











Auf der Computex 2023 in Taipeh, Taiwan, verkündete Jensen Huang, CEO von Nvidia, dass die Grace-Hopper-Superchips des Unternehmens nun in vollem Umfang produziert werden. Die Grace-Plattform hat bereits sechs Supercomputer-Wettbewerbe erfolgreich für sich entschieden. Als Teil dieser aufregenden Entwicklung stellte Huang auf der Computex 2023 die neue KI-Supercomputing-Plattform DGX GH200 vor.
Diese Plattform, die speziell für massive generative KI-Workloads entwickelt wurde, ist ab sofort mit 256 Grace Hopper Superchips erhältlich. Diese Chips arbeiten gemeinsam als ein leistungsstarkes Supercomputing-System mit 144 TB gemeinsam genutztem Speicher, um selbst die anspruchsvollsten generativen KI-Trainingsaufgaben zu bewältigen. Namhafte Unternehmen wie Google, Meta und Microsoft haben bereits ihr Interesse an diesen fortschrittlichen Systemen von Nvidia bekundet.

Darüber hinaus gab Nvidia die Einführung seiner neuen MGX-Referenzarchitekturen bekannt. Diese Architekturen werden OEMs dabei unterstützen, neue KI-Supercomputer noch schneller zu entwickeln. Dabei sind mehr als 100 Systeme verfügbar. Zudem präsentierte das Unternehmen die Spectrum-X Ethernet-Netzwerkplattform, die speziell für KI-Server und Supercomputing-Cluster entwickelt und optimiert wurde. Mit dieser Plattform bietet Nvidia eine hochmoderne Lösung für die Vernetzung von KI-Systemen und Supercomputern. Tauchen Sie ein in die Zukunft der Technologie!







Grace-Hopper-Superchips jetzt in Produktion bei Nvidia

Es wurde bereits umfangreich über die Superchips Grace und Grace Hopper berichtet, die in der Vergangenheit vorgestellt wurden. Diese Chips sind von zentraler Bedeutung für die neuen Systeme, die von Nvidia heute angekündigt wurden. Der Grace-Chip fungiert als Nvidias eigener Arm-CPU-Prozessor, während der Grace Hopper Superchip die Grace-CPU mit einem Hopper-Grafikprozessor, 72 Kernen, 96 GB HBM3 und 512 GB LPDDR5X in einem Gehäuse vereint. Mit insgesamt 200 Milliarden Transistoren ist dieser Superchip ein technisches Schwergewicht. Die Kombination aus Grace-CPU und Hopper-GPU ermöglicht eine beeindruckende Datenbandbreite von bis zu 1 TB/s zwischen beiden Komponenten. Dieser hohe Durchsatz erweist sich insbesondere bei speicherintensiven Workloads als enormer Vorteil.
Angesichts der Tatsache, dass die Grace-Hopper-Superchips nun in Produktion sind, können wir davon ausgehen, dass Systeme von verschiedenen Nvidia-Partnern wie Asus, Gigabyte, ASRock Rack und Pegatron verfügbar sein werden. Besonders erwähnenswert ist, dass Nvidia auch eigene Systeme einführen wird, die auf den neuen Chips basieren. Darüber hinaus wird das Unternehmen Referenzdesign-Architekturen für OxMs und Hyperscaler veröffentlichen, auf die wir weiter unten eingehen werden.
Nvidia DGX GH200 Supercomputer
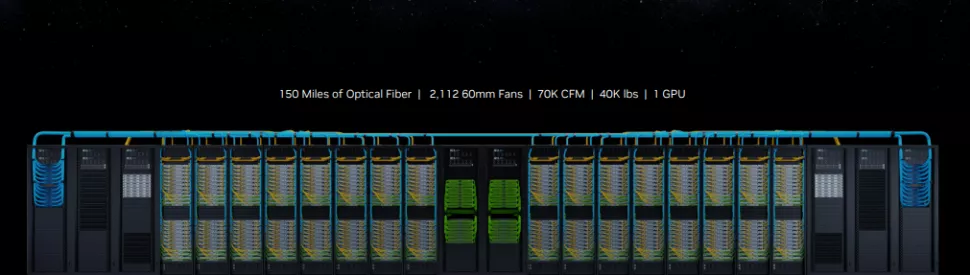

