











Nach fast vier Tagen Reise und einem vollgepackten Tag im kalifornischen Sonoma beim AMD Technology Summit sind wir nun endlich zurück und haben jede Menge Informationen mitgebracht, die wir nun – in von AMD auferlegter Salami-Taktik – Stück für Stück veröffentlichen dürfen.
AMDs Dr. Lisa Su (CEO), Mark Papermaster (CTO), Raja Koduri (Radeon Technologies Group Chief Architect) und viele andere stellten uns dabei im Rahmen dieser Veranstaltung in sehr komprimierter Form AMDs aktuelle Projekte vor, wobei es natürlich auch um Zen und Vega ging.
 Raja Koduri
Raja Koduri
Zumindest Vega tauchte schon einmal kurz auf, als es um die zuerst eingeführten drei Beschleunigerkarten ging, die AMD voll aufs Deep Learning ausgerichtet hat – denn die schnellste dieser drei Karten basiert bereits auf dem neuen Vega-Chip. Doch dazu gleich mehr; zunächst wollen wir noch einmal kurz auf Deep Learning eingehen, was so neu eigentlich gar nicht ist.

Künstliche neuronalen Netze an sich sind keine Neuheit. Aber mit immer mächtigeren Rechenwerken lassen sich solche Rechenverfahren, die sich sehr dicht an der Arbeitsweise des Gehirns orientieren und dabei ein dicht verwobenes Netz einfacher Nervenzellen simulieren, mittlerweile recht eindrucksvoll realisieren.
Der Vorteil ist, dass diese nachgebildeten neuronalen Netze extrem anpassungsfähig sind, indem sie die Stärke der simulierten Neuronenverbindungen exakt den aus der Erfahrung gezogenen Schlüssen anpassen.
Radeon Instinct und MIOPen
Doch zurück zu den dafür geplanten Beschleuniger-Karten für Radeon Instinct. Das Single-Slot-Einstiegsmodell MI6 basiert auf einer Polaris-GPU, die mittelschnelle und sehr kurze MI8 auf einem Fiji-Prozessor (wie er analog auch auf der Radeon R9 Nano eingesetzt wurde) und die MI25 als Flaggschiff letztendlich auf einer Vega-GPU.
Auch wenn AMD betont, dass alle drei Modelle passiv gekühlt sind, ist es schon wie bei der FirePro S10000 so, dass im Gegenzug dazu ganz konkrete Richtlinien dafür gelten, wie die betreffenden Racks als Einheit aktiv zu kühlen sind. Das dies dann eher nicht so leise geschehen dürfte, ist sicher auch klar.
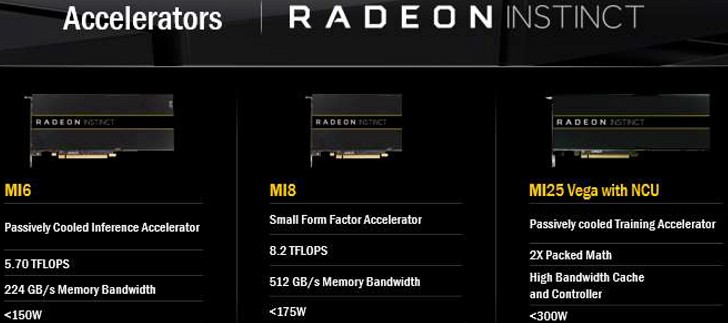
Die Radeon Instinct MI6 ist mit 16 Gigabyte Arbeitsspeicher bestückt und besitzt in etwa die gleiche Leistung wie AMDs Radeon RX 480. Eine angenommene maximale FP16-Rate von 5,7 TFLOPS ermöglicht es uns, auf eine Taktfrequenz von circa 1240 MHz rückzuschließen. Die angegebene Speicherbandbreite von 224 GByte/s entspricht zudem genau den sieben GBit/s von GDDR5, wie wir sie auch auf den kleineren Versionen der Radeon RX 480 mit nur vier GB Speicherausbau vorfinden.
Wie Polaris hat auch der Fiji-Prozessor ein 1:1-Verhältnis von FP16 zu FP32, so dass die MI8 mit den avisierten 8,2 TFLOPS identisch ist mit dem, was eine Radeon R9 Fury Nano bei einer Kernfrequenz von 1000 MHz und allen 4096 Shadern leisten kann. Natürlich ist diese Karte mit HBM1-Speicher auf vier Gigabyte Speicherausbau begrenzt, erbt aber auch die Übertragungsrate und restlichen Spezifikationen.
