











NVIDIA’s next generation Blackwell architecture, named after renowned American mathematician and statistician David Harold Blackwell, is set to pave the way for groundbreaking advances in GPU technology. The new Blackwell series, specifically the B100 GPU, will be launched later this year and promises to deliver a significant performance boost over its predecessor, the Hopper GH200 series, by more than doubling the performance of the Hopper H200 GPUs. The Blackwell GPUs thus not only represent a significant advance in NVIDIA’s GPU technology, but also pay homage to David Harold Blackwell’s unparalleled contributions to mathematics and statistics by laying the foundation for the next era of AI and computing. To avoid confusion, NVIDIA Blackwell GPUs are referred to as B200 on the one hand and GB200 on the other, as these designations represent different products within the Blackwell architecture. More on this in a moment.

NVIDIA now also uses multi-chip modules (MCM)
This huge leap is made possible by advances such as a chiplet design, incidentally the first of its kind for NVIDIA, repositioning itself to compete directly with AMD’s upcoming Instinct MI300 accelerator. The new chiplet design, a Multi-Chip Module (MCM), is a major innovation for NVIDIA and indicates a major shift in packaging technology. This design allows GPUs to be flexibly adapted to different customer requirements without having to significantly change the number of CUDA cores. It is expected that this will significantly change the architecture of GPU clusters to support the new MCM approach.

Unlike previous monolithic designs that used a single large chip, chiplet technology allows for more efficient production and can potentially increase yields during the manufacturing process. TSMC’s CoWoS (Chip on Wafer on Substrate) technology plays a key role in realizing these new packaging techniques, with NVIDIA and AMD competing for access to this cutting-edge technology. The move to a chiplet design could also enable NVIDIA to continue to offer high performance GPUs for high-end gaming PCs, especially at a time when ASML’s next generation of scanners are halving reticle size.
CoWoS is a 2.5D IC packaging technology that integrates multiple dies side-by-side on a silicon interposer. This arrangement enables better interconnect density and performance compared to conventional packaging methods. It uses through-silicon vias (TSVs) and micro-bumps to connect individual chips to the silicon interposer, which is then connected to a package substrate to achieve high-speed and high-bandwidth communication between the chips.
TSMC has now developed several CoWoS variants, including CoWoS-R and CoWoS-L, to meet different application needs. CoWoS-R utilizes Integrated Fan-Out (InFO) technology and uses an RDL (Redistribution Layer) interposer for the connection between chiplets, especially useful for High Bandwidth Memory (HBM) and SoC (System on Chip) integrations. It offers up to 6 layers of copper routes with a minimum pitch of 4µm and provides excellent signal and power integrity. CoWoS-L now combines the advantages of CoWoS-S and InFO technologies by using an interposer with LSI (Local Silicon Interconnect) chips for dense die-to-die connections as in Blackwell. This version starts with a 1.5x reticle interposer size and aims to integrate more chips by expanding the interposer size, allowing greater flexibility and higher integration for complex functions.
looking ahead, TSMC is developing a 6x reticle size CoWoS-L technology with super carrier interposer technology to meet the increased demands of AI and HPC applications by enabling even larger processors with complex multi-tile chiplet designs. This advancement could enable SiPs (System in Package) of 5148mm² and allow the integration of multiple large compute chiplets and significant HBM memory, potentially reaching bandwidths of up to 9.8TB/s.

