Produktes bekommen hatten.
Also nochmal, ein Hersteller kann sein eigenes Produkt erst nach Reviewern testen, lasst dass mal sacken.
Jetzt lasst uns Gigabytes Stellungnahme ansehen:
“[…] 2. The GIGABYTE GeForce RTX 30 graphics cards are designed in accordance with NVIDIA specifications, and have passed all required testing, thus the product quality is guaranteed. GIGABYTE GeForce RTX 3080/3090 GAMING OC and EAGLE OC series graphics cards use high-quality, low-ESR 470uF SP-CAP capacitors, which meet the specifications set by NVIDIA and provide a total capacity of 2820u in terms of GPU core power, higher than the industry’s average. The cost of SP-CAP capacitors is not lower than that of MLCCs. GIGABYTE values product integrity highly and definitely does not reduce costs by using cheap materials. […] (ganzer Text kann hier gefunden werden: https://www.guru3d.com/news-story/gigabyte-releases-statement-regarding-the-sp-cap-and-mlcc-capacitor-on-geforce-rtx-3080-graphics-cards,4.html)
Da stecken sehr viele gute Infos drin. Als erstes, alle ihre RTX 3000 PCB Designs erfüllen die Nvidia Spezifikation. Das heißt, Nvidia wusste nicht oder hat den AIBs nicht gesagt, dass es Probleme mit der Strom-Zufuhr bzw. Glättung geben könnte, wenn auf einer GPU nur „POSCAPs“ verwendet werden, obwohl auf der „Referenzplatine“ PG132 5 „POSCAPs“ und 1 MLCC Gruppe eingesetzt werden.
Zweitens, Gigabyte sagt uns direkt wie viel Kapazität die Nvidia Spezifikation verlangt, nämlich 2820 uF, und dass alle Gigabyte Designs diese Vorgabe sogar übertreffen. Was aber nur kurz angerissen wurde ist der „ESR“, also der Innenwiderstand der verwendeten Kondensatoren, was die viel wichtigere Info ist, um das ganze CTD Phänomen zu verstehen. Um Igors Analogie aus einem anderen Artikel aufzugreifen (https://www.igorslab.de/en/nvidia-geforce-rtx-3080-und-rtx-3090-and-the-crash-why-the-capacitors-are-so-important-and-what-are-the-object-behind/): Sie haben uns zwar verraten, wie viel Wasser die Eimer fassen können, aber nicht, wie schnell die Wassereimer ausgeleert werden können. Leider wissen wir zu diesem Zeitpunkt noch immer nicht, ob es Vorgaben in der Referenz Spezifikation von Nvidia zu „ESR“ und „ESL“ gibt. Was wir aber sicher sagen können ist, dass diese Eigenschaften bei „POSCAPs“ nicht niedrig bzw. „schnell“ genug sind und daher die beschriebe Instabilität begünstigen können.
Drittens wird behauptet, dass „POSCAPs“ tatsächlich nicht billiger sind als MLCCs, und das stimmt auch. Man kann einfach selbst auf Seiten, die Kondensatoren verkaufen, nachsehen. Das Internet ist groß und Suchmaschinen sind euer Freund, wie es so schön heißt. Sogar wenn man in Betracht zieht, dass man 10 MLCCs braucht, um dieselbe Kapazität wie ein „POSCAP“ zu erreichen, sind die 10 MLCCs noch immer günstiger, wenn man von äquivalenter Qualität der Komponenten ausgeht. Was man aber noch anmerken muss ist, dass MLCCs aufgrund ihrer kleineren Bauform mehr Aufwand für die Pick and Place Maschinen bei der Montage auf der PCB mit sich bringen.
