













Infinity Fabric und die Brücke zwischen allen Teilen
AMDs „Infinity Fabric“ ist ein flexibles und kohärentes Interface/Bus-System, das es AMD ermöglicht, schnell und effizient ein anspruchsvolles IP-Portfolio in ein kohärentes Die zu integrieren. All diese zusammengesetzten Teile können die Infinity Fabric nutzen, um Daten zwischen den einzelnen CCXen, dem Systemspeicher und anderen Controllern (z.B. Speicher, I/O, PCIe) auszutauschen, die sich auf dem Package befinden.
Die Infinity Fabric gibt der „Zen“-Architektur damit auch die nötigen Befehls- und Steuerungsmöglichkeiten für die Echtzeitschätzungen und Anpassungen von Kernspannung, Temperatur, Leistungsaufnahme, Taktfrequenz und mehr. Diese Befehls- und Steuerungsfunktionalität ist auch für AMDs SenseMI-Technologie von entscheidender Bedeutung, auf die wir auf der vorigen Seite bereits eingegangen sind.
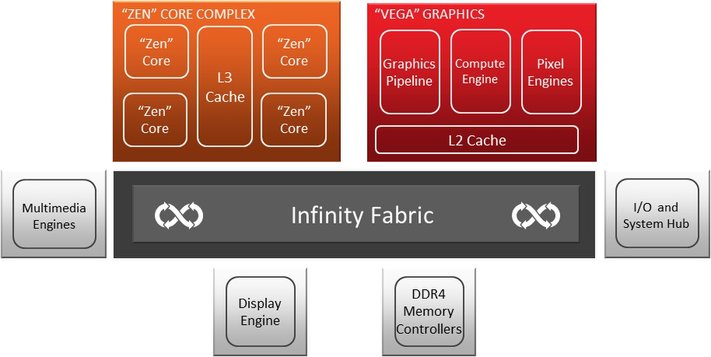
Mit der auf der „Vega“-Architektur basierenden und der APU ebenfalls integrierten Grafikeinheit, bietet AMD eine neue GPU-Generation an, in die über 200 Änderungen und Verbesserungen bei der Umgestaltung der Architektur geflossen sein sollen. Auch wenn es am Ende wohl eher auf eine Art neue GCN-Generation hinausläuft: AMD betont immer wieder, dass es sich um eine komplett neu geschaffene Lösung handelt.
Die Implementierung der mobilen Vega-Ableger finden wir aber nicht nur in den beiden heute vorgestellten APUs sondern auch in den sicher bald gelaunchten Semi-Custom-Chips von Intel, bei denen aber ein komplett anderer Ansatz gewählt wurde. Es wird spannend sein zu sehen, wie sich beide Lösungen in der nahen Zukunft schlagen werden und wo die jeweiligen Vor- und Nachteile finden lassen. Ohne einen direkten Vergleich kann man nur schlecht auch nur irgendetwas vorhersagen.

Neue programmierbare Geometrie-Pipeline
Erinnern wir uns kurz zurück: Die erste Hawaii-GPU auf der Radeon R9 290 X brachte seinerzeit einige durchaus bemerkenswerten Verbesserungen im Vergleich zur Tahiti-GPU auf der Radeon HD 7970 mit. Eine davon betraf ein verbessertes Frontend mit nunmehr vier statt zwei Geometrie-Einheiten, von denen jede einzelne wiederum jeweils einen Geometry-Assembler, einen Vertex-Assembler und eine Tessellation-Einheit besaß.
Die darauffolgende Fiji-GPU als Radeon R9 Fury X setzte dann zwar erneut auf diese bereits von Hawaii bekannte Konfiguration, brachte aber dafür einige andere Neuerungen – beispielsweise eine deutlich gesteigerte Tessellation-Performance – mit. Aktuell nutzt die Ellesmere-GPU (Radeon RX 480) eine neue Handvoll Techniken, um aus der gleichen Konstellation mit den vier Geometrieeinheiten durch diverse Filteralgorithmen bzw. das Verwerfen unnötiger Polygone einen Leistungsvorteil herauszuarbeiten.