Die DGX-Systeme von Nvidia sind die führende Wahl für hochleistungsfähige KI- und HPC-Workloads. Allerdings sind die aktuellen DGX A100-Systeme auf acht A100-GPUs beschränkt, die als eine Einheit zusammenarbeiten. Angesichts des rapiden Wachstums im Bereich der generativen KI besteht bei den Kunden von Nvidia ein großer Bedarf nach leistungsstärkeren Systemen mit erheblich mehr Kapazität. Deshalb wurde der DGX H200 entwickelt, um eine enorme Skalierbarkeit und ultimativen Durchsatz für anspruchsvollste Workloads wie generatives KI-Training, große Sprachmodelle, Empfehlungssysteme und Datenanalyse zu bieten. Dabei werden die Einschränkungen herkömmlicher Cluster-Verbindungsoptionen wie InfiniBand und Ethernet durch den Einsatz von Nvidias maßgeschneidertem NVLink Switch-Silizium umgangen.
Obwohl die genauen Spezifikationen des neuen DGX GH200 KI-Supercomputers noch nicht bekannt sind, wissen wir, dass Nvidia ein neues NVLink-Switch-System verwendet. Dieses System besteht aus 36 NVLink-Switches der dritten Generation, um 256 GH200 Grace Hopper Chips und einen gemeinsamen Speicher von 144 TB zu einer einheitlichen Struktur zu verbinden. Dadurch entsteht eine massive Recheneinheit, die sowohl optisch als auch in ihrer Leistung einem riesigen Grafikprozessor gleicht.
Der DGX GH200 ist mit insgesamt 256 Grace Hopper CPU+GPUs ausgestattet und übertrifft damit deutlich Nvidias bisher größtes NVLink-verbundenes DGX-System mit acht GPUs. Im Vergleich zu den DGX A100 Systemen, die nur 320 GB Shared Memory zwischen acht A100 GPUs bieten, verfügt der DGX GH200 über beeindruckende 144 TB Shared Memory, was einer 500-fachen Steigerung entspricht. Im Gegensatz zur Erweiterung des DGX A100 Systems auf Cluster mit mehr als acht GPUs, bei der InfiniBand als Verbindung zwischen den Systemen eingesetzt wird und zu Leistungseinbußen führt, hat Nvidia mit dem DGX GH200 erstmals einen vollständigen Supercomputer-Cluster um die NVLink-Switch-Topologie herum aufgebaut. Dieser Cluster bietet laut Nvidia eine bis zu zehnmal höhere GPU-zu-GPU-Bandbreite und eine siebenmal höhere CPU-zu-GPU-Bandbreite im Vergleich zur Vorgängergeneration. Zusätzlich bietet er eine 5-mal höhere Verbindungseffizienz gegenüber konkurrierenden Verbindungen und eine bisektionale Bandbreite von bis zu 128 TB/s.
Obwohl das System 150 Meilen Glasfaserkabel benötigt und ein Gewicht von 40.000 Pfund aufweist, wird es dennoch als eine einzige GPU betrachtet. Nvidia behauptet, dass die 256 Grace Hopper Superchips dem DGX GH200 eine “KI-Leistung” im Bereich von Exaflops verleihen, wobei dieser Wert mit kleineren Datentypen gemessen wird, die für KI-Workloads relevanter sind als die FP64-Messungen, die in HPC und Supercomputing verwendet werden. Diese beeindruckende Leistung wird durch eine GPU-zu-GPU-Bandbreite von 900 GB/s erreicht. Die Skalierbarkeit des Systems ist besonders bemerkenswert, da Grace Hopper einen maximalen Durchsatz von 1 TB/s mit der Grace-CPU erreicht, wenn sie direkt auf demselben Board über den NVLink-C2C-Chip-Interconnect verbunden ist.
Nvidia hat Benchmarks des DGX GH200 mit dem NVLink Switch System veröffentlicht, wobei ein DGX H100 Cluster über InfiniBand verbunden war. Für die Berechnungen wurden verschiedene Anzahlen von Grafikprozessoren verwendet, von 32 bis 256, wobei jedoch jedes System für jeden Test die gleiche Anzahl von Grafikprozessoren verwendete. Dies führte zu einer erwarteten Leistungssteigerung des Interconnects um das 2,2- bis 6,3-fache. Bis Ende 2023 wird Nvidia seinen führenden Kunden Google, Meta und Microsoft DGX GH200-Referenz-Blaupausen zur Verfügung stellen. Das System wird auch als Referenzarchitektur-Design für Cloud-Service-Provider und Hyperscaler angeboten.Zusätzlich wird Nvidia den neuen Nvidia Helios Supercomputer für interne Forschungs- und Entwicklungsarbeiten einsetzen. Der Supercomputer besteht aus vier DGX GH200-Systemen, die insgesamt 1.024 Grace Hopper Superchips enthalten. Diese Systeme werden über das Quantum-2 InfiniBand 400 Gb/s Netzwerk von Nvidia verbunden.
Nvidia MGX Systeme – Referenzarchitekturen