Das bringt mich dazu, noch kurz ein paar Worte zu Asus zu verlieren. Asus wurde gleich zu Anfang des ganzen Dramas gepriesen, weil sie angeblich das Problem hätten kommen sehen und als Gegenmaßnahme nur MLCCs in der Kondensator Konfiguration auf der GPU Rückseite verbaut hätten. Erinnert man sich noch ein paar Jahre zurück, als Asus extra beworben hat, dass sie jetzt Grafikkarten als erster AIB vollautomatisiert herstellen können und damit besser und konstantere Qualität garantieren können? Jedenfalls war Asus schon immer gut darin, Herstellungsprozesse zu optimieren und die Kosten zu minimieren.
Wenn man jetzt noch bedenkt, dass MLCCs günstiger im Einkauf sind und dass es vielleicht eine Vorahnung zu dem CTD Problemen gab, was aber keiner testen konnte, liegt die Schlussfolgerung nahe, dass hier mit Atombomben auf Fliegen geworfen wurde. Es wurden einfach nur MLCCs verbaut, in der Hoffnung das Problem damit sicher zu erschlagen. Und das gelang Asus ja wohl auch oder zumindest gab es weitaus weniger Berichte von CTD Problemen bei Asus Karten.

Also hat Asus das Problem kommen sehen? Wahrscheinlich. Aber hat Asus bessere Arbeit beim Testen ihres PCB Designs geleistet? Nein, wie auch, wenn kein AIB die Treiber zum Testen hatte.
GPU Bins – eine Silizium Lotterie mit schwerwiegenderen Folgen als üblich
Noch vor der Markteinführung von Ampere, hatte es Igor schon geschafft, an ein paar sehr interessante Infos zum Binning von Ampere GPUs zu gelangen. Was ist Binning? Um es einfach zu erklären, Computer Chips herzustellen ist sehr sehr schwierig und es ist unmöglich konstante Qualität zu erzielen, wenn man gleichzeitig auch noch die bestmögliche Leistung und Effizienz haben möchte. Dadurch kommt es unabdingbar zu Varianzen in der Herstellung von GPU zu GPU. Um dem entgegen zu wirken, definiert ein Hersteller gewisse Mindestkritierien, die jede einzelne GPU erfüllen muss, bevor sie ein eine Grafikkarte verbaut werden darf.
Bei Ampere wurde das sogar noch eine Stufe weiter getrieben, indem es 3 verschiedene Qualitätsabstufungen über den Mindestanforderungen gibt. Diese lauten:
- Bin 0 – die schlechtesten der Auslese, aber immer noch gut genug
- Bin 1 – so das Mittelmaß, besser als Bin 0, aber noch immer nicht toll
- Bin 2 – das beste was von der Produktionslinie abfällt
Je besser der Bin, desto weniger Spannung und damit Energie braucht eine GPU um bei einem bestimmten Takt stabil zu sein. Zum Beispiel würde eine Bin 0 GPU für 2000 MHz 1V brauchen, eine Bin 1 GPU nur 0.95V und eine Bin 2 GPU nur 0.90V. Wer noch mehr Infos zum Ampere Binning haben möchte, findet Igors Artikel dazu hier: https://www.igorslab.de/en/chip-is-not-equal-to-chip-first-information-on-the-possibility-to-binning-and-dispersal-at-the-force-rtx-3080-andrtx-3090/
Damit jetzt aber jede Karte funktioniert, muss Nvidia natürlich die Treiber so konzipieren, dass immer Stabilität gewährleistet ist, egal mit welchem Bin an GPU. Hierfür werden die angesprochenen Mindestkriterien verwendet und auf Basis dessen und ein paar anderer Parameter wie Leistungsbudget, Temperatur etc. wird dann der Boost Algorithmus so abgestimmt, dass jede GPU die Spannung je Frequenz bekommt, bei der auch jede Bin 0 GPU stabil läuft. Und das hat Nvidia auch genauso gemacht. Auf der Referenz PCB war jedes Stück Ampere Silizium mit dem Launch Treiber stabil.
