











NVIDIAs nächste Generation der Blackwell-Architektur, benannt nach dem renommierten amerikanischen Mathematiker und Statistiker David Harold Blackwell, soll den Weg für bahnbrechende Fortschritte in der GPU-Technologie ebnen. Die neue Blackwell-Serie, insbesondere die B100 GPU, wird noch in diesem Jahr eingeführt und verspricht eine bedeutende Leistungssteigerung gegenüber ihrer Vorgängerin, der Hopper GH200 Serie, indem sie mehr als die doppelte Leistung der Hopper H200 GPUs bieten soll. Die Blackwell-GPUs repräsentieren somit nicht nur einen bedeutenden Fortschritt in NVIDIAs GPU-Technologie, sondern sind auch eine Hommage an David Harold Blackwells beispiellose Beiträge zur Mathematik und Statistik, indem sie den Grundstein für die nächste Ära der KI und des Computings legen. Um jetzt Verwirrungen vorzubeugen: Bei den NVIDIA Blackwell GPUs spricht man einerseits von B200 und andererseits von GB200, da diese Bezeichnungen unterschiedliche Produkte innerhalb der Blackwell-Architektur darstellen. Dazu gleich mehr.

NVIDIA nutzt jetzt ebenfalls Multi-Chip Module (MCM)
Dieser gewaltige Sprung wird durch Fortschritte wie ein Chiplet-Design ermöglicht, übrigens das erste seiner Art für NVIDIA, und man positioniert sich damit neu, um direkt mit AMDs kommendem Instinct MI300 Beschleuniger zu konkurrieren. Das neue Chiplet-Design, ein Multi-Chip Module (MCM), stellt für NVIDIA eine wichtige Neuerung dar und deutet auf einen großen Wandel in der Verpackungstechnik hin. Dieses Design ermöglicht eine flexible Anpassung der GPUs an verschiedene Kundenanforderungen, ohne dass die Anzahl der CUDA-Cores wesentlich verändert werden muss. Es wird erwartet, dass sich dadurch die Architektur der GPU-Cluster signifikant verändern wirdt, um den neuen MCM-Ansatz zu unterstützen.

Im Gegensatz zu bisherigen monolithischen Designs, bei denen ein einziger großer Chip verwendet wurde, ermöglicht die Chiplet-Technologie eine effizientere Produktion und kann potenziell die Ausbeute während des Herstellungsprozesses erhöhen. TSMCs CoWoS (Chip on Wafer on Substrate) Technologie spielt eine Schlüsselrolle bei der Realisierung dieser neuen Verpackungstechniken, wobei NVIDIA und AMD um Zugang zu dieser Spitzentechnologie konkurrieren. Die Umstellung auf ein Chiplet-Design könnte NVIDIA auch in die Lage versetzen, weiterhin hochleistungsfähige GPUs für High-End-Gaming-PCs anzubieten, insbesondere in einer Zeit, in der ASMLs nächste Generation von Scannern die Reticle-Größe halbiert.
CoWoS ist eine 2,5D-IC-Verpackungstechnologie, die mehrere Dies nebeneinander auf einem Silizium-Interposer integriert. Diese Anordnung ermöglicht eine bessere Verbindungsdichte und Leistung im Vergleich zu herkömmlichen Verpackungsmethoden. Es verwendet Through-Silicon Vias (TSVs) und Mikro-Bumps, um einzelne Chips mit dem Silizium-Interposer zu verbinden, der dann mit einem Paket-Substrat verbunden wird, um eine hochgeschwindigkeits- und hochbandbreite Kommunikation zwischen den Chips zu erreichen.