Obwohl DGX-Systeme für High-End-Anwendungen und HGX-Systeme für Hyperscaler entwickelt wurden, stellen die neuen MGX-Systeme eine Art Zwischenlösung dar. DGX und HGX werden neben den neuen MGX-Systemen weiterhin existieren.
Die OxM-Partner von Nvidia stehen vor neuen Herausforderungen bei der Entwicklung und Bereitstellung von KI-zentrierten Serverdesigns, was zu Verzögerungen führt. Um diesen Prozess zu beschleunigen, hat Nvidia die MGX-Referenzarchitekturen entwickelt, die mehr als 100 Referenzdesigns umfassen. Die MGX-Systeme bieten modulare Designs, die das gesamte Portfolio von Nvidia an CPUs, GPUs, DPUs und Netzwerksystemen abdecken. Darüber hinaus sind auch Designs erhältlich, die auf den gängigen x86- und Arm-basierten Prozessoren basieren, die in heutigen Servern zum Einsatz kommen. Nvidia bietet auch Möglichkeiten für luft- und flüssigkeitsgekühlte Designs an, so dass OxM-Partner verschiedene Designoptionen für eine Vielzahl von Anwendungen zur Verfügung haben.







Ein bedeutender Faktor besteht darin, dass Nvidia in Hochleistungs-KI-Plattformen Ethernet als Konnektivitätsoption anstelle der häufig in solchen Systemen verwendeten InfiniBand-Verbindungen einsetzt. Das Spectrum-X-Design nutzt Nvidias 51 TB/s Spectrum 4-400 GbE Ethernet-Switches sowie Nvidias Bluefield 3 DPUs und bietet Entwicklern Software und SDKs, um Systeme entsprechend den spezifischen Anforderungen von KI-Workloads anzupassen. Im Vergleich zu anderen Ethernet-basierten Systemen betont Nvidia, dass Spectrum-X verlustfrei ist und dadurch eine verbesserte QoS und Latenz bietet. Zusätzlich verfügt es über eine adaptive Routing-Technologie, die insbesondere in Multi-Client-Umgebungen von Vorteil ist.
Die Spectrum-X-Netzwerkplattform ist ein wesentlicher Bestandteil von Nvidias Portfolio, da sie leistungsstarke KI-Clustering-Fähigkeiten in Ethernet-basierte Netzwerke einführt und somit neue Möglichkeiten für den umfassenden Einsatz von KI in Hyperscale-Infrastrukturen bietet. Die Spectrum-X-Plattform ist vollständig interoperabel mit vorhandenen Ethernet-basierten Stacks und bietet beeindruckende Skalierbarkeit mit bis zu 256 Ports mit 200 Gb/s auf einem einzelnen Switch oder 16.000 Ports in einer zweistufigen Leaf-Spine-Topologie.
Ab sofort sind die Nvidia Spectrum-X-Plattform und die entsprechenden Komponenten, einschließlich der 400G LinkX Optik, verfügbar.
Nvidia Grace und Grace Hopper Superchip Supercomputing-Siege
Die ersten Grace-CPUs von Nvidia befinden sich bereits in Produktion und haben durch ihre Verwendung in drei kürzlich gewonnenen Supercomputern für großes Interesse gesorgt. Einer dieser bemerkenswerten Supercomputer ist der Taiwania 4, der von ASUS im Auftrag des Taiwan National Center for High-Performance Computing entwickelt wird und kürzlich angekündigt wurde. Mit insgesamt 44 Grace-CPU-Knoten wird dieser Supercomputer nach Angaben von Nvidia einer der energieeffizientesten in Asien sein, sobald er in Betrieb genommen wird. Sein Zweck besteht darin, bei der Modellierung von Klimawandelproblemen zu unterstützen.
Nvidia hat auch weitere Einzelheiten zu seinem neuen Supercomputer Taipei 1 bekannt gegeben, der in Taiwan stationiert sein wird. Dieses System umfasst 64 DGX H100 KI-Supercomputer sowie 64 Nvidia OVX-Systeme, die durch das firmeneigene Netzwerkkit verbunden sind. Nach Abschluss der Arbeiten im Laufe dieses Jahres wird der Supercomputer für lokale Forschungs- und Entwicklungsaufgaben genutzt, ohne dass diese spezifiziert wurden.
Quelle: TomsHardware, NVIDIA


















4 Antworten
Kommentar
Lade neue Kommentare
Urgestein
Urgestein
Urgestein
Urgestein
Alle Kommentare lesen unter igor´sLAB Community →