NVIDIA’s new GB200 super-chip
The NVIDIA GB200 Grace Blackwell superchip connects two NVIDIA B200 Tensor Core GPUs to the NVIDIA Grace CPU via a 900GB/s ultra-low energy NVLink chip-to-chip interconnect. For the highest AI performance, GB200-powered systems can be connected to the NVIDIA Quantum-X800 InfiniBand and Spectrum™-X800 Ethernet platforms, also announced today, delivering advanced networking capabilities with speeds up to 800Gb/s. Featuring 208 billion transistors, the Blackwell architecture GPUs are manufactured using a specially designed 4NP TSMC process, with two reticle boundary GPU dies connected by a 10TB/second chip-to-chip interconnect to form a single, unified GPU.
This immense transistor count indicates NVIDIA’s ambition to significantly increase computing capabilities, particularly in the areas of AI and HPC. In addition, NVIDIA’s roadmap includes a successor to Blackwell in the form of the GX200, planned for a launch around 2025-2026, indicating the company’s continued commitment to innovation in GPU technology. In addition, Blackwell is equipped with Micron’s world’s fastest HBM3e memory. This development will offer up to 141GB per GPU and up to 4.8TB/s of memory bandwidth, underscoring NVIDIA’s efforts to meet the growing demands for higher memory capacity and bandwidth in AI and HPC applications.
Even training large language models such as GPT-3, with 1.75 trillion parameters, encounters significant challenges, especially in data transfer and communication within GPU clusters. The main bottlenecks lie in the efficient communication of data between the nodes in the training cluster. Advanced networking solutions such as the end-to-end InfiniBand network are critical to overcoming these challenges by providing high-speed, reliable networks with capabilities such as 400 Gbps transfer rates and microsecond latency, far surpassing Ethernet.