TSMC hat mittlerweile verschiedene CoWoS-Varianten entwickelt, darunter CoWoS-R und CoWoS-L, um unterschiedlichen Anwendungsbedürfnissen gerecht zu werden. CoWoS-R nutzt die InFO-Technologie (Integrated Fan-Out) und verwendet einen RDL-Interposer (Redistribution Layer) für die Verbindung zwischen Chiplets, insbesondere nützlich für High Bandwidth Memory (HBM) und SoC (System on Chip)-Integrationen. Es bietet bis zu 6 Schichten aus Kupferrouten mit einem minimalen Pitch von 4µm und bietet eine ausgezeichnete Signal- und Stromintegrität. CoWoS-L kombiniert nun die Vorteile der CoWoS-S- und InFO-Technologien, indem ein Interposer mit LSI-Chips (Local Silicon Interconnect) für dichte Die-zu-Die-Verbindungen verwendet wird wie bei Blackwell. Diese Version beginnt mit einer 1,5-fachen Retikel-Interposer-Größe und zielt darauf ab, durch Erweiterung der Interposer-Größe mehr Chips zu integrieren, wodurch eine größere Flexibilität und höhere Integration für komplexe Funktionen ermöglicht wird.
Blickt man in die Zukunft, entwickelt TSMC eine 6-fache Retikel-Größe CoWoS-L-Technologie mit Super Carrier Interposer-Technologie, um den gestiegenen Anforderungen von KI- und HPC-Anwendungen gerecht zu werden, indem noch größere Prozessoren mit komplexen Multi-Tile-Chiplet-Designs ermöglicht werden. Diese Weiterentwicklung könnte SiPs (System in Package) von 5148mm² ermöglichen und die Integration mehrerer großer Compute-Chiplets und erheblicher HBM-Speicher zulassen, die dann potenziell Bandbreiten bis zu 9,8 TB/s erreichen könnten.

NVIDIAs neuer Super-Chip GB200
Der NVIDIA GB200 Grace Blackwell Superchip verbindet zwei NVIDIA B200 Tensor Core GPUs mit der NVIDIA Grace CPU über eine 900GB/s ultra-niedrigenergetische NVLink Chip-zu-Chip-Verbindung. Für höchste KI-Leistung können GB200-betriebene Systeme mit den ebenfalls heute angekündigten NVIDIA Quantum-X800 InfiniBand und Spectrum™-X800 Ethernet-Plattformen verbunden werden, die fortschrittliche Netzwerkfähigkeiten mit Geschwindigkeiten von bis zu 800Gb/s liefern. Er ist 208 Milliarden Transistoren ausgestattet, werden die Blackwell-Architektur-GPUs mithilfe eines speziell entwickelten 4NP-TSMC-Prozesses hergestellt, mit zwei Retikelgrenzen GPU-Dies, die durch eine 10 TB/Sekunde Chip-zu-Chip-Verbindung zu einer einzigen, einheitlichen GPU verbunden sind.
Diese immense Transistoranzahl deutet auf NVIDIAs Ambition hin, die Rechenfähigkeiten, insbesondere in den Bereichen KI und HPC, erheblich zu steigern. Darüber hinaus beinhaltet NVIDIAs Roadmap einen Nachfolger für Blackwell in Form der GX200, geplant für eine Einführung um 2025-2026, was auf das anhaltende Engagement des Unternehmens für Innovationen in der GPU-Technologie hinweist. Darüber hinaus ist Blackwell mit Microns weltweit schnellstem HBM3e-Speicher bestückt. Diese Entwicklung wird bis zu 141GB pro GPU und bis zu 4,8TB/s Speicherbandbreite bieten, was NVIDIAs Bemühungen unterstreicht, den wachsenden Anforderungen nach höherer Speicherkapazität und Bandbreite in KI- und HPC-Anwendungen gerecht zu werden.

