













Zen wird zu Ryzen
Doch kommen wir noch einmal zu unserem kleinen Einführungskurs zurück, den wir auf der ersten Seite bereits begonnen hatten. Alles begann natürlich erst mit dem Kern als solchem. Vor immerhin fünf Jahren startete AMD die Entwicklung des Zen-Kerns und schuf damit (endlich) die erste neue Architektur seit Bulldozer. AMDs Ziel war dabei gleichzeitig auch der Wechsel von der veralteten 28-nm-Prozesstechnik hin zu Globalfoundries neuem 14-nm-FinFET-Prozess, was bei vergleichbarer Energieaufnahme auch eine verbesserte Dichte und Performance erlaubt.
AMD steckte sich seinerzeit außerdem das ambitionierte Ziel, die IPC-Performance (Instructions Per Clock) durch eine Reihe Entscheidungen in Sachen Architekturdesign, die die Leistung signifikant steigern sollen, im Vergleich zu Excavator um satte 40 Prozent anzuheben. Nochmal zur Erinnerung: AMD hat gleichzeitig eine neue Mikroarchitektur und eben einen neuen Lithografie-Prozess umgesetzt, was durchaus ein echtes Mammut-Projekt war.
 Ryzen CPU Die-Sot
Ryzen CPU Die-Sot
Der Zen-Kern fungiert als fundamentaler Baustein für Ryzen und alle künftigen AMD-CPUs bzw. APUs, wird also Einsatzbereiche von Notebooks bis hin zum Supercomputer abdecken. Ryzen-Prozessoren integrieren zwei 4-Kern-Zen-CCX‘ (CPU Complex) mit insgesamt 4,8 Milliarden Transistoren, die aktuellen APUs hingegen jeweils nur einen. AMDs neue Infinity Fabric, eine optimierte Version von HyperTransport, verbindet nun alle relevanten Bereiche. Das sind im Grunde genommen also zwei Quad-Core-CPUs, die über eine On-Die-Verbindung miteinander kommunizieren, welche auch die Northbridge und die PCIe-Lanes anbindet.
„Raven Ridge“ ersetzt im Wesentlichen den zweiten CCX durch eine Grafik-Engine mit Vega-Architektur. Somit teilt sich das Ganze in einen CCX, die Vega GGPU und den Uncore auf. Der Uncore beinhaltet einen Infinity Controller, die Infinity Fabric und den I/O- sowie den System-Hub. Während der „Zeppelin“-Die aus 4,8 Milliarden Transistoren auf einer Fläche von 213 mm² besteht, hat der „Raven Ridge“-Die 4,94 Milliarden Transistoren und misst 209,8 mm².
 Ryzen APU Die-Shot
Ryzen APU Die-Shot
Im Gegensatz zu früheren Ryzen-Produkten befinden sich, wie bereits auf der vorigen Seite erwähnt, alle vier Ausführungskerne in einem einzigen CCX (orangefarbener Block links im Bild oben). Das bedeutet, dass eine Anwendung, die auf mehreren Kernen läuft, die Infinity Fabric nicht durchlaufen muss, um mit anderen Kernen und dem Cache zu kommunizieren. Aus früheren Tests wissen wir, dass das Arbeiten mit einer Reihe von „Remote“-Kernen (und dem Cache) in der Infinity Fabric die Leistung in latenzempfindlichen Anwendungen, wie z.B. Spielen, negativ beeinflussen kann. Raven Ridge’s Single CCX sollte in solchen Situationen also besser abschneiden.
Wir haben die vierkernigen CCXes mit dem grünen Kästchen gekennzeichnet. Ähnlich wie bei AMD’s „Zeppelin“-Die enthält das Zentrum eines „Raven Ridge“-CCX vertikale Zeilen mit L3-Cache, allerdings in der Summe nur 4 MB statt 8 MB. Das bedeutet, dass es sich um eine rein architektonische Designwahl handelt, um Platz zu sparen.