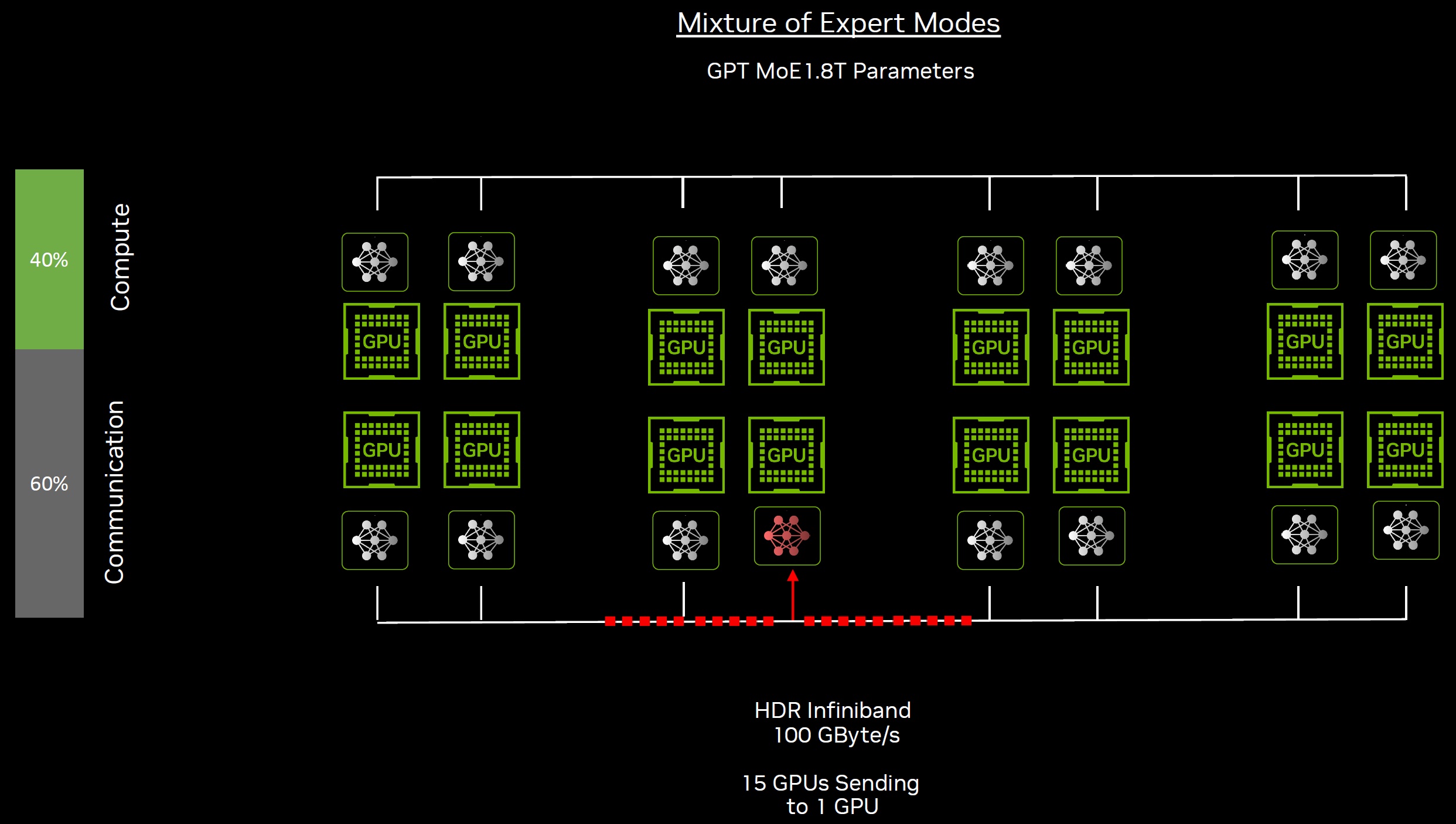
InfiniBand’s data redundancy, error correction mechanisms and Remote Direct Memory Access (RDMA) technology enable direct data transfers between applications, reducing CPU resource consumption and increasing training efficiency. A compute fabric is a flexible and scalable network of computing resources that enables the integration and management of servers, storage and network services via a unified platform. It aims to increase the efficiency and performance of data centers by providing seamless connectivity and high throughput between the various components.
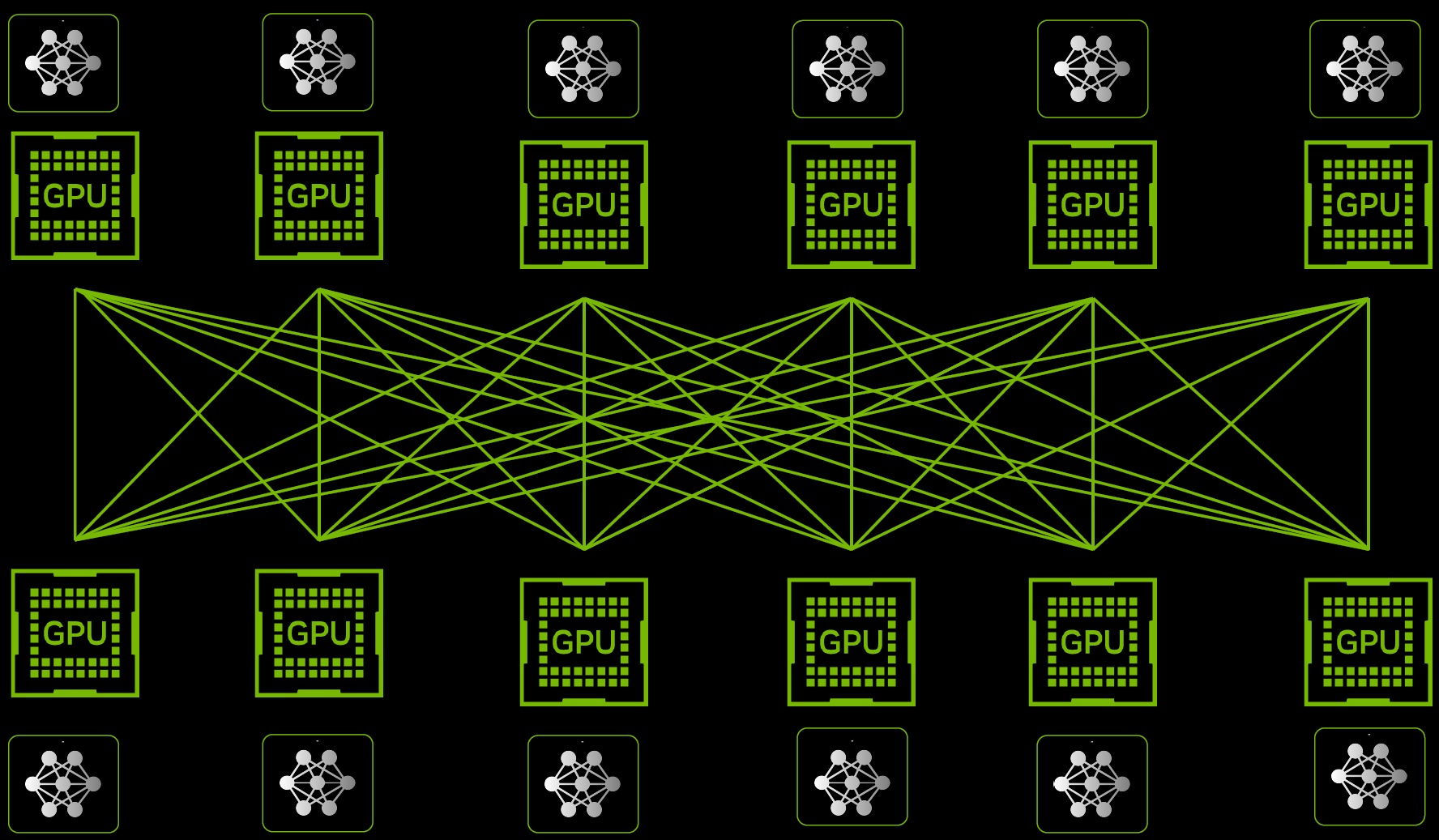
The GB200 is a key component of the NVIDIA GB200 NVL72, a liquid-cooled rack system for the most compute-intensive workloads. It combines 36 Grace Blackwell superchips, comprising 72 Blackwell GPUs and 36 Grace CPUs, connected by fifth-generation NVLink. In addition, GB200 NVL72 includes NVIDIA BlueField®-3 data processing units to enable network acceleration in the cloud, composable memory, zero-trust security and GPU compute elasticity in hyperscale AI clouds. GB200 NVL72 delivers up to 30x performance improvement over the same number of NVIDIA H100 Tensor Core GPUs for LLM inference workloads, reducing cost and power consumption by up to 25x. The platform acts as a single GPU with 1.4 exaflops of AI performance and 30TB of fast memory and is a building block for the latest DGX SuperPOD. NVIDIA offers the HGX B200, a server board that connects eight B200 GPUs through NVLink to support x86-based generative AI platforms. HGX B200 supports network speeds of up to 400Gb/s through the NVIDIA Quantum-2 InfiniBand and Spectrum-X Ethernet networking platforms.

