











After nearly four days of travel and a packed day in Sonoma, California at the AMD Technology Summit, we're finally back and brought a lot of information that we can now publish piece by piece in AMD-imposed salami tactics.
AMD's Dr. Lisa Su (CEO), Mark Papermaster (CTO), Raja Koduri (Radeon Technologies Group Chief Architect) and many others presented AMD's current projects in a very compressed form, including Zen and Vega.
 Raja Koduri
Raja Koduri
At least Vega appeared briefly when it came to the first introduced three accelerator cards, which AMD has fully focused on deep learning – because the fastest of these three cards is already based on the new Vega chip. But more on that; First of all, let's briefly talk about deep learning, which isn't really new.

Artificial neural networks are not novelty in themselves. But with increasingly powerful arithmetic, such computational methods, which are very closely oriented towards the functioning of the brain and simulate a densely woven network of simple neurons, can now be realized quite impressively.
The advantage is that these replicated neural networks are extremely adaptable by adjusting the strength of the simulated neuron connections exactly to the conclusions drawn from the experience.
Radeon Instinct and MIOPen
But back to the planned accelerator cards for Radeon Instinct. The single-slot entry-level MI6 is based on a Polaris GPU, the medium-fast and very short MI8 on a Fiji processor (as it was also used analogously on the Radeon R9 Nano) and the MI25 as the flagship ultimately on a Vega GPU.
Although AMD emphasizes that all three models are passively cooled, as with the FirePro S10000, in return, there are very specific guidelines for how the racks in question are to be actively cooled as a unit. It is certainly clear that this is unlikely to happen so quietly.
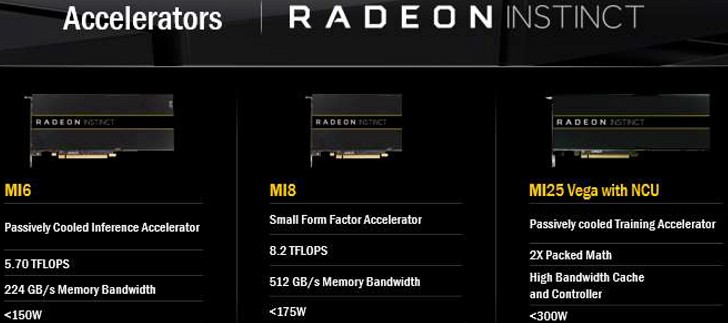
The Radeon Instinct MI6 is packed with 16 gigabytes of memory and has roughly the same performance as AMD's Radeon RX 480. An assumed maximum FP16 rate of 5.7 TFLOPS allows us to backtrack to a clock frequency of approximately 1240 MHz. The specified memory bandwidth of 224 GByte/s also corresponds exactly to the seven Gbps of GDDR5, as we can also find on the smaller versions of the Radeon RX 480 with only four GB of memory expansion.
Like Polaris, the Fiji processor has a 1:1 ratio of FP16 to FP32, so the MI8 is identical to what a Radeon R9 Fury Nano can do at a core frequency of 1000 MHz and all 4096 shaders. Of course, this card with HBM1 memory is limited to four gigabytes of memory expansion, but also inherits the transfer rate and remaining specifications.
The flagship MI25 is finally based on the as yet unlaunched Vega-based GPU, so it's hard to assess real performance, to say the least. But those who have read along carefully up to this point will also have noticed something about the name scheme. The number for the other two cards is based on THE FP16 power, so you might assume it is a card with up to 25 TFLOPS!
At first glance, this huge number is made possible by a more flexible mixed-precision engine that supports two simultaneous 16-bit operations over the architecture's 32-bit pipelines. If you start the ratio of 1:2, FP32 would still have 12.5 TFLOPS.
Sony's Playstation 4 Pro also benefits from this functionality, and we could bet that we'll find it in other amD upcoming graphics products. Many on-package modules with HBM2 memory and the enormous throat performance make this card interesting for larger workloads.
But what is driving AMD to push up FP16 performance? Academic research has shown that FP16 ("Half Precision") has a similar accuracy to FP32 in deep learning. This makes it possible to effectively double peak performance with a technology similar to that used in Vega.
So it's no surprise that AMD wants to release this information as soon as possible, as Nvidia's GP100 also supports mixed precision and delivers up to 21.2 TFLOPS for FP16 at a maximum boost. In addition, CUDA 8 is also being pushed there.
Using hardware with MIOPen
While we are still months away from the availability of Vega-based hardware, AMD can at least bring in the software side of its history to get developers to engage in programming these systems.
We were also introduced to the MIOpen software library for the Radeon Instinct cards, where the first quarter of 2017 was cited as availability. Initial, preliminary benchmark results – for example, Deep Bench from Baidu Research, where only a very early FP32 test (GEMM) was picked – testify to an even early stage of the hardware.

AMD uses a GeForce GTX Titan X (Maxwell) for the baseline. This card has a peak FP32 power of 6.14 TFLOPS using its base clock without boost. The Titan X (Pascal) already delivers 10.2 TFLOPS thanks to a usually significantly higher GPU clock speed.
With its MIOpen library, the paper-based Radeon Instinct MI8 can even beat Nvidia's flagship – albeit narrowly – according to graphics. In addition, the MI25 is almost 50 percent faster than Nvidia's Pascal-based Titan X and even 90 percent faster than its predecessor, the Maxwell-based Titan X.
Based on what we know about Vega's mixed precision handling, we can therefore assume that MI25 has an FP32 rate of around 12 TFLOPS. However, in order to achieve this advantage in the end, MIOpen really needs to be optimized for the hardware, according to AMD.

However, the MIOpen Library (ROCm) is only part of AMD's software strategy and ranks at the top of the open source platform with things like Radeon Open Compute for the Heterogeneous Compute Compiler, HIP (to convert CUDA code into portable C++), OpenCL and Python. ROCm also provides support for NCCL (a library of collective communication routines for multi-GPU topologies), all relevant math libraries, and the C++ standard template library.
At the beginning of 2016, AMD introduced its FirePro-S series cards with multi-user GPU technology based on the Single-Root I/O Virtualization (SR-IOV) standard. This already enabled VMs to have direct access to the graphics hardware and enjoyed quite a lot of popularity for cloud gaming, for example. AMD also uses MxGPU on the Radeon Instinct boards for deep learning and also likes to emphasize that Nvidia makes a much stronger separation between functions and products.
Real hardware solutions presented
In addition to the first presentation of the hardware and software, AMD also invited some system integrators who were able to present their projects and initial solutions directly on site.
At the lower end of the spectrum, Supermicro showed off its 1028GQ-TFT superserver—a dual-socket Xeon E5-based 1U machine—equipped with four MI25 cards and up to 100 TFLOPS FP16 power. Special solutions with Intel's Xeon Phi that don't support FP16 or Nvidia's Tesla P100 expansion cards are on Supermicro's qualification list with peaks of up to 18.7 TFLOPS per unit, below MI25.

A 39U platform from Inventec with 120 MI25 GPUs, six 2U-24 bay servers and six 4U PCIe switches with up to three PFLOPS is already much larger. This unit, Raja Kodri jokingly says, fits loosely into the trunk of his own car and would still be significantly cheaper in price with the vehicle than comparable competitor products.

Of course, AMD couldn't resist presenting us with an imminent future in which the Zen CPUs and Radeon Instinct accelerators will work together in a heterogeneous computing environment. But we are still