Der orangefarbene Block in der oberen linken Ecke von Raven Ridge enthält wie bei Zeppelin den Interconnect und die Steuereinheiten. Aber die DDR4-Speicher-Controller und die Plattform-I/O-Schaltungen an den Rändern befinden sich an verschiedenen Stellen. Es wurde definitiv daran gearbeitet, das Layout zu optimieren. Und obwohl die Kerne selbst identisch erscheinen, ist das CCX-Design neu.
Raven Ridge Prozessoren verwenden Infinity Fabric, um die CPU-Kerne und die On-Die Vega CUs (der blaue Block auf der rechten Seite) zu verbinden. Aber es ist am Ende je nur eine Art Protokoll. Das bedeutet, dass eine Reihe von physikalischen Verbindungen durchlaufen werden kann, wie z.B. der Interposer, Leiterbahnen oder interne PCIe Lanes. Man könnte vermuten, dass dieses Protokoll über einen internen PCIe-Bus arbeitet und dass die Grafik-Engine zusätzlich einen Teil der verfügbaren Konnektivität verbraucht, weshalb die extern zugänglichen Lanes von Raven Ridge auf acht reduziert wurden. Es ist auch möglich, dass der Rückgang von 16 auf acht Lanes einfach eine weitere Designwahl war, genauso wie der reduzierte L3-Cache.
Wir haben zu diesem Thema auch ein paar eigene Messungen durchgeführt:





AMD hat dem Zen-Kern auch SMT (Simultaneous Multi-Threading) spendiert, was jedem physischen einen virtuellen Kern zur Seite stellt – in Intels Sprachgebrauch als Hyper-Threading bekannt. Ryzen war AMDs erster SMT-fähiger Prozessor und auch die Ryzen 5 2400G bietet dieses Feature.
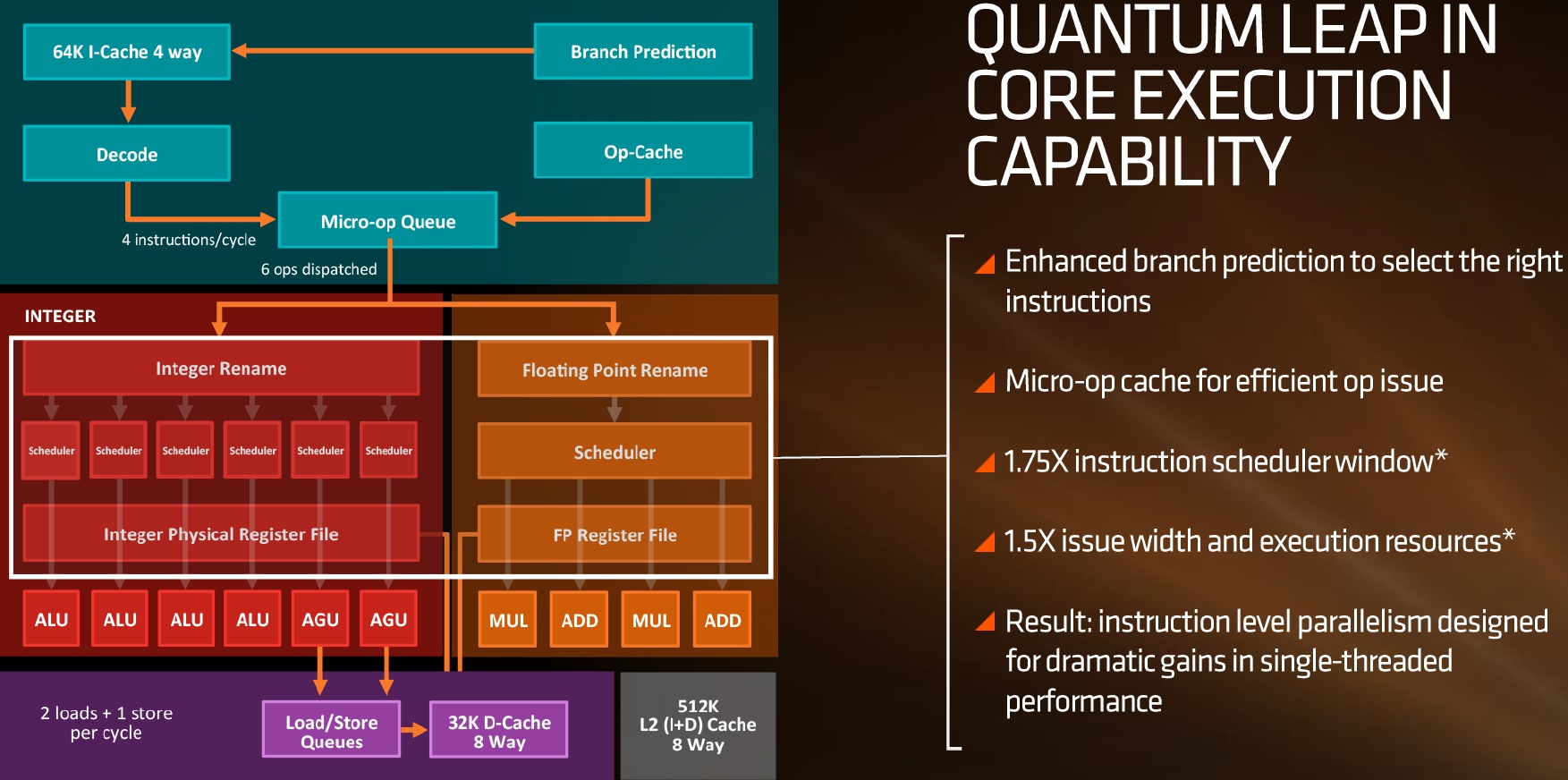