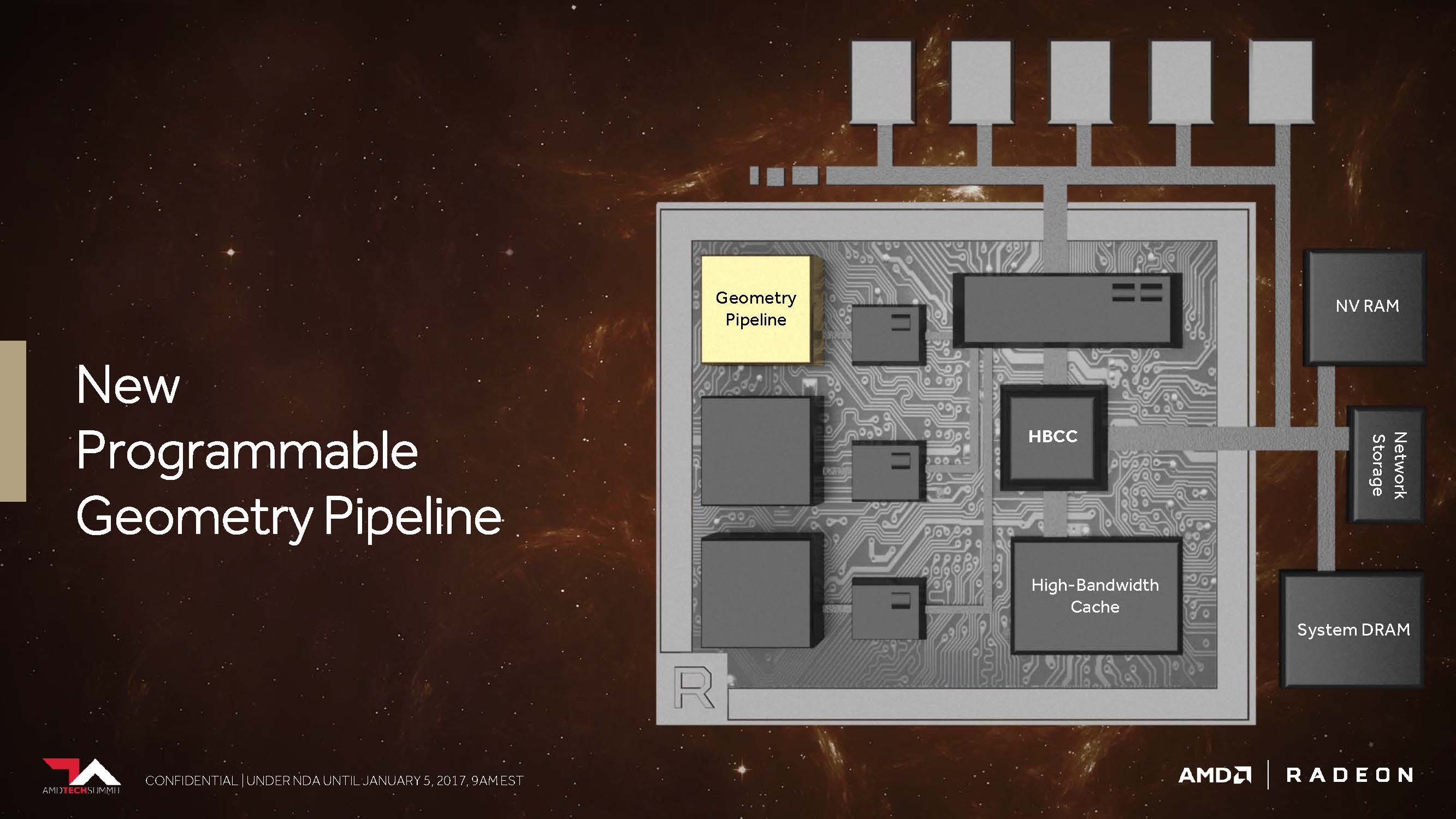
AMD versprach uns bereits letztes Jahr, dass Vega nunmehr in der Lage sein soll, in der Spitze immerhin bis 11 statt der maximal vier Polygone per Taktzyklus abarbeiten zu können, was dem bis zu 2,75-fachen entspricht. Dies soll dann die Folge dessen sein, was AMD als „New Primitive Shader Stage“ in die Geometrie-Pipeline eingefügt hat. Anstelle der in der Hardware fest verankerten, dadurch jedoch unflexiblen Funktionen nutzt man laut AMD (Tech Day in Sonoma, 2017) ein flexibel ausgelegtes Shader-Array für die Verarbeitung der anfallenden Polygone.
Vergleichen kann man dies am ehesten mit der Funktionalität eines Compute-Shaders für die Verarbeitung der Geometrieaufgaben – leicht und programmierbar sowie mit der Fähigkeit ausgestattet, nicht benötigte Polygone mit einer hohen Rate auch verwerfen zu können. Natürlich enthält diese Shader-Funktionalität auch vieles von dem, was auch DirectX mit seinen Vertex-, Hüllkurven-, Domain- und Geometrie-Shader-Stufen anbietet, aber man möchte flexibler sein, in welcher Reihenfolge und Priorität die eigentliche Abarbeitung erfolgt.