Was man jetzt noch dazu sagen muss, ist das Ampere GPUs vor dem Launch nur sehr begrenzt verfügbar waren und AIBs einfach keine Zeit hatten, sich Bins für spezielle Modellvarianten auszusuchen. Das einzige was sie machen konnten war einfach jede GPU, die sie kriegen konnten, auf PCBs mit dem effizientesten Design zu packen, Kühler und Leistungsbudget drauf zu klatschen und zu hoffen, dass die Karten dann auch so skalieren wie gedacht. Das bringt uns zum heißesten Teil der Diskussion in letzter Zeit, den Treibern.
Boost, boost, boost – warum „Specs” nicht “stock” ist und “stock” instabil war, manchmal
Moderne GPUs laufen nicht mehr mit einer festen Taktrate, sondern werden stattdessen von einem sehr komplizierten Boost Algorithmus gesteuert, was Igor hier im Detail erklärt hat: https://www.igorslab.de/en/nvidia-geforce-rtx-3080-und-rtx-3090-and-the-crash-why-the-capacitors-are-so-important-and-what-are-the-object-behind/
Das wird gemacht, damit GPUs immer möglichst effizient laufen und die maximale Leistung abliefern, die unter Berücksichtigung der umliegenden Parameter wie GPU Auslastung, GPU Qualität, Kühler Qualität, Raumtemperatur etc. je Situation möglich ist. Nvidia gibt die RTX 3080 Boost-Takt Spezifikation als 1.71 GHz an, aber fast jede 3080, sogar AIB Varianten mit PCBs ähnlich der Referenz Spezifikation, laufen mit viel höheren Taktraten unter Last. Manche GPUs boosten sogar auf über 2 GHz am Anfang eines Workloads und mit steigenden Temperaturen pendeln sie sich dann bei 1.8 bis 1.9 GHz ein, ohne dass der User auch nur an Übertakten gedacht hat.
Wieso? Weil wie gerade erklärt, der Boost Algorithmus denkt, unter Berücksichtigung aller Parameter, dass er diese höhere Taktung gefahrlos erreichten kann. Laufen diese GPUs denn jetzt mit den „Specs“ Taktraten? Nein. Aber laufen Sie „stock“, also wie es der Hersteller vorgesehen hat? Ja. Und als Verbraucher kann man erwarten, besonders bei einem Neupreis von 700 bis 2000 Euro, dass die Karte dann auch stabil läuft und nicht abstürzt, wenn man sie einfach nur kauft und in den eigenen PC einbaut ohne zu übertakten, auch wenn die Nvidia Spezifikationen zu den Taktraten automatisch überschritten werden.
Also woher weiß der Treiber bzw. Boost Algorithmus wie diese Parameter aussehen müssen und wie hoch getaktet werden kann? Daten, es sind einfach nur Daten. Wie vorhin erklärt, binnt Nvidia jede GPU und überprüft wie viel Spannung eine GPU für eine gewisse Taktung bei einer gewissen Temperatur braucht. Dann nehmen sie die gesammelten Daten her, um den besagten Boost Algorithmus so zu bauen, dass auch die schlechtesten Bin 0 GPUs auf der Referenz PCB stabil laufen.
Aber wenn der Treiber doch stabil mit jeder GPU laufen sollte, warum kam es dann zu den CTD Problemen und warum war der Boost Algorithmus im Launch Treiber „zu optimistisch“?
Letztendlich liegt es am e-peen, von Herstellern und Verbrauchern. Denn am Launchtag wollen alle Hersteller ihren Kunden das vermeintlich beste Produkt fürs Geld verkaufen und einer der einfachsten Wege um sich von der Konkurrenz abzusetzen ist nun mal das Erhöhen des out-of-the-box Boost-Taktes, effektiv ein Vor-Übertakten ab Werk. Auch wenn es nur 30 MHz extra sind zum selben Preis wie eine Referenzkarte, macht das für viele Käufer den Unterschied, besonders für jene, die nicht so sehr in der Materie drin stecken oder selber übertakten möchten.