Das Flaggschiff MI25 basiert endlich auf der noch nicht gelaunchten Vega-basierten GPU, so dass Einschätzungen zur wirklichen Leistungsfähigkeit gelinde gesagt schwer fallen. Aber wer bis hierher aufmerksam mitgelesen hat, dem wird auch am Namensschema etwas aufgefallen sein. Die Zahl basiert nämlich bei den beiden anderen Karten auf der FP16-Leistung, so dass man annehmen könnte, es handele sich um eine Karte mit bis zu 25 TFLOPS!
Diese auf den ersten Blick so gewaltig anmutende Zahl wird bei Vega durch eine flexiblere Mixed-Precision-Engine ermöglicht, die zwei gleichzeitig ausgeführte 16-Bit-Operationen über die 32-Bit-Pipelines der Architektur unterstützt. Setzt man nun das Verhältnis von 1:2 an, ergäben sich bei FP32 immerhin noch 12,5 TFLOPS.
Auch Sonys Playstation 4 Pro profitiert von dieser Funktionalität und wir könnten wetten, dass wir sie auch in anderen kommenden Grafikprodukten von AMD wiederfinden werden. Viele On-Package-Module mit HBM2-Speicher und die enorme Rachenleistung machen gerade diese Karte für größere Workloads interessant.
Doch was treibt AMD eigentlich dazu, die FP16-Leistung so nach oben zu treiben? Die akademische Forschung hat gezeigt, dass FP16 (“Half Precision”) beim Deep Learning eine ähnliche Genauigkeit wie FP32 besitzt. Damit gelingt es, bei ähnlicher Genauigkeit mit einer Technologie, wie sie bei Vega genutzt wird, die Spitzenleistung faktisch zu verdoppeln.
Da wundert es auch nicht, dass AMD diese Informationen so schnell wie möglich veröffentlichen möchten, denn Nvidias GP100 unterstützt ebenfalls gemischte Präzision und liefert für FP16 bei maximalem Boost bis zu 21,2 TFLOPS. Darüber hinaus forciert man dort ja auch noch CUDA 8.
Nutzung der Hardware mit MIOPen
Während wir noch Monate von der Verfügbarkeit der Vega-basierten Hardware entfernt sind, kann AMD zumindest die Software-Seite seiner Geschichte bereits einbringen, um Entwickler dazu zu bewegen, sich mit der Programmierung dieser Systeme zu befassen.
So stellte man uns ebenfalls die MIOpen-Software-Bibliothek für die Radeon-Instinct-Karten vor, wo man als Verfügbarkeit das erste Quartal 2017 nannte. Erste, vorläufige Benchmark Ergebnisse – beispielsweise Deep Bench von Baidu Research, wo man zudem nur einen sehr frühen FP32-Test (GEMM) herauspickte – zeugen von einem noch recht frühen Stadium der Hardware.

AMD verwendet eine GeForce GTX Titan X (Maxwell) für die Basislinie.Diese Karte besitzt eine FP32-Spitzenleistung von 6,14 TFLOPS unter Verwendung ihres Basistaktes ohne Boost. Die Titan X (Pascal) leistet dank einer meist deutlich höheren GPU-Taktrate bereits 10,2 TFLOPS.
Mit seiner MIOpen-Bibliothek kann die auf dem Papier 8,2 TFLOPS leistende Radeon Instinct MI8 das Flaggschiff von Nvidia – wenn auch nur knapp – laut Grafik sogar noch schlagen. Zuimdest in diesem Test ist die MI25 zudem fast 50 Prozent schneller als Nvidias Pascal-basierte Titan X und sogar 90 Prozent schneller als der Vorgänger, die Maxwell-basierte Titan X.
Basierend auf dem, was wir über das Mischpräzisions-Handling von Vega wissen, können wir somit vermuten, dass MI25 eine FP32-Rate von rund 12 TFLOPS hat. Um diesen Vorteil am Ende aber wirklich zu erreichen, muss MIOpen laut AMD für die Hardware jedoch wirklich optimiert sein.