Nach all den bisher seit dem Vega-Launch aufgetretenen Diskussionen hat AMD die Aussagen zu dieser Option noch einmal präzisiert und auch ein geändertes Schema zur Verfügung gestellt.
Die neue primitive Shader-Unterstützung von „Vega“ ermögliche es danach, Teile der Geometrie-Verarbeitungs-Pipeline zu kombinieren und durch einen neuen, hocheffizienten Shader-Typ zu ersetzen (Bild unten). Diese flexiblen, universell einsetzbaren Shader können zusätzlich implementiert werden und ermöglichen dann mehr als das Vierfache der maximalen primitiven Cull-Rate pro Taktzyklus.
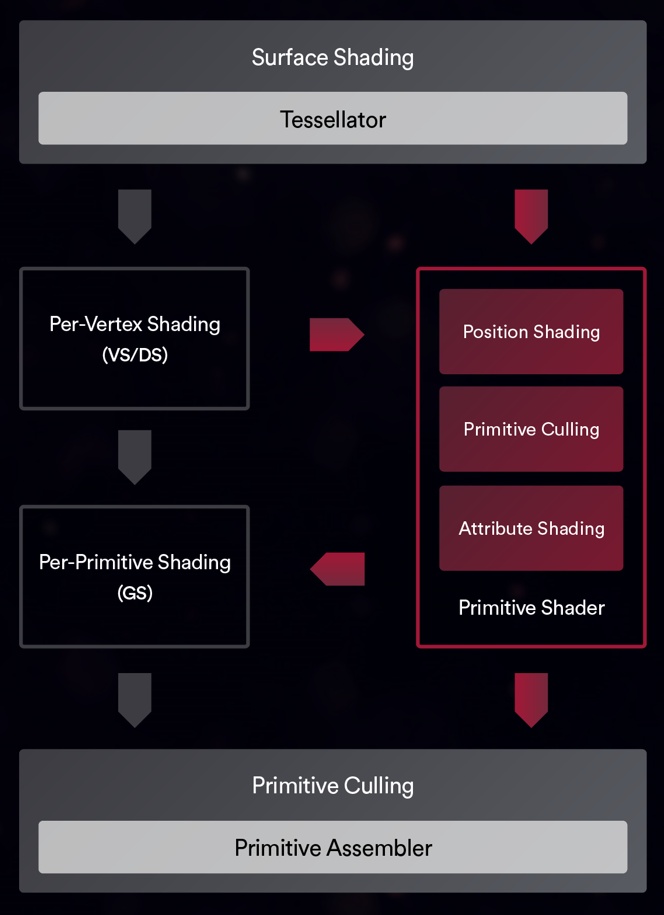
Der Ansatz dafür ist logisch, denn in einer typischen Szene wird etwa die Hälfte der Geometrie durch verschiedene Techniken wie Frustum Culling, Backface Culling und Small Primitive Culling verworfen. Je schneller diese Primitive verworfen werden, desto schneller kann der Grafikprozessor auch mit dem Rendern der sichtbaren Geometrie beginnen.
Darüber hinaus verwerfen herkömmliche Geometriepipelines Primitive erst, nachdem die Vertexverarbeitung abgeschlossen ist, was zu einer unnötigen Verschwendung von Rechenressourcen und Engpässen bei der Speicherung einer großen Menge unnötiger Attribute führen kann. Primitive Shader ermöglichen im Gegensatz dazu eine frühzeitige Entfernung, um diese Ressourcen zu schonen.