So und wie kommen die AIBs jetzt zu diesen extra 30 MHz, wenn doch der Boost vom Nvidia Treiber gesteuert wird? Nun, sie können die Boost Offsets nicht ändern, die sind fest, aber was sie ändern können ist der Basistakt, also im Prinzip ein Offset auf die Nvidia Spezifikation draufgeschlagen, und damit auch noch zusätzlich zu den Standard Nvidia Boost Offsets. Das macht man in der Industrie schon immer so, seitdem GPU-Boost vor einigen GPU Generationen eingeführt wurde.
Aber mit dem Launch von Ampere war eben eine entscheidende Sache anders. Wie hinlänglich besprochen hatten die AIBs keine Treiber zum Testen ihrer Karten unter einem schweren Gaming Workload mit Windows und DirectX. Stattdessen mussten sich die AIBs auf Daten von vorherigen GPU Generationen verlassen und zusammen mit der Nvidia Referenz Spezifikation ableiten, wie weit man Ampere mit den Übertaktungen ab Werk denn so treiben kann, und damit ein Risiko eingehen. Was hätten die AIBs denn sonst auch machen sollen, ihre höherwertigen Karten verschieben bis nach dem Launch? Kein Hersteller könnte sich leisten den Launch Day Hype zu verpassen, während alle anderen Hersteller daraus Kapital schlagen.
Ich will an dieser Stelle auch noch ein paar Worte zu den Linux Treibern verlieren. Keine Sorge, dafür muss man sich nicht auf der Kommandozeile auskennen und ich fasse mich auch kurz. Ein paar andere Medien sind zu dem Schluss gekommen, dass die CTD Problematik alleinig durch einen fehlerhaften Windows Treiber verursacht worden sein musste, weil das CTD Verhalten zum Launch auf Linux nicht zu beobachten war. Naja, so einfach ist es leider auch hier nicht, denn Windows Treiber sind hoch optimierte Gebilde, die über Jahre weiterentwickelt und tief in Windows 10 und DirectX integriert wurden. Die Linux Treiber hingegen sind viel rudimentärer gehalten und mangels Marktanteil auch bei weitem nicht so sehr optimiert. Das heißt mit dem äquivalenten Workload wird man eine GPU i.d.R. auf Windows immer mehr belasten als auf Linux, ein paar Randfälle ausgeschlossen.
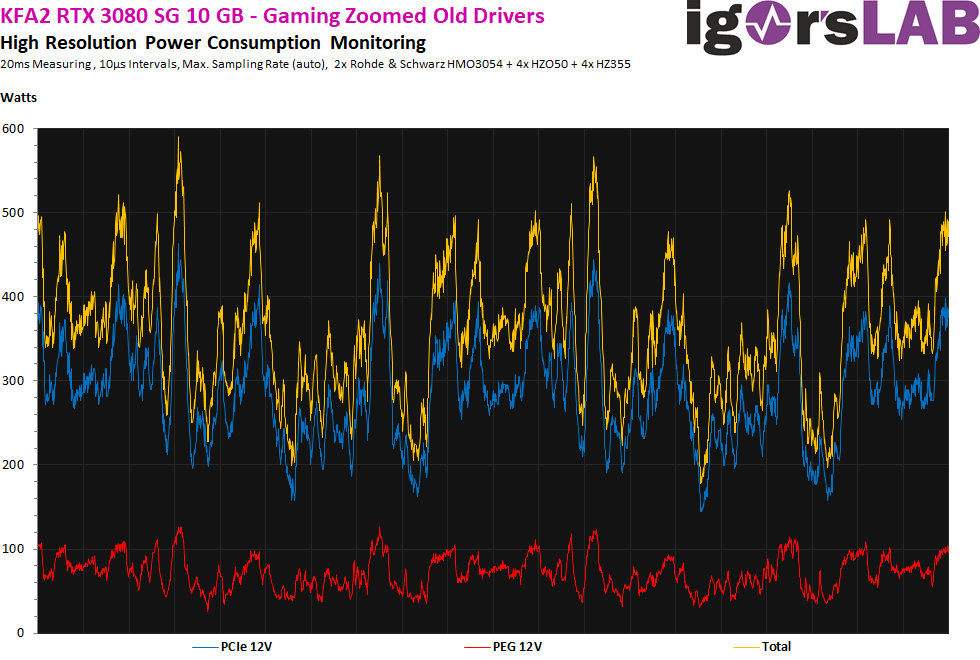
Netzteile – die vergessen Opfer der ganzen Geschichte