Neben vielen anderen Architekturverbesserungen hat die Firma auch einen Micro-op-Cache integriert, um den L1- und L2-Cache für häufig genutzte Mikrooperationen übergehen zu können. AMD will außerdem die Branch Prediction Engine verbessert, das Instruction-Scheduler-Fenster um das 1,75-fache vergrößert und die L1- und L2-Cache-Performance um das annähernd 2-fache erhöht haben.
Pure Power
AMDs SenseMI-Suite besteht eigentlich aus fünf Schlüsseltechnologien, dank denen AMDs Ryzen-Prozessoren Performance- und Leistungsaufnahmeparameter in Echtzeit anpassen können. Beginnen wir zunächst mit dem, was AMD gern als „Pure Power“ bewirbt. AMDs Zen-Architektur nutzt ein Array von 1000 empfindlichen Sensoren die bis auf 1mAh, 1mV und ein 1C genau messen sollen. AMDs Pure-Power-Funktion überwacht Temperatur und Spannung und erlaubt so Parameteranpassungen in Echtzeit, die anhand Entscheidungen lernender Algorithmen durchgeführt werden.
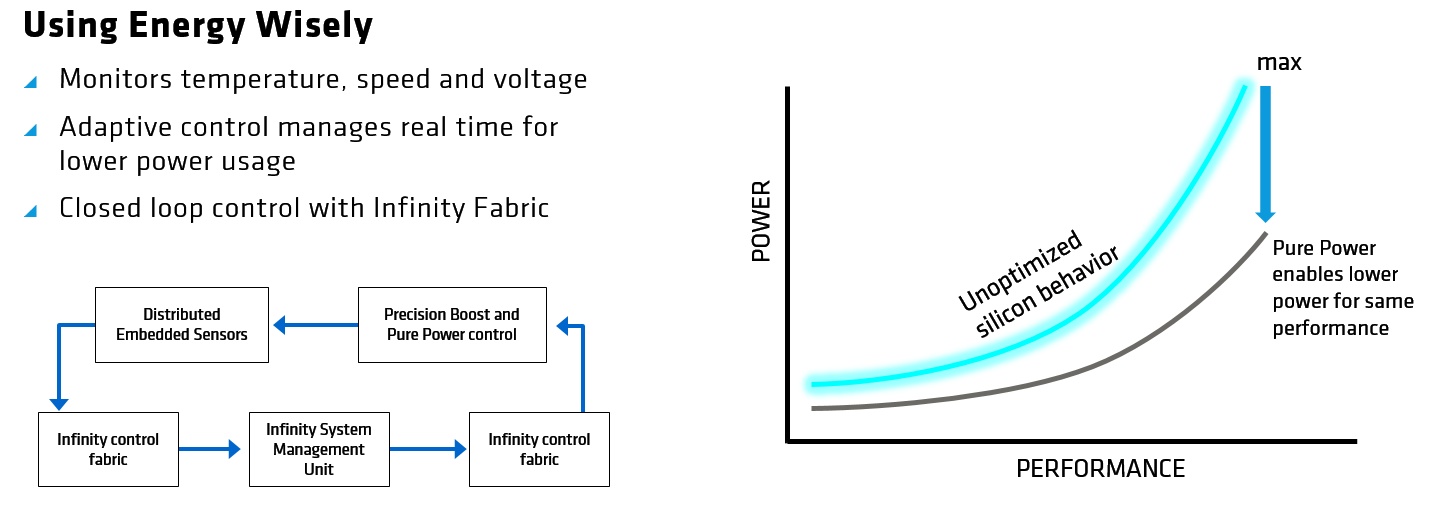
Diese Sensoren füttern die Infinity System Management Unit in 1000-ms-Intervallen über die Infinity-Fabrik-Schleife mit Telemetriedaten. Die Management Engine analysiert die Daten dann und gibt Befehle über die Fabric aus, um Spannung und Taktfrequenz für optimale Performance anzupassen. AMD merkte außerdem an, dass dies bei der Verwaltung von Speculative-Cache-Features und AI-basierter Branch Prediction helfen soll.