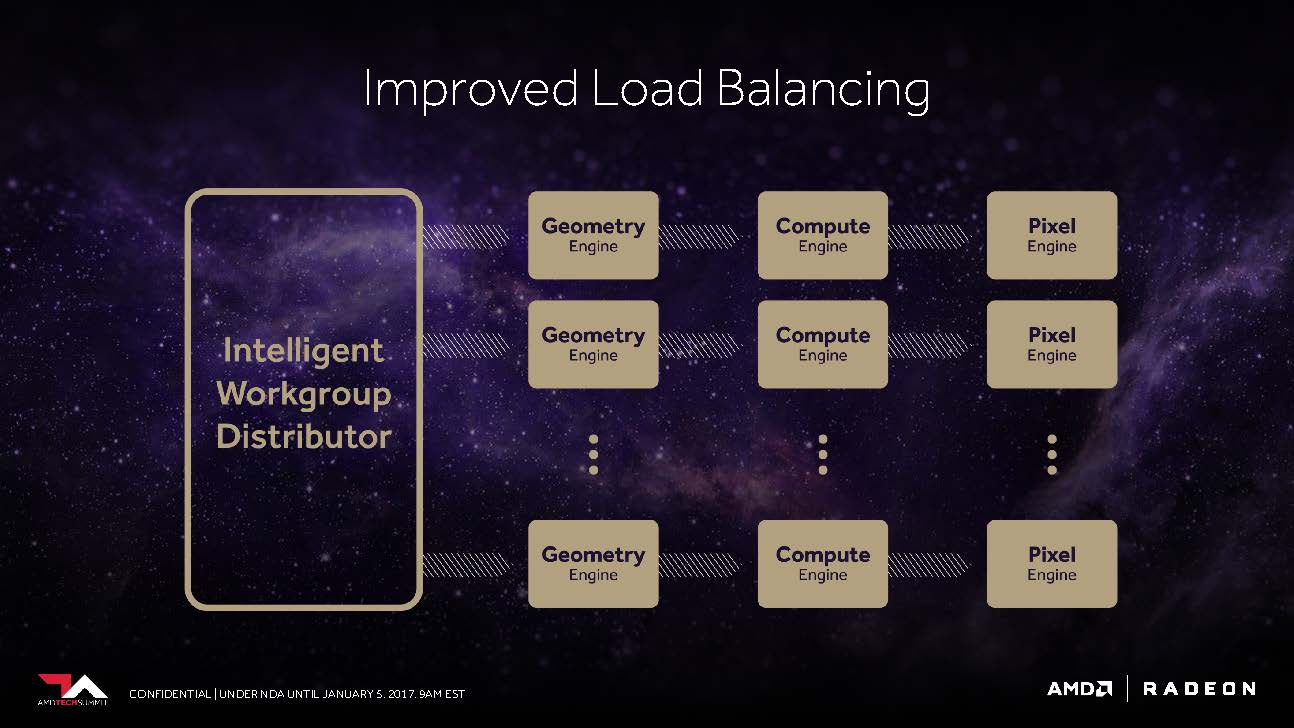
Das Frontend profitiert auch von einem verbesserten „Workgroup Distributor“, dem es gelingen soll, das Load-Balancing rund um die nunmehr programmierbare Hardware möglichst optimal zu gewährleiten.
Die Vega-NCU (Next-Generation Compute Unit)
GPUs verwenden heute oft mehr mathematische Präzision, als für die Berechnungen, die sie gerade durchführen, eigentlich nötig gewesen wäre. Vor Jahren wurde die GPU-Hardware ausschließlich für die Verarbeitung der 32-Bit-Gleitkommaoperationen optimiert, die zum Standard für 3D-Grafiken geworden waren. Da die Rendering-Engines jedoch immer ausgereifter geworden sind und die Anwendungsbereiche für Grafikprozessoren über die Grafikverarbeitung hinausgehen, ist der Wert von Datentypen jenseits von FP32 gestiegen.
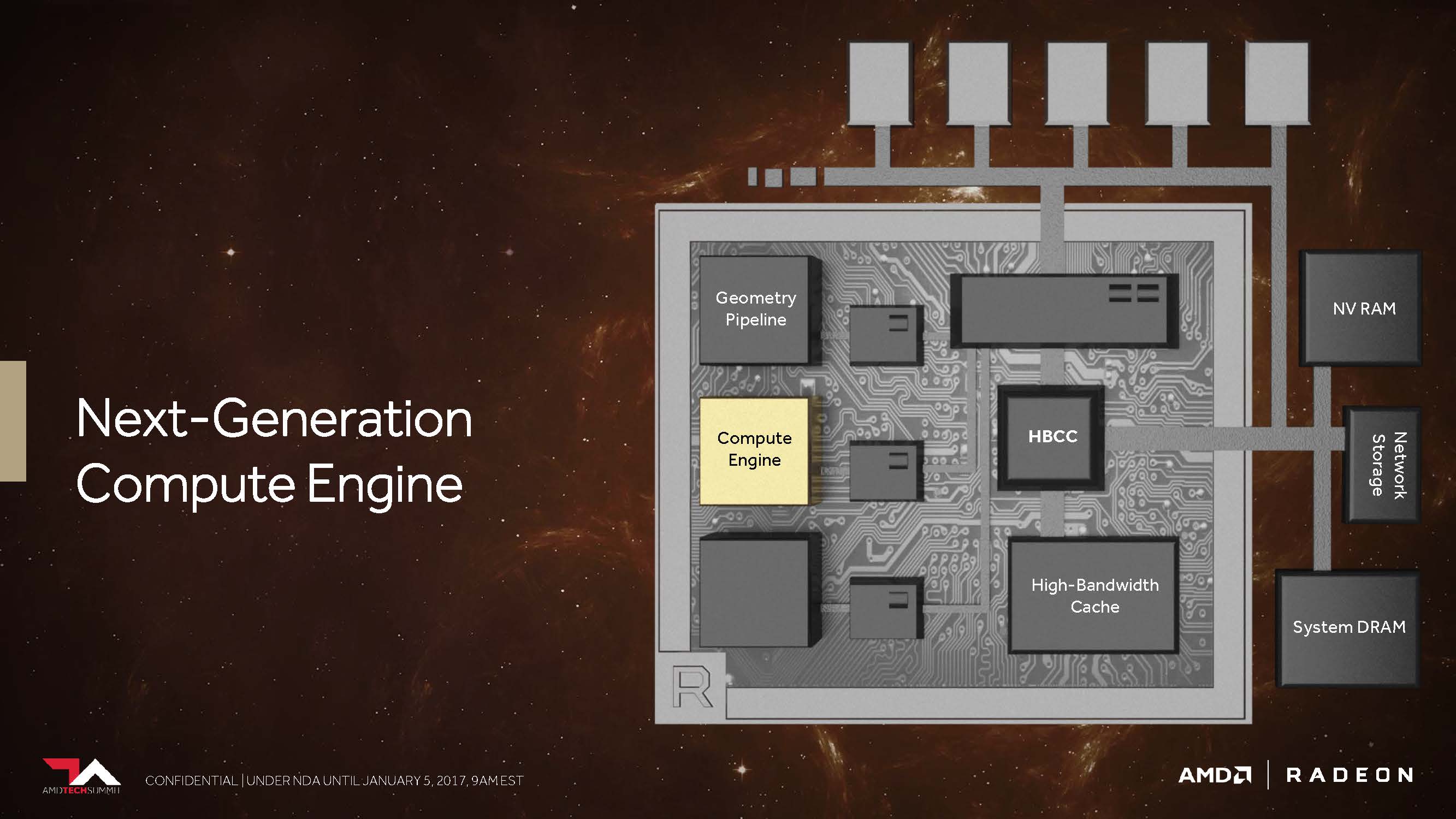
Doch was hat Vega, was z.B. Polaris noch nicht hatte? Der CU-Block mit seinen 64 zu IEEE 754-2008 kompatiblen Shadern bleibt als solcher bestehen – nur, dass AMD ihn jetzt NCU (Next-Generation Compute Unit) nennt, der auch die Unterstützung für neue Datentypen beinhaltet. Logischerweise ergeben dann diese 64 Shader samt Ihrer Maximalleistung von zwei Gleitkomma-Operationen pro Zyklus ein Maximum von 128 32-Bit-Operationen pro Takt.
Die programmierbaren Recheneinheiten, die das Herzstück der „Vega“-Grafikprozessoren bilden, wurden dafür mit einer zusätzlichen Funktion namens Rapid Packed Math versehen. Die erweiterte Unterstützung für 16-Bit-gepackte Inhalte verdoppelt die Gleitkomma- und Integerraten im