Als zum ersten Mal Meldungen über CTD Probleme im Forum bei LTT und Computerbase bekannt wurden, gab es eine Gemeinsamkeit unter den Posts: alle hatten Netzteile von ansehnlichen Marken wie Corsair oder EVGA mit einer angegebenen Ausgangsleistung von 750 bis 850 Watt. Igor hatte auch ein Problem mit Netzteilen, als er den RTX 3080 Launch Review vorbereitete. Details dazu gibt es hier: https://www.igorslab.de/en/wonder-how-invidia-the-crashes-of-the-force-rtx-3080-andrtx-3090-will-be-removed-and-still-will-be-removed-even-from-the-power-supplies-analysis/.
Kurz gefasst, das Seasonic 1200W Netzteil, dass er liebevoll „Nils“ nennt hat UVP (under voltage protection) ausgelöst, immer dann wenn die GPU eine große transiente Belastung erfahren hat. Die Lösung? Ein Tausch der Seasonic 1200 W Einheit gegen ein neueres Modell mit gleicher Nennleistung, aber mit einer langsameren UVP Abschaltvorrichtung auf der 12V Schiene. Das klingt vielleicht erstmal unlogisch, würde man nicht ein Netzteil mit schnelleren Schutzvorrichtungen haben wollen? Generell schon, aber auch nicht, wenn man Hardware einsetzt, die sich zumindest kurzzeitig nicht an die ATX Spezifikation hält.
CPUs und GPUs wurden in den letzten 5 bis 10 Jahren immer stromfressender und an den Netzteil-Herstellern ist dieser Trend auch nicht spurlos vorüber gegangen. Immer wenn die Last auf einer Stromschiene schlagartig ansteigt, sinkt die Spannung ab, auch bekannt als Spannungsabfall. In manchen Fällen, wie z.B. bei Vcore will man das, um die Hardware zu schützen, aber im Fall der 12 V Schiene des Netzteils möchte man eigentlich immer exakt 12V haben. Also steuert das Netzteil gegen und erhöht effektiv die Ausgangsspannung, um der Last entgegen zu wirken. Das dauert aber einen Moment, ein paar Millisekunden, lange genug, dass die 12 V Schiene z.B. auf 11,5 V abfällt. Verhindern lässt sich das nicht, man kann nur abwarten und den Abfall so gut wie möglich mit Kondensatoren auf der Ausgangsseite auffangen, bis die Regelung im Netzteil die Spannung wieder für die Last angepasst hat. Anders gesagt, man muss dem Netzteil mehr Zeit zum Reagieren geben, bevor UVP auslöst.
Also was sagt uns das alles denn jetzt? Die ATX Netzteil Spezifikation ist alt, sehr alt. Netzteil Hersteller mussten Lösungen wie das Verzögern vom UVP und viele weitere implementieren, um die Kompatibilität zwischen ATX Netzteilen mit moderner Hardware zu wahren. Auf der anderen Seite sind Ampere Grafikkarten die leistungshungrigsten GPUs der letzten Jahre mit 370W für die 3090 Founders Edition und sogar weit mehr als 400W für AIB Varianten.