Bereits das Training großer Sprachmodelle wie GPT-3, mit 1,75 Billionen Parametern, stößt auf erhebliche Herausforderungen, insbesondere bei der Datenübertragung und Kommunikation innerhalb von GPU-Clustern. Die Hauptengpässe liegen in der effizienten Kommunikation von Daten zwischen den Knoten im Trainingscluster. Fortgeschrittene Netzwerklösungen wie das end-to-end InfiniBand-Netzwerk sind entscheidend, um diese Herausforderungen zu überwinden, indem sie hochgeschwindigkeitsfähige, zuverlässige Netzwerke mit Fähigkeiten wie 400 Gbps Übertragungsraten und Mikrosekunden-Latenz bieten, was Ethernet weit übertrifft.
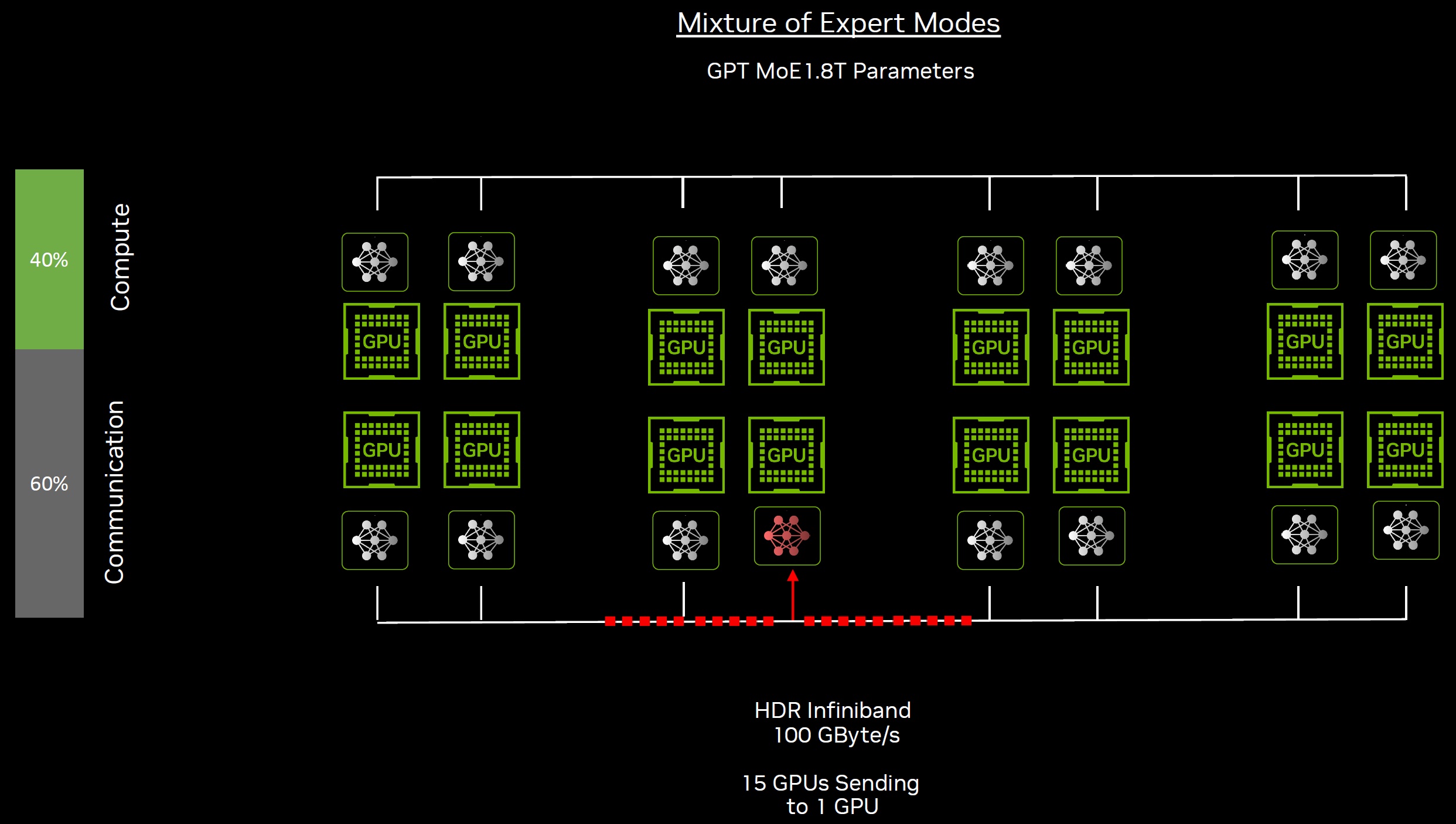
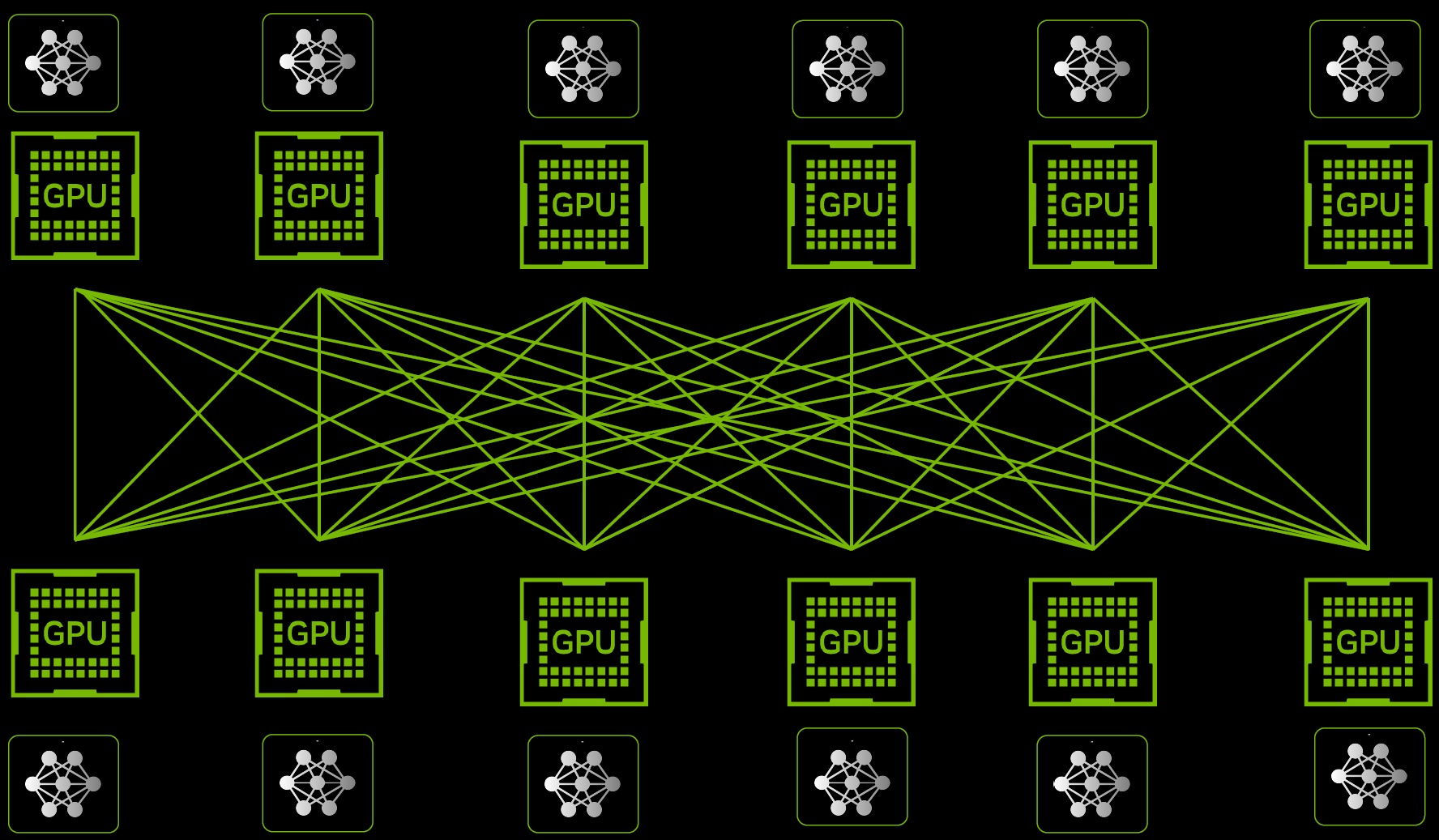
InfiniBands Datenredundanz, Fehlerkorrekturmechanismen und Remote Direct Memory Access (RDMA)-Technologie ermöglichen direkte Datenübertragungen zwischen Anwendungen, was den CPU-Ressourcenverbrauch reduziert und die Trainingseffizienz erhöht. Ein Compute Fabric, oft auch als Rechnergewebe bezeichnet, ist ein flexibles und skalierbares Netzwerk von Rechnerressourcen, das die Integration und das Management von Servern, Speicher- und Netzwerkdiensten über eine einheitliche Plattform