Vergleich zu den bekannten 32-Bit-Operationen. Es halbiert auch den Registerraum sowie den Datenfluss, der für die Verarbeitung einer bestimmten Anzahl von Operationen erforderlich ist. Der neue Befehlssatz enthält eine reichhaltige Mischung aus 16-Bit Fließkomma- und Integerbefehlen, einschließlich FMA, MUL, ADD, MIN/MAX/MED, Bitverschiebungen, Packoperationen und vielem mehr.

Im Detail bedeutet das Folgendes: Nutzt man mit F16 gepackte Berechnungen, ergeben sich daraus bereits bis zu 256 16-Bit-Operationen pro Takt. AMD schlussfolgert daraus, dass es unter optimalen Voraussetzungen sogar bis zu 512 8-Bit-Operationen pro Taktzyklus sein könnten. Der Anstoß für diese Flexibilität dürfte wohl aus der Konsolenwelt gekommen sein. Immerhin wissen wir ja, dass Sonys PlayStation 4 Pro bis zu 8,4 TFLOPS bei der FP16-Performance erreichen kann, also das Zweifache ihrer Leistung bei 32-Bit-Operationen.
Für Anwendungen, die diese Fähigkeit nutzen können, kann Rapid Packed Math somit eine erhebliche Verbesserung des Rechendurchsatzes und der Energieeffizienz bieten (Abbildung 8). Im Falle von spezialisierten Anwendungen wie maschinelles Lernen und Training, Videoverarbeitung und VR sind 16-Bit-Datentypen eine naheliegende Lösung, aber es gibt darüber hinaus auch Vorteile für traditionellere Rendering-Operationen.
Moderne Spiele beispielsweise verwenden neben dem Standard FP32 eine Vielzahl von Datentypen. Normal-/Richtungsvektoren, Lichtwerte, HDR-Farbwerte und Blendfaktoren sind nur einige Beispiele für die Verwendung von 16-Bit-Operationen.

