











At Computex 2023 in Taipei, Taiwan, Jensen Huang, CEO of Nvidia, announced that the company’s Grace hopper superchips are now in full production. The Grace platform has already successfully won six supercomputer competitions. As part of this exciting development, Huang unveiled the new DGX GH200 AI supercomputing platform at Computex 2023.
This platform, designed specifically for massive generative AI workloads, is available now with 256 Grace Hopper superchips. These chips work together as a powerful supercomputing system with 144 TB of shared memory to handle even the most demanding generative AI training tasks. Well-known companies such as Google, Meta and Microsoft have already expressed interest in these advanced systems from Nvidia.

Nvidia also announced the launch of its new MGX reference architectures. These architectures will help OEMs develop new AI supercomputers even faster. More than 100 systems are available in the process. The company also unveiled the Spectrum-X Ethernet networking platform, designed and optimized specifically for AI servers and supercomputing clusters. With this platform, Nvidia offers a state-of-the-art solution for networking AI systems and supercomputers. Dive into the future of technology!







Grace hopper superchips now in production at Nvidia

There has already been extensive coverage of the Grace and Grace Hopper superchips that have been introduced in the past. These chips are central to the new systems announced by Nvidia today. The Grace chip acts as Nvidia’s own arm CPU processor, while the Grace Hopper superchip combines the Grace CPU with a Hopper GPU, 72 cores, 96GB of HBM3 and 512GB of LPDDR5X in one package. With a total of 200 billion transistors, this superchip is a technical heavyweight. The combination of Grace CPU and Hopper GPU enables an impressive data bandwidth of up to 1 TB/s between both components. This high throughput proves to be a huge advantage, especially for memory-intensive workloads.
Given that the Grace Hopper superchips are now in production, we can expect systems to be available from various Nvidia partners including Asus, Gigabyte, ASRock Rack and Pegatron. Of particular note, Nvidia will also introduce its own systems based on the new chips. In addition, the company will release reference design architectures for OxMs and hyperscalers, which we will discuss below.
Nvidia DGX GH200 supercomputer
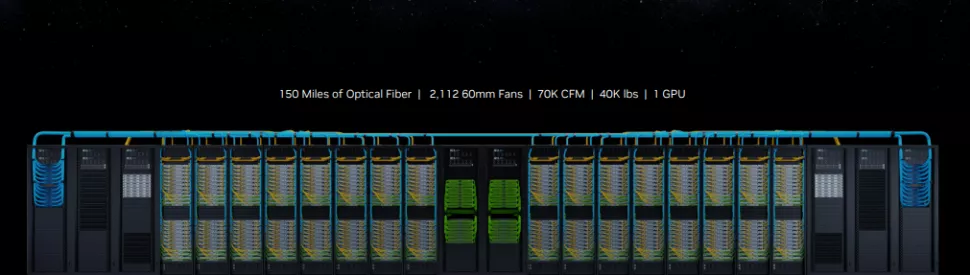