ermöglicht. Es zielt darauf ab, die Effizienz und die Leistungsfähigkeit von Datenzentren zu erhöhen, indem es eine nahtlose Konnektivität und eine hohe Durchsatzrate zwischen den verschiedenen Komponenten bietet.
Der GB200 ist eine Schlüsselkomponente des NVIDIA GB200 NVL72, eines flüssigkeitsgekühlten Rack-Systems für die rechenintensivsten Arbeitslasten. Es kombiniert 36 Grace Blackwell Superchips, die 72 Blackwell GPUs und 36 Grace CPUs umfassen, verbunden durch NVLink der fünften Generation. Zusätzlich enthält GB200 NVL72 NVIDIA BlueField®-3 Datenverarbeitungseinheiten, um Netzwerkbeschleunigung in der Cloud, zusammensetzbaren Speicher, Zero-Trust-Sicherheit und GPU-Rechenelastizität in hyperskalaren KI-Clouds zu ermöglichen. GB200 NVL72 bietet eine bis zu 30-fache Leistungssteigerung im Vergleich zur gleichen Anzahl von NVIDIA H100 Tensor Core GPUs für LLM-Inferenzarbeitslasten und reduziert die Kosten und den Energieverbrauch um bis zu 25x. Die Plattform agiert als eine einzelne GPU mit 1,4 Exaflops KI-Leistung und 30TB schnellem Speicher und ist ein Baustein für den neuesten DGX SuperPOD. NVIDIA bietet das HGX B200, ein Serverboard, das acht B200 GPUs durch