Unter Umständen ist es am Ende sogar beides, um auch in Bereichen außerhalb von Nvidias aktueller Marktpräsenz zu wildern. In beiden Fällen können neue Konsolen, ganze Rechenzentren und natürlich auch PC-Gamer sowie semi-professionelle Anwender im gleichen Maße profitieren. Neben dem Umstand, dass die NCUs auch für höhere Taktraten optimiert worden sind, setzt gleichzeitig auch auf größere Anweisungspuffer (Instruction Buffer), um die Recheneinheiten über die gesamte Zeit möglichst gut auslasten zu können. Und was der dedizierten Desktop-Grafikkarte recht ist, kann einer integrierten Grafik in der APU nur billig sein.
Next-Generation Pixel Engine
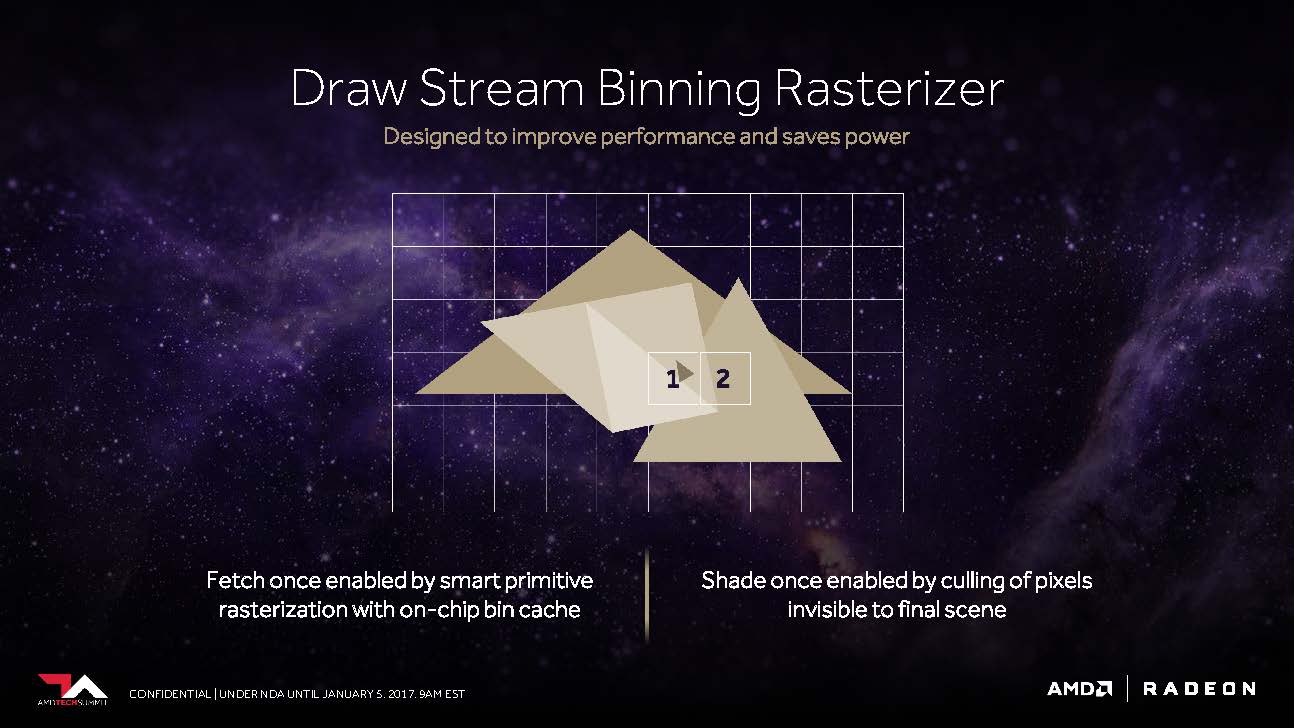
Kommen wir nun noch kurz zu dem, was AMD als „Draw Stream Binning Rasterizer“ bezeichnet und das als Ergänzung des traditionellen ROP in der Lage sein soll, die Performance zu steigern, sowie trotzdem gleichzeitig auch noch Energie zu sparen.
