













Es sollte vorangestellt werden, dass die Unterschiede zwischen den Konfigurationen äußerst gering und daher in Form von Balken nur schwer darstellbar sind. Ganz unaufgerarbeitet wollte ich euch die Excel-Tapete aber auch nicht präsentieren, weshalb ich mich für einen Hybrid mit entsprechenden Datenlabels entschieden habe. Diese sind bereits die errechneten Durchschnittswerte mehrere Durchläufe, die so auch tatsächlich reproduzierbar sind, trotz Lauf zu Lauf Varianz der Software und relativ lautem Windows-Hintergrundrauschen.
Geekbench 3: Memory und Total Multi-Core
Geekbench 3 kennen wir ja bereits zu genüge aus den RAM-Kit Reviews, wobei wir dabei aber nur den Multi-Core Memory Score auswerten. Um einen weiteren Blickwinkel auf etwaige Wechselwirkungen im Benchmark zu haben, ist diesmal in den Daten jetzt auch der gesamte Multi-Core Score mit in der Auswertung. Der Benchmark legt bekanntlich hauptsächlich Wert auf den Durchsatz, kann aber auch größere Unterschiede bei der Latenz durchaus wahrnehmen.
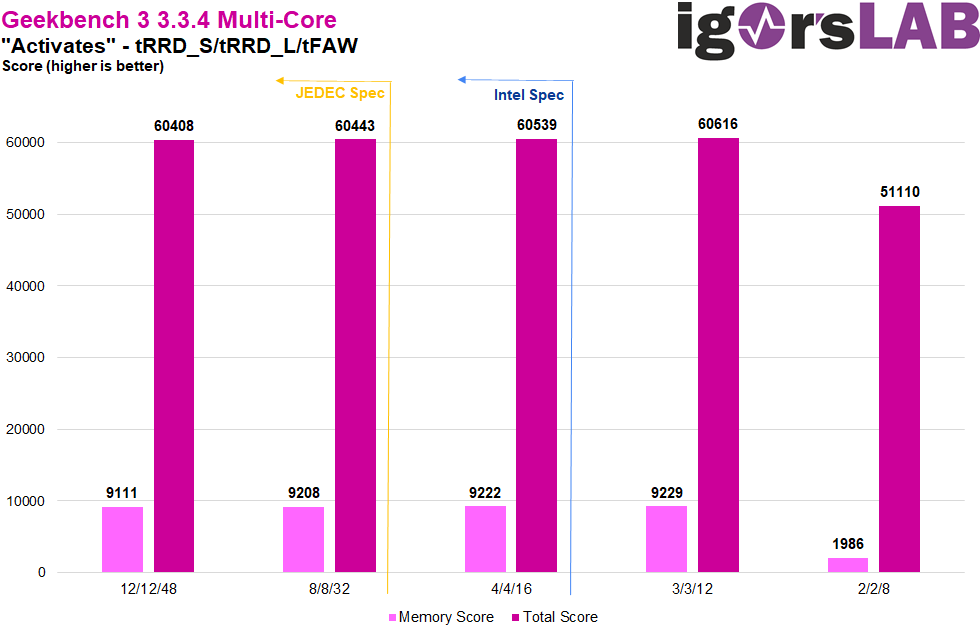
Tatsächlich lassen sich hier bereits die Activates in den Ergebnissen wieder erkennen. Während 12/12/48 klar am schlechtesten performt, können niedrigere Werte bessere Performance erzielen. Die Leistung skaliert dabei sogar unter die Spezifikationen von JEDEC und Intel hinaus, mit 3/3/12 als schnellste Konfiguration. Einziger Haken dabei ist, dass sich zumindest beim Z690 Tachyon diese Timings unterhalb der Intel Spec nicht im BIOS einstellen lassen. Stattdessen muss „Realtime Memory Timings“ aktiviert und die Einstellung im Windows mit Memtweakit vorgenommen werden. 2/2/8 ist dann aber doch zu weit ab vom Schuss, sodass es ab hier zu einem deutlichen Leistungseinbruch kommt.
SuperPi 32M
SuperPi ist bekanntlich ein äußerst Latenz-sensibler Benchmark, dem die Bandbreite schon fast egal ist. Wie bereits eingangs bemerkt, wird Hyperthreading deaktiviert, da die Kommunikation zwischen den Threads eine relativ hohe Inkonsistenz der Ergebnisse bewirkt und so den Durchschnitt verfälschen würde. Zudem wurden die Option Large Process Memory aktiviert und der Prozess an den zweiten der 8 Golden Cove Kerne gepinnt. So lassen sich mit dem längsten 32M Preset immerhin Unterschiede im Sekundenbereich messen.