Jedes Stück Silizium ist im Detail einzigartig und laut AMD sollen seine Algorithmen es dem Prozessor erlauben, sich selbst anhand seiner einzigartigen Merkmale bestmöglich zu optimieren. An dieser Stelle sei aber angemerkt, dass die meisten aktuellen Prozessoren eine ähnliche Technik nutzen, um ihre Leistungsaufnahme dynamisch anzupassen.
Unsere nachfolgende Bilder-Galerie bietet zum Thema Spannungsversorgung und die Aufteilung zwischen CPU und GPU einen genauen Überblick:






Precision Boost 2
Precision Boost stellt als eine telemetriefähige DVFS-Technologie die Leistungsaufnahme-Performance-Kurve optimal an die jeweiligen Betriebsbedingungen an – ganz ähnlich wie Intels Turbo Boost – und nutzt dazu Informationen, die vom Pure-Power-Feature generiert werden. Die Precision-Boost-Algorithmen passen Takt und Spannung in Echtzeit granulär an – aber wo Intel den Takt in 100-MHz-Schritten anpasst, arbeitet AMD jetzt mit 25-MHz-Steps.
Die Ryzen-Desktop-Prozessoren verwenden diesen Boost-Algorithmus in zwei diskreten Zuständen: Drei oder mehr CPU-Kerne („All-Core Boost“) bzw. Zwei oder weniger CPU-Kerne („Two-Core Boost“). Nur – wenn man z.B. drei Kerne benötigt zieht, dann diese etwas zu simple Logik alle Kerne gleichermaßen nach („all-core boost“), was nicht wirklich optimal und zudem eine unnötige Ressourcenverschwendung ist. Außerdem gibt es eigentlich noch keinen vollen Workload, so dass es auch keine unmittelbar bevorstehende elektrische, thermische oder Nutzungsgrenze gibt, die eine weitere Erhöhung der Taktrate praktisch ausschließen würde. Hier setzt nun die bei den APUs verwendete Version2 an.