NVLink verbindet, um x86-basierte generative KI-Plattformen zu unterstützen. HGX B200 unterstützt Netzwerkgeschwindigkeiten von bis zu 400Gb/s durch die NVIDIA Quantum-2 InfiniBand und Spectrum-X Ethernet-Netzwerkplattformen.

NVIDIA hat mit seiner fünften Generation von NVLink und dem NVLink Switch 7.2T signifikante Fortschritte in der High-Performance-Computing (HPC) und Künstlichen Intelligenz (KI) gemacht. Diese Technologien sind ein Kernstück der neuen Blackwell GPU. Mit bis zu 1,8 TB/s voller bidirektionaler Bandbreite zwischen allen und einer deutlich größeren Anzahl von beteiligten GPUs (Slaklierung auch über mehrere Racks) steigert man die Geschwindigkeit aktueller Multi-Node-Interconnects auf das 18-Fache.

NVIDIAs Blackwell- und Hopper-Serien unterstreichen den strategischen Fokus des Unternehmens auf KI- und HPC-Märkte, mit kontinuierlichen Innovationen, die darauf abzielen, beispiellose Rechenleistung und Effizienz zu liefern. Die Einführung der Blackwell GPUs markiert einen Wendepunkt in der Evolution der GPU-Technologie, der verspricht, die Fähigkeiten der nächsten Generation von Recheninfrastrukturen erheblich zu verbessern. Man darf somit gespannt sein.