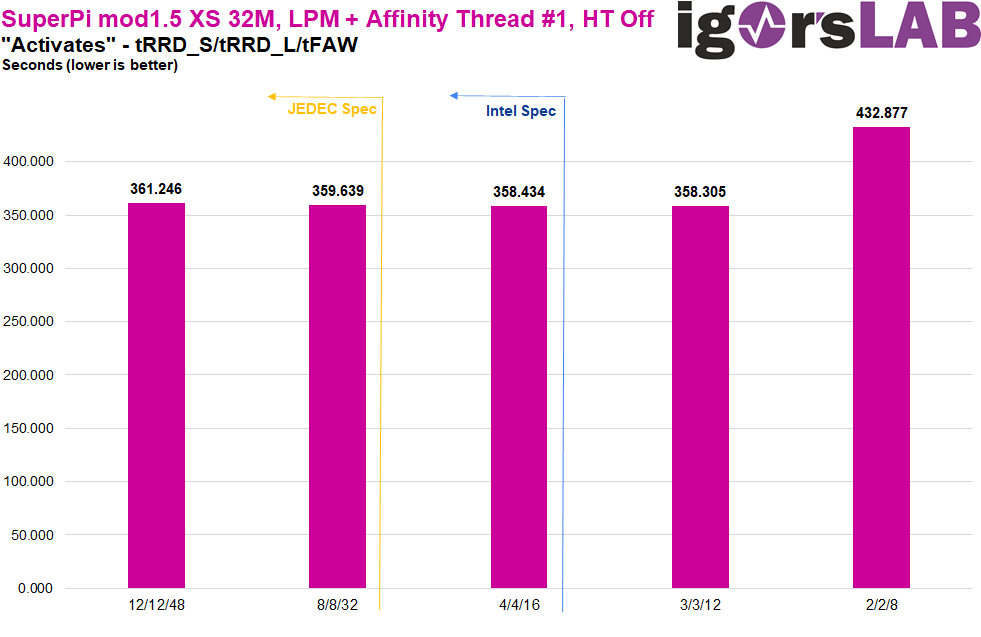
Ähnlich wie beim Geekbench 3 skaliert auch hier die Performance über die Spezifikationen von Intel und JEDEC hinaus, mit dem Klimax bei 3/3/12. 2/2/8 läuft auch hier wieder in eine Art „Notlauf“ mit deutlich schlechterer Performance. Und auch wenn hier die Ergebnisse teilweise um die eine oder andere Sekunde aus der Reihe tanzen, bestätigt sich der Performance-Zugewinn mit niedrigeren Timings auch hier.
Bootable Linpack Xtreme 1.1.5 (Porteus)
Das bootbare Linpack Xtreme 1.1.5 basiert auf dem Porteus Betriebsystem, was wiederum eine extrem kleine und leichtgewichtige Linux-Distribution ist. Dies macht es perfekt für möglichst akkurate Messungen mit dem Linpack Xtreme Benchmark, der sonst mit Windows als Unterbau gerne einmal mehrere Prozentpunkte zwischen Läufen schwankt. Leider hat das Linux-OS aber auch einen Nachteil, da Memtweakit hier nicht funktioniert und ich somit keine Timings unterhalb der Intel Spec kann.
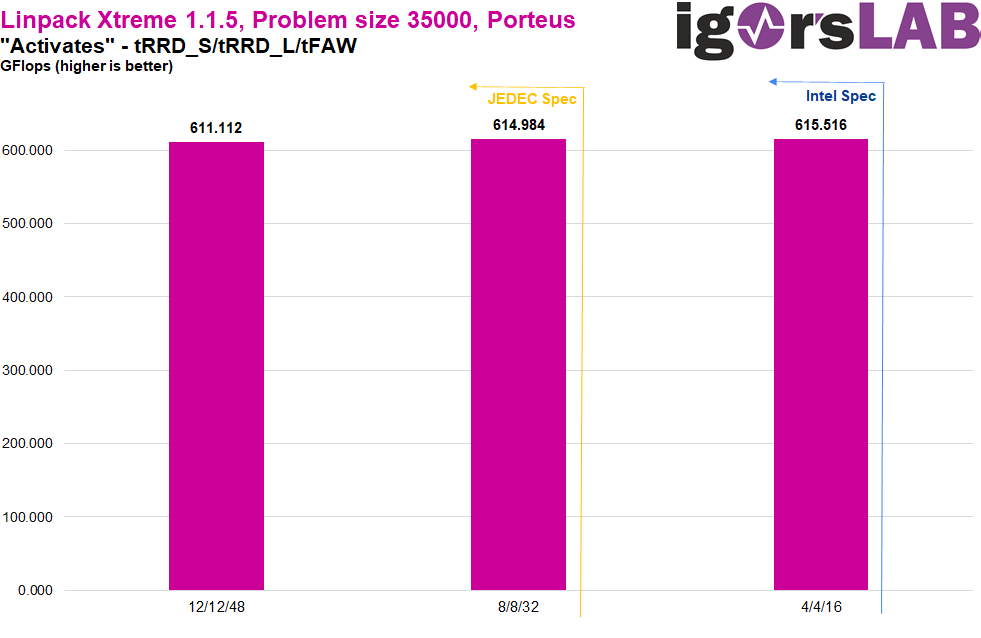
Im Linpack Xtreme bestätigt sich das Bild der höheren Performance mit niedrigeren Activate Timings ebenfalls. Hier ist aber 12/12/48 deutlich schlechter relativ zu 8/8/32, als 8/8/32 relativ zu 4/4/16. Wenn wir auch nochmal genau bei den vorherigen Benchmarks hinsehen, ist dieses Phänomen dort ebenfalls vorhanden, nur in geringerem Ausmaß. Es scheint hier also „diminishing returns“ zu geben, wobei sich der Leistungszugewinn nicht proportional zur theoretischen Zeitersparnis des Timings verhält.