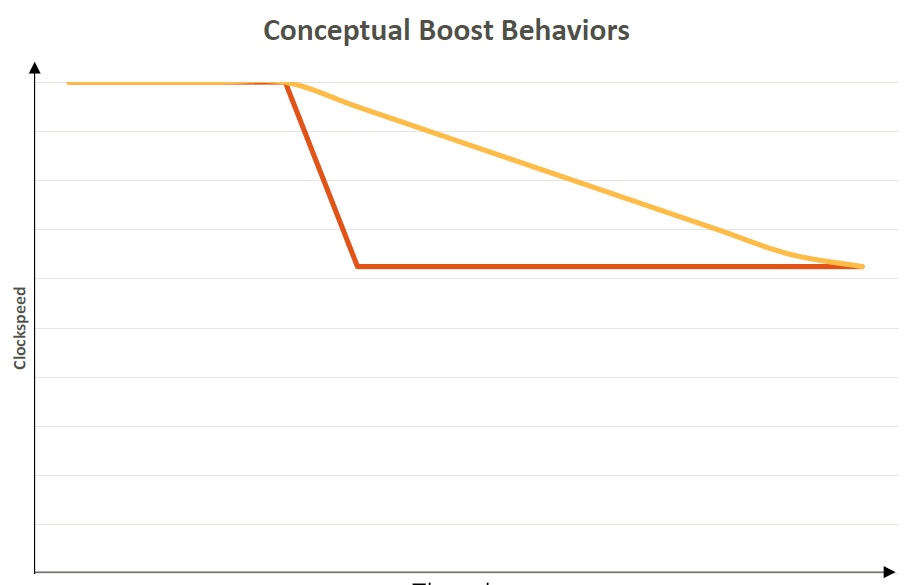
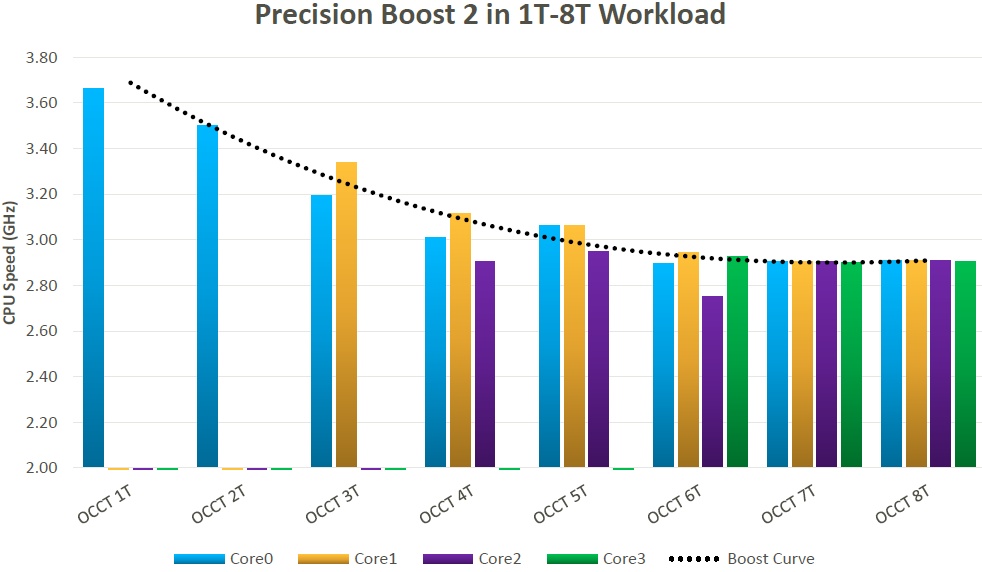
Der noch vorhandene thermische, elektrische und nutzungsbedingte Headroom kann bedenkenlos in höhere Taktraten umgewandelt werden, um die noch bestehenden Reserven besser zu nutzen. Precision Boost 2 setzt somit zwar auch auf die 25-MHz-Schritte des Vorgängers, nutzt jedoch gleichzeitig auch einem Algorithmus, der intelligent die höchstmögliche Frequenz verfolgt, bis eine der oben genannten Grenzen erreicht oder schlicht und ergreifend die maximale Frequenzvorgabe erreicht ist (je nachdem, was zuerst eintritt). Dies gilt für beliebig viele Threads und in Echtzeit, jedoch ohne irgendeine willkürliche Begrenzungen. Precision Boost 2 ist somit eine echte Weiterentwicklung, wie die beiden Grafiken zeigen.