Aber jetzt sagen manche: Es gab doch früher schon Karten mit so viel Stromverbrauch, z.B. die GTX 480! Und das stimmt, aber damals hatten die Karten einen konstanten Takt mit konstanter Spannung, nicht den hibbeligen Boost Algorithmus der heutigen Karten, wo hundert Mal in der Sekunde Takt und Spannung angepasst werden.
Interkompatibilität ist ein Segen und ein Fluch für PC Komponenten, war es schon immer, und hier kam eben letzteres zum Tragen.
Wir können also daraus schließen, dass Ampere Grafikkarten so leistungshungrig sind, dass sie Netzteile voll auslasten und in manchen Fällen sogar überlasten, sogar die stärksten und hochwertigsten Modelle von Seasonic, EVGA und Corsair.
Fazit – es ist keine 1 zu 1 Kausalbeziehung, es ist eine Gleichung!
„Die Kondensator Konfigurationen der AIBs sind schuld!“, „Die Treiber waren nicht für Ampere abgestimmt!“, „Du solltest ein besseres Netzteil für eine 3080 kaufen!“, „Nvidia ist mit fehlerhaften Chips in den Launch gegangen!“, sind alles Aussagen, die ich in den letzten Tagen und Wochen von Youtubern, Usern auf Reddit und in unserem eigenen Forum gelesen habe. Und zu all diesen Aussagen entgegne ich folgendes: „Ihr liegt alle falsch und gleichzeitig richtig.“
Wir hatten Nvidia, die den Launch gehetzt und versucht haben, Ampere so schnell wie möglich auf den Markt zu bringen. Wir hatten AIBs, die versucht haben das PCB Design zu maximieren und zu verbessern, was Nvidia als Specs genannt hatte, aber ohne Treiber um auch wirklich die Funktionsfähigkeit zu testen. Wir haben bis heute eine große Knappheit an Ampere Chips, wodurch es sogar die schlechtesten Bin 0 GPU auf den Markt schafften. Wir haben Leistungsaufnahmen die die letzten 5 Generationen von Nvidia GPUs übertreffen, mit der größten Belastung für Stromversorgung der letzten Jahre. Und all das soll auch noch rückwärtskompatibel mit bestehenden ATX Netzteilen bleiben, die seit 10 Jahren im PC von Enthusiasten verbaut sind. Was hätte da bloß schief gehen sollen?!
Wenn man diese ganzen Faktoren mal zusammen nimmt, dann ist es eigentlich ein Wunder, dass nicht mehr schief gelaufen ist bei der Markteinführung von Ampere. Kann man die Schuld den AIBs geben, die keine Treiber während der Produktion hatten, um ihre Karten ordentlich zu testen, teilweise sogar erst nachdem Reviewer die Treiber erhalten hatten? Ich denke nicht. Man kann von den AIBs nicht erwarten, dass sie ihr eigenes Produkt verschieben, wenn alle anderen ihre Karten am Launch Day in den Regalen stehen haben. Was ihnen übrig blieb war, sich an die Nvidia Timeline zu halten, ordentliche Tests zufahren sobald es ihnen möglich war und in den letzten Minuten noch Änderungen zu machen falls notwendig.
Kann man AIBs wie Gigabyte die Schuld geben, die keine Änderungen mehr an ihren 6 „POSCAP“ Designs kurz vor knapp gemacht haben? Nicht wirklich, denn an die Nvidia Specs haben sie sich gehalten, zu diesem Zeitpunkt waren sie wahrscheinlich schon mitten in der Produktion, und ohne dass es abzusehen war, verhielten sich die Karten in den Händen von Kunden anders als erwartet. Gesteht man sich Schuld ein, wenn man faktisch keine andere Wahl hatte? Ich denke nicht. Also hat Gigabyte ihren Kunden gesagt, dass ihr Design nicht Schuld ist und dass sich Kunden bitte den neuen Treiber installieren mögen, der dann auch mit jedem Modell funktioniert.