y-cruncher 2.5b
Abschließend gibt es wie angedroht noch den y-cruncher mit Preset 2.5b, bereitgestellt von Benchmate. Die Last auf RAM und CPU ist dabei ähnlich wie bei Linpack Xtreme, nur dass wir hier wieder mit Windows und Memtweakit auch unterhalb von 4/4/16 testen können. Da dieser Benchmark die Tendenz hat, von Lauf zu Lauf schneller zu werden, wurde für jeden Testlauf eine neue Instanz gestartet. Zudem wurde als Memory Allocator „Interleave NUMA Nodes“ Und als Parallel Framework „C++11 async“ für maximale Performance auf der Z690 Plattform verwendet.
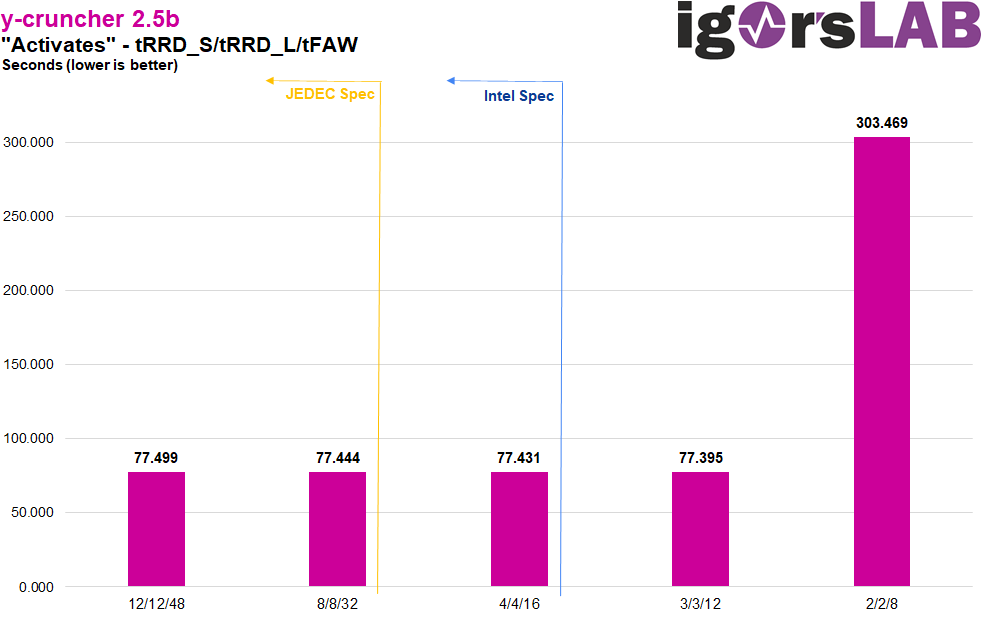
Auch hier zeigt sich wieder das selbe Muster mit Performance-Skalierung bis 3/3/12 und „diminishing returns“ je niedriger die Timings werden. Auch der Notlauf bei 2/2/8 schlägt hier wieder zu, sogar stärker als in allen anderen Benchmarks. Da y-cruncher vor allem Bandbreite bevorzugt und geringeren Wert auf die Latenz legt, lässt sich hier ein Zusammenhang vermuten. Womöglich lässt der IMC hier nur noch 1 von 4 Activates überhaupt zu, was eine ca. 4-mal höhere Benchmarkzeit erklären könnte – das ist aber wirklich nur Spekulatius meinerseits.


















8 Antworten
Kommentar
Lade neue Kommentare
Urgestein
Urgestein
Veteran
Mitglied
Urgestein
Urgestein
Urgestein
Urgestein
Alle Kommentare lesen unter igor´sLAB Community →