NVIDIA has made significant advances in high-performance computing (HPC) and artificial intelligence (AI) with its fifth generation of NVLink and the NVLink Switch 7.2T. These technologies are at the heart of the new Blackwell GPU. With up to 1.8 TB/s of full bidirectional bandwidth between all GPUs and a significantly larger number of GPUs involved (also stacked across multiple racks), the speed of current multi-node interconnects is increased 18-fold.

NVIDIA’s Blackwell and Hopper series underscore the company’s strategic focus on AI and HPC markets, with continuous innovation aimed at delivering unprecedented compute performance and efficiency. The introduction of Blackwell GPUs marks a turning point in the evolution of GPU technology, promising to significantly enhance the capabilities of the next generation of computing infrastructures. We can therefore be excited.
Blackwell will also find its way into NVIDIA’s DDX Cloud. This is a platform designed specifically for artificial intelligence (AI) and deep learning workloads. It provides access to powerful DGX systems in the cloud that are equipped with NVIDIA GPUs. This platform is aimed at scientists, engineers and developers who need to process complex AI models and high-performance computing (HPC) tasks efficiently and quickly without having to invest in expensive hardware on site. The flexibility to scale resources up or down as needed is also important, providing a cost-effective solution for projects of different sizes and requirements.

The DGX Cloud platform also integrates various software tools and frameworks necessary for the development and training of AI models, such as TensorFlow, PyTorch and NVIDIA’s own CUDA toolkit. This greatly simplifies the workflow as users do not have to manually install and configure multiple software components. Another important aspect of DGX Cloud is the ability to access a community of experts and resources. NVIDIA provides extensive documentation, best practices and support to help users get the most out of their DGX Cloud instances. This is especially valuable for teams that are new to the world of AI or looking to expand their existing capabilities.
Cisco, Dell, Hewlett Packard Enterprise, Lenovo and Supermicro are expected to supply a wide range of servers based on Blackwell products, as are Aivres, ASRock Rack, ASUS, Eviden, Foxconn, GIGABYTE, Inventec, Pegatron, QCT, Wistron, Wiwynn and ZT Systems. In addition, a growing network of software vendors, including Ansys, Cadence and Synopsys – global leaders in engineering simulation – will use Blackwell-based processors to accelerate their software for the design and simulation of electrical, mechanical and manufacturing systems and parts. Their customers can use generative AI and accelerated computing to bring products to market faster, more cost-effectively and with greater energy efficiency.
Blackwell’s product portfolio is powered by NVIDIA AI Enterprise, the operating system for production-ready AI from start to finish. NVIDIA AI Enterprise includes NVIDIA NIM™ inference microservices – also announced today – as well as AI frameworks, libraries and tools that enterprises can deploy in NVIDIA-accelerated clouds, data centers and workstations.
NVIDIA has made this information available in advance under NDA. The only condition was compliance with the embargo period
















29 Antworten
Kommentar
Lade neue Kommentare
Veteran
Urgestein
1
Veteran
Urgestein
1
Urgestein
Urgestein
Urgestein
Urgestein
1
Urgestein
Urgestein
Urgestein
Veteran
Urgestein
Alle Kommentare lesen unter igor´sLAB Community →