Kann man die Schuld Netzteil Herstellern zuschieben, die sich gleichzeitig an die ATX Spezifikation halten müssen und neue Grafikkarten mit Lastspitzen von 500 bis 600 W unterstützen sollen? Nein, eigentlich sollte man froh sein, wenn das Netzteil abschaltet, wenn eine PC-Komponente zu viel Leistung zieht und Spannungsabfall verursacht. Am Ende des Tages muss das Netzteil auch alle anderen Komponenten im PC schützen und keinen Brand verursachen.
Also lasst und über das offensichtliche sprechen. Die Kombination aus den meisten AIB PCB Designs und Launch Treibern von Nvidia waren nicht adäquat für jedes Stück Ampere Silizium, nicht mehr, nicht weniger. Wenn der Treiber die GPU auf über 2 GHz taktet, dann muss eben die PCB in der Lage sein genug Strom schnell genug zur GPU zu liefern, damit diese stabil bleibt. Aber wie Igor schon im Folgeartikel über Kondensatoren erwähnte (https://www.igorslab.de/en/nvidia-geforce-rtx-3080-und-rtx-3090-and-the-crash-why-the-capacitors-are-so-important-and-what-are-the-object-behind/), Nvidia gibt nicht vor welche Kondensatoren die AIBs verwenden müssen, nur wie viel Kapazität die Kondensatoren insgesamt haben müssen. Also ist „genug Strom“ abgedeckt, aber „schnell genug“ nicht. Im Ergebnis ist die Energie zwar in den Kondensatoren hinter der GPU gespeichert, kann aber nicht schnell genug abgegeben werden, wenn sie benötigt wird.
Als ein Nebeneffekt des hibbeligen Boostverhalten, wenn man das Glück hatte, dass GPU bin, Kondensator Konfiguration und der Boost Algorithmus des Treibers zusammen harmoniert haben, hatte man noch immer eine Chance, dass dem Netzteil auffällt, dass sich die GPU zu lange nicht an die ATX Spezifikation hält, und in Folge dessen abschaltet um das ganze restliche System zu schützen. Die ATX Specs ausreizen, den Launch zu hetzen und und AIBs keine Treiber zum Testen zu geben, um Leaks zu verhindern ist ein Rezept für Fehlverhalten.
Aber kann man jetzt einfach Nvidia die Schuld dafür geben? Can man ihnen ankreiden, dass sie eine Referenz PCB und einen Treiber entworfen haben, die zusammen fehlerfrei funktionieren, wenn dann AIBs versuchen das Design zu optimieren und maximieren, um für den Kunden eine größere Zahl auf den Karton schreiben zu können? Nein, ich denke Nvidias Schuld war es also auch nicht. In eine hypothetischen Welt, in der AIB Karten mit Referenz Platine und die Founders Edition existieren, gäbe es die CTD Probleme erst gar nicht.
Also wenn man wirklich die Schuldfrage stellen möchte, dann muss die Antwort einfach lauten: alle – Nvidia, AIBs, Leaker, Influencer, Händler, Verbraucher. Jeder ist ein Stück weit mit verantwortlich dafür, warum die Industrie so funktioniert, wie sie es tut.
Zugabe – Was wir alle daraus lernen können
Lasst uns zuerst über die Industrie reden, über „Enthusiasten“ und wie generell mit dem Thema umgegangen wurde. Wenn jemand den ersten Artikel über den „möglichen Grund“ für die CTD Probleme veröffentlicht, macht man bitte kein Video mit Referenz auf den Artikel, mit der Schlussfolgerung, dass „POSCAPs“ billiger als MLCCs wären und dass eine Lösung nur in Hardware oder durch Flashen eines neuen BIOS implementiert werden kann, wenn einem doch gar nicht alle Informationen für solche Schlussfolgerungen vorliegen.