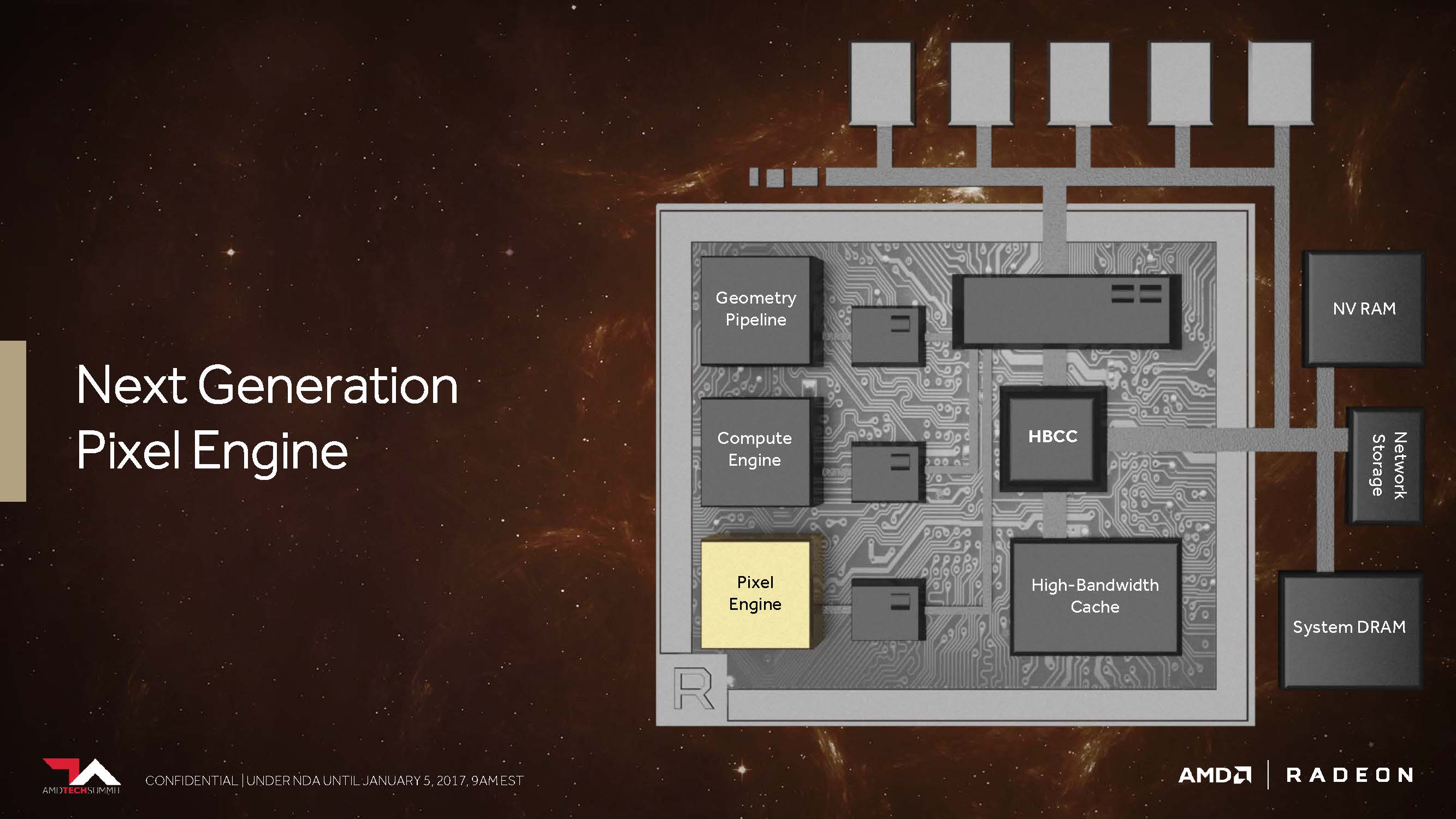
So soll es ein spezieller Cache auf dem Chip ermöglichen, dass der Rasterizer die Daten für sich überschneidende Polygone nur einmal bearbeiten muss und all jene Pixel weglässt, die in der fertigen Szene sowieso nicht sichtbar wären.
Der zweite Punkt ist der, dass AMD seine Cache-Hierarchie generell und grundlegend so geändert hat, dass die Back-Ends für das Rendering nun direkt am L2-Cache angebunden sind.