So wird Blackwell auch in NVIDIAs DDX Cloud Einzug halten. Dabei handelt es sich um eine Plattform, die speziell für künstliche Intelligenz (KI) und Deep Learning Workloads konzipiert wurde. Sie bietet Zugang zu leistungsstarken DGX-Systemen in der Cloud, die mit NVIDIA GPUs ausgestattet sind. Diese Plattform richtet sich an Wissenschaftler, Ingenieure und Entwickler, die komplexe KI-Modelle und High-Performance Computing (HPC) Aufgaben effizient und schnell bearbeiten müssen, ohne in teure Hardware vor Ort investieren zu müssen. Wichtig ist hierbei auch die Flexibilität, Ressourcen nach Bedarf hoch- oder herunterfahren zu können, was eine kosteneffiziente Lösung für Projekte verschiedener Größen und Anforderungen darstellt.

Die DGX Cloud-Plattform integriert zudem verschiedene Software-Tools und Frameworks, die für die Entwicklung und das Training von KI-Modellen notwendig sind, wie z.B. TensorFlow, PyTorch und NVIDIA’s eigenes CUDA Toolkit. Dies vereinfacht den Workflow erheblich, da Benutzer nicht mehrere Softwarekomponenten manuell installieren und konfigurieren müssen. Ein weiterer wichtiger Aspekt der DGX Cloud ist die Möglichkeit, auf eine Gemeinschaft von Experten und Ressourcen zuzugreifen. NVIDIA bietet umfangreiche Dokumentationen, Best Practices und Support, um Nutzern zu helfen, das Maximum aus ihren DGX-Cloud-Instanzen herauszuholen. Dies ist besonders wertvoll für Teams, die neu in der Welt der KI sind oder ihre bestehenden Fähigkeiten erweitern möchten.
Es wird erwartet, dass Cisco, Dell, Hewlett Packard Enterprise, Lenovo und Supermicro eine breite Palette von Servern auf Basis der Blackwell-Produkte liefern werden, ebenso wie Aivres, ASRock Rack, ASUS, Eviden, Foxconn, GIGABYTE, Inventec, Pegatron, QCT, Wistron, Wiwynn und ZT Systems. Zusätzlich wird ein wachsendes Netzwerk von Softwareherstellern, einschließlich Ansys, Cadence und Synopsys – weltweit führende Unternehmen in der Ingenieursimulation – Blackwell-basierte Prozessoren nutzen, um ihre Software für das Design und die Simulation von elektrischen, mechanischen und fertigungstechnischen Systemen und Teilen zu beschleunigen. Ihre Kunden können generative KI und beschleunigtes Rechnen nutzen, um Produkte schneller, kostengünstiger und mit höherer Energieeffizienz auf den Markt zu bringen.
Das Produktportfolio von Blackwell wird von NVIDIA AI Enterprise unterstützt, dem Betriebssystem für produktionsreife KI von Anfang bis Ende. NVIDIA AI Enterprise umfasst NVIDIA NIM™ Inferenz-Mikroservices – ebenfalls heute angekündigt – sowie KI-Frameworks, Bibliotheken und Tools, die Unternehmen in NVIDIA-beschleunigten Clouds, Rechenzentren und Workstations einsetzen können.
NVIDIA hat diese Informationen vorab unter NDA zur Verfügung gestellt. Einzge Bedingung war die Einhaltung der Sperrfrist


















29 Antworten
Kommentar
Lade neue Kommentare
Veteran
Urgestein
1
Veteran
Urgestein
1
Urgestein
Urgestein
Urgestein
Urgestein
1
Urgestein
Urgestein
Urgestein
Veteran
Urgestein
Alle Kommentare lesen unter igor´sLAB Community →