Neural Net Prediction & Smart Prefetch
Laut AMD besteht seine Neural Net Prediction aus einem neuralen Netzwerk, das am Verhalten von Anwendungen lernt, so dass CPU-Instruktionen bereitstehen, bevor sie benötig werden.
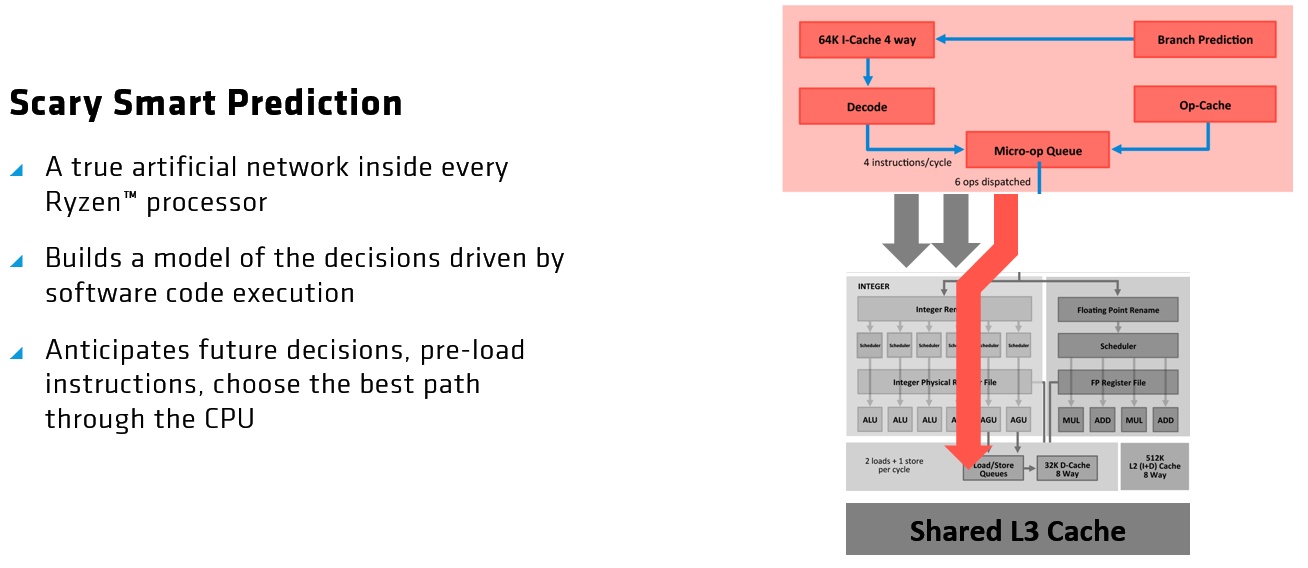
Smart Prefetch wiederum wählt den besten Datenpfad durch die CPU und lädt für schnellere Ausführung Daten in Cache-Speicher, bevor sie gebraucht werden.

Beide Features sind natürlich erst einmal Marketing-Label für AMDs Perceptron Branch Predictor. Diesen Begriff wiederum kennen wir bereits seit AMDs Jaguar-Kernen und man hat diese Sprungvorhersage für die Zen-Mikroarchitektur einfach nur weiter optimiert. Aber es ist letztlich nichts Anderes als eine gebräuchliche Technologie. Abgesehen von den üblichen Marketing-Schlagworten bietet die Zen-Mikroarchitektur jedoch deutliche Innovationen und Vorteile im Vergleich zu den vorherigen AMD-Architekturen.
- 1 - Einführung und Testsystem
- 2 - Ryzen als Basis, aber mit Verbesserungen
- 3 - Kernschmelze von Zen und Vega für die Grafik
- 4 - Gaming: Vorwort und 3DMark
- 5 - Gaming: Battlefield 1
- 6 - Gaming: Civilization VI
- 7 - Gaming: Grand Theft Auto V
- 8 - Gaming: Dota
- 9 - Gaming: Far Cry Primals
- 10 - Gaming: The Witcher 3
- 11 - Anwendungs- und Office-Benchmarks
- 12 - Zusammenfassung und Fazit
















Kommentieren