Denn so verbreitet man nicht nur Fehlinformationen an das eigene Publikum und die Community, sondern man schadet auch der ursprünglichen Quelle der Diskussion, indem man diese in einen Position bringt, wo sie sich für Aussagen rechtfertigen muss, die sie gar nicht getroffen hat.
Wenn man sich selbst als „Enthusiast“ bezeichnet, dann sollte man ein so komplexes Hardware Thema nicht einfacher machen als es nun mal ist und keine voreiligen Schlüsse ziehen. Stattdessen sollte man einen Schritt zurück treten um das große Ganze zu sehen, zu versuchen andere Blickwinkel zu verstehen als den eigenen als Konsument, anstatt einer einzelnen Partei die ganze Schuld zuzuschieben. Wenn man sich wirklich als „Enthusiast“ bezeichnen möchte, sollte man sich an einem höheren Standard messen.
Zweitens, wenn der CEO eines multi-Milliarden-Dollar-Halbleiter-Unternehmens auf einmal einen Deal anbietet, der zu gut ist um wahr zu sein, sollte man misstrauisch werden, anstatt blind dem Hype zu verfallen. Es ist ja verständlich, dass man aufgeregt wird, wenn man Behauptungen hört, wie „3080 hat doppelte Leistung wie 2080, for 699 USD“, und dass man sofort mit einer dieser vermeintlichen Wunderkarten seine eigene Gaming Experience aufwerten möchte. So ging es mir ja auch! Aber an einem gewissen Punkt muss man aufwachen und realisieren, dass es Gründe gibt, wie und warum so ein Deal zustande kommt.
GPU Architekturen wie Ampere sind 5 bis 6 Jahre in der Mache, viele Generationen im Voraus. Ampere wurde wahrscheinlich schon erdacht, als Maxwell vor über 6 Jahren gelauncht wurde. Und am Ende eines solch langen Entwicklungszyklus möchte man als Firma natürlich, dass sich die ganzen Aufwände lohnen, indem sich das Produkt sehr gut verkauft und man seine ganzen R&D Investitionen plus etwas Profit wieder verdient, bis zur nächsten Architektur und so weiter.
Was passiert jetzt also wenn auf einmal die Konsolen-Hersteller ihre neue Generation früher als erwartet marktreif machen, basierend auf einer neuen konkurrierenden Grafik-Architektur, mit versprochener 4K Gaming Leistung, von der man vor ein paar Jahren nicht mal zu träumen wagte? Vielleicht fängt man an sich Sorgen zu machen, dass sich die Entwicklungen aus den letzten 5 bis 6 Jahre auf einmal doch nicht so gut verkaufen werden wie erhofft, wodurch man den Launch der neuen Architektur nach vorne zieht, um so schnell und günstig wie möglich mit dem Verkauf zu beginnen und die R&D Kosten zumindest teilweise noch zu amortisieren.
Es klingt vielleicht weit her geholt, aber wenn man es schafft, seinen Wettbewerber so nervös zu machen, dann hat man entweder sehr gute Karten (Wortspiel nicht beabsichtigt) oder ein Wahnsinns-Pokerface. Wie dem auch sei, Oktober wird sicherlich ein sehr interessanter Monat für die Branche mit der Vorstellung AMD’s neuer CPUs und GPUs. Und Nvidia hat sich schon vorbereitet, indem die RTX 3070 einen Tag nach dem AMD RDNA2 Launch verschoben wurde und SKUs von 3080 und 3070 mit doppeltem VRAM bereits jetzt irgendwo in China in Kartons gepackt werden, während das hier geschrieben wird.
Ich persönlich werde noch ein paar Wochen länger meine 1080 Ti behalten, abwarten wie sich alles entwickelt und das Popcorn vorbereiten. Und ich schlage vor, ihr macht das gleiche. Es ist lange her, dass GPU und CPU Märkte gleichzeitig eng umkämpft waren. Und langfristig profitieren nur wir davon, die Verbraucher.
















Kommentieren