Die MIOpen-Bibliothek (ROCm) ist jedoch nur ein Teil von AMDs Software-Strategie und ordnet sich an der Spitze der Open-Source-Plattform mit Dingen wie Radeon Open Compute für den Heterogeneous Compute Compiler, HIP (zur Umwandlung von CUDA-Code in portable C ++), OpenCL und Python ein. ROCm bietet außerdem Unterstützung für NCCL (eine Bibliothek kollektiver Kommunikationsroutinen für Multi-GPU-Topologien), alle relevanten Mathematik-Bibliotheken und die C ++ – Standardvorlagenbibliothek.
Anfang 2016 führte AMD bereits seine Karten der FirePro-S-Serie mit Multi-User-GPU-Technologie ein, die auf dem SR-IOV-Standard (Single-Root-I/O-Virtualization) basierten.Dies ermöglichte schon damals VMs direkten Zugriff auf die Grafik-Hardware und erfreute sich beispielsweise fürs Cloud-Gaming recht großer Beliebtheit. AMD setzt MxGPU auch auf den Radeon Instinct-Boards fürs Deep Learning ein und betont zudem gern, dass Nvidia hier eine viel stärkere Trennung zwischen Funktionen und Produkten vornimmt.
Reale Hardware-Lösungen vorgestellt
Neben der ersten Präsentation der Hard- und Software ludt AMD auch einige Systemintegratoren ein, die ihre Vorhaben und erste Lösungen direkt vor Ort vorstellen durften.
Am unteren Ende des Spektrums zeigte Supermicro seinen Superserver 1028GQ-TFT — eine Dual-Sockel-Xeon-E5-basierte 1U-Maschine – bestückt mit vier MI25 Karten und bis zu 100 TFLOPS FP16-Leistung. Sonderlösungen mit Intels Xeon Phi, die FP16 nicht unterstützen, oder Nvidias Tesla P100-Erweiterungskarten stehen auf Supermicros Qualifikationsliste mit Spitzenwerten von bis zu 18,7 TFLOPS pro Einheit und ordnen sich damit unterhalb der MI25 ein.

Deutlich größer ist da schon eine 39U-Plattform von Inventec mit 120 MI25-GPUs, sechs 2U-24-Bay-Servern und sechs 4HE-PCIe-Switches mit bis zu drei PFLOPS. Diese Einheit, so Raja Kodri scherzhaft, passe locker in den Kofferraum seines eigenen Wagens und würde preislich am Ende zusammen mit dem Fahrzeug immer noch deutlich günstiger ausfallen als vergleichbare Mitbewerberprodukte.

Natürlich konnte es sich AMD nicht verkneifen, uns am Schluss eine bevorstehende Zukunft zu präsentieren, in der die Zen-CPUs und Radeon-Instinct-Beschleuniger in einer heterogenen Computing-Umgebung zusammenarbeiten werden. Aber wir sind noch mindestens sechs Monate von der Realisierung solch einer Kombination entfernt, so dass man über das Potenzial einer solchen Verbindung momentan nur spekulieren kann.
Wenn uns das aktuelle Event aber eines gezeigt hat, dann das: AMD müht sich redlich, Boden gutzumachen und den aktuellen Tendenzen nicht nur zu folgen, sondern auch eigene Trends zu setzen. Ob und wie gut das alles gelingt und ob auf dem einen oder anderen Gebiet sogar ein Vorsprung möglich ist, das wird die nähere und mittelfristige Zukunft zeigen müssen.















Kommentieren