Nvidia’s DGX systems are the leading choice for high-performance AI and HPC workloads. However, current DGX A100 systems are limited to eight A100 GPUs working together as a single unit. Given the rapid growth in generative AI, there is a great need among Nvidia’s customers for more powerful systems with significantly more capacity. That’s why the DGX H200 is designed to provide tremendous scalability and ultimate throughput for the most demanding workloads such as generative AI training, large language models, recommendation systems, and data analytics. It does so by circumventing the limitations of traditional cluster interconnect options such as InfiniBand and Ethernet through the use of Nvidia’s custom NVLink switch silicon.
Although the exact specifications of the new DGX GH200 AI supercomputer are not yet known, we do know that Nvidia is using a new NVLink switch system. This system consists of 36 third-generation NVLink switches to connect 256 GH200 Grace Hopper chips and 144TB of shared memory into a unified structure. This creates a massive computing unit that resembles a giant graphics processor both visually and in terms of performance.
The DGX GH200 is equipped with a total of 256 Grace Hopper CPU+GPUs, significantly outperforming Nvidia’s largest NVLink-connected DGX system to date with eight GPUs. Compared to the DGX A100 systems, which offer only 320GB of shared memory between eight A100 GPUs, the DGX GH200 has an impressive 144TB of shared memory, a 500x increase. Unlike the DGX A100 system’s expansion to clusters with more than eight GPUs, which uses InfiniBand as a link between systems and results in performance degradation, the DGX GH200 is the first time Nvidia has built a full supercomputing cluster around the NVLink switch topology. This cluster offers up to 10 times the GPU-to-GPU bandwidth and seven times the CPU-to-GPU bandwidth compared to the previous generation, according to Nvidia. In addition, it offers 5 times the interconnect efficiency of competing interconnects and up to 128 TB/s of bisectional bandwidth.
Although the system requires 150 miles of fiber optic cable and weighs 40,000 pounds, it is still considered a single GPU. Nvidia claims that the 256 Grace Hopper superchips give the DGX GH200 “AI performance” in the range of exaflops, a value measured with smaller data types that are more relevant to AI workloads than the FP64 measurements used in HPC and supercomputing. This impressive performance is achieved through GPU-to-GPU bandwidth of 900 GB/s. The scalability of the system is particularly noteworthy, as Grace Hopper achieves a maximum throughput of 1 TB/s with the Grace CPU when connected directly on the same board via the NVLink C2C chip interconnect.
Nvidia has published benchmarks of the DGX GH200 with the NVLink Switch system, with a DGX H100 cluster connected over InfiniBand. Different numbers of GPUs were used for the calculations, from 32 to 256, but each system used the same number of GPUs for each test. This resulted in an expected 2.2 to 6.3 times increase in interconnect performance. By the end of 2023, Nvidia will provide DGX GH200 reference blueprints to its leading customers Google, Meta and Microsoft. The system will also be offered as a reference architecture design for cloud service providers and hyperscalers.In addition, Nvidia will use the new Nvidia Helios supercomputer for internal research and development work. The supercomputer consists of four DGX GH200 systems containing a total of 1,024 Grace Hopper superchips. These systems will be connected via Nvidia’s Quantum-2 InfiniBand 400 Gb/s network.
Nvidia MGX Systems – Reference Architectures

Although DGX systems are designed for high-end applications and HGX systems are designed for hyperscalers, the new MGX systems represent something of an intermediate solution. DGX and HGX will continue to exist alongside the new MGX systems.
Nvidia’s OxM partners are facing new challenges in developing and deploying AI-centric server designs, causing delays. To accelerate this process, Nvidia has developed the MGX reference architectures, which include more than 100 reference designs. The MGX systems offer modular designs that span Nvidia’s entire portfolio of CPUs, GPUs, DPUs and networking systems. In addition, designs based on the popular x86 and Arm-based processors used in today’s servers are also available. Nvidia also offers options for air-cooled and liquid-cooled designs, giving OxM partners multiple design options for a variety of applications.







A significant factor is that Nvidia is using Ethernet as a connectivity option in high-performance AI platforms instead of the InfiniBand links often used in such systems. The Spectrum-X design leverages Nvidia’s 51 TB/s Spectrum 4-400 GbE Ethernet switches and Nvidia’s Bluefield 3 DPUs, providing developers with software and SDKs to customize systems according to the specific needs of AI workloads. Compared to other Ethernet-based systems, Nvidia emphasizes that Spectrum-X is lossless, providing improved QoS and latency. Additionally, it features adaptive routing technology, which is especially beneficial in multi-client environments.
The Spectrum-X networking platform is a key component of Nvidia’s portfolio as it introduces powerful AI clustering capabilities to Ethernet-based networks, providing new opportunities for the extensive use of AI in hyperscale infrastructures. The Spectrum-X platform is fully interoperable with existing Ethernet-based stacks and offers impressive scalability with up to 256 ports at 200 Gb/s on a single switch or 16,000 ports in a two-tier leaf spine topology.
The Nvidia Spectrum-X platform and related components, including 400G LinkX optics, are available now.
Nvidia Grace and Grace Hopper Superchip Supercomputing Wins
Nvidia’s first Grace CPUs are already in production and have generated significant interest through their use in three recent supercomputer wins. One of these notable supercomputers is the Taiwania 4, which is being developed by ASUS on behalf of the Taiwan National Center for High-Performance Computing and was recently announced. With a total of 44 Grace CPU nodes, this supercomputer will be one of the most energy-efficient in Asia once it becomes operational, according to Nvidia. Its purpose is to assist in modeling climate change issues.
Nvidia also announced more details about its new Taipei 1 supercomputer, which will be based in Taiwan. This system includes 64 DGX H100 AI supercomputers as well as 64 Nvidia OVX systems connected by the company’s proprietary networking kit. When completed later this year, the supercomputer will be used for local research and development tasks without being specified.
Source: TomsHardware, NVIDIA

















4 Antworten
Kommentar
Lade neue Kommentare
Urgestein
Urgestein
Urgestein
Urgestein
Alle Kommentare lesen unter igor´sLAB Community →