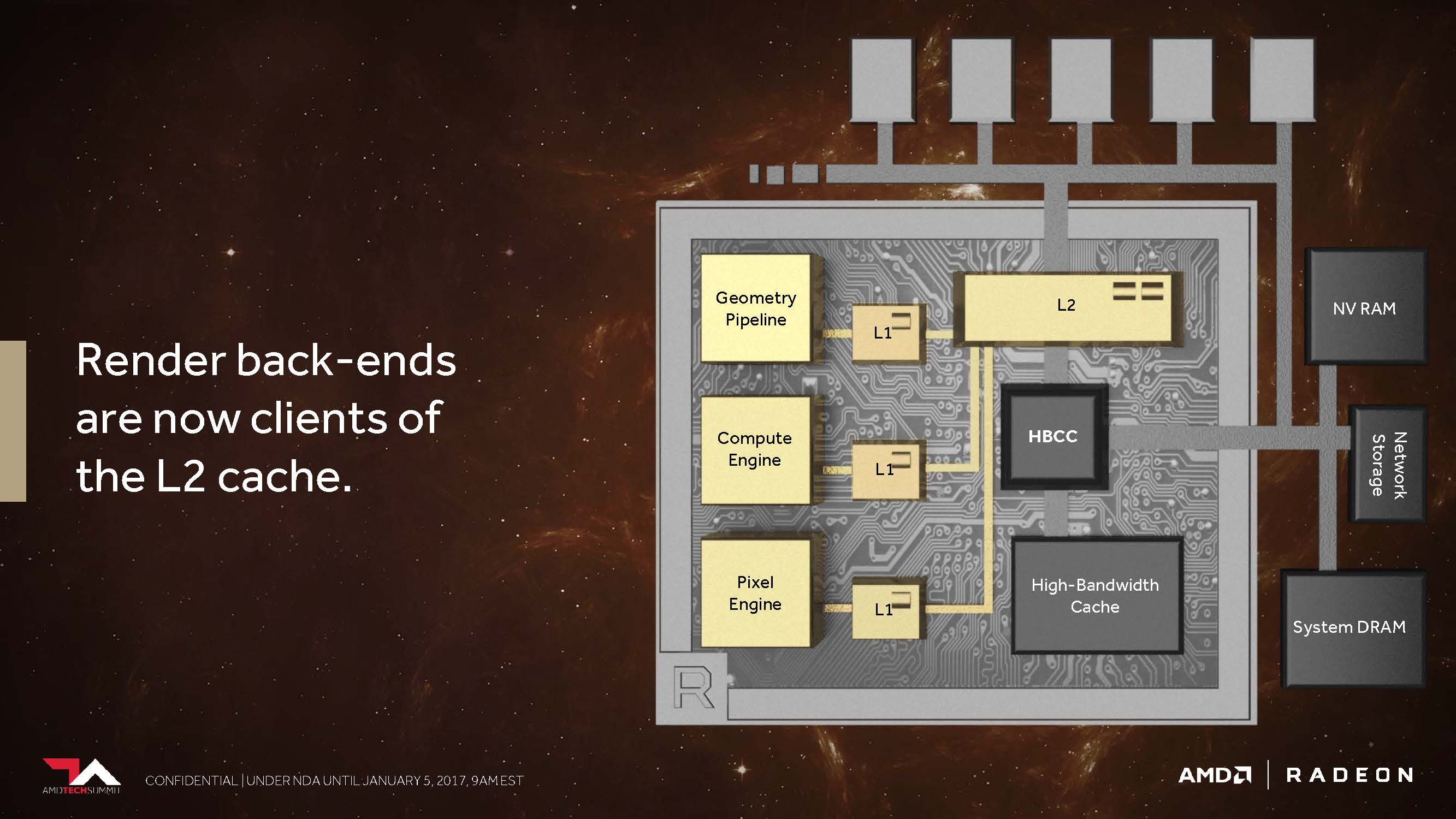
In den Architekturen vor Vega besaß AMD weder für nicht-kohärente Pixel noch die Texturen einen passenden Speicherzugriff, der es den einzelnen Pipelinestufen ermöglicht hätte, diese über einen gemeinsam genutzten Punkt zu synchronisieren. So wurde beispielsweise eine Textur, die als Resultat einer Szene für die spätere Verwendung gerendert wurde, wieder den ganzen Weg zurück bis hin zum Grafikspeicher außerhalb des Grafikchips geschickt, bevor sie dann erneut aufgerufen werden konnte. Dies alles umgeht AMD nun mit dem kohärenten Zugriff, welcher – so sagt es jedenfalls AMD – immer dann eine enorme Performance-Steigerung bieten soll, wenn beispielsweise Deffered Shading zum Einsatz kommt.
- 1 - Einführung und Testsystem
- 2 - Ryzen als Basis, aber mit Verbesserungen
- 3 - Kernschmelze von Zen und Vega für die Grafik
- 4 - Gaming: Vorwort und 3DMark
- 5 - Gaming: Battlefield 1
- 6 - Gaming: Civilization VI
- 7 - Gaming: Grand Theft Auto V
- 8 - Gaming: Dota
- 9 - Gaming: Far Cry Primals
- 10 - Gaming: The Witcher 3
- 11 - Anwendungs- und Office-Benchmarks
- 12 - Zusammenfassung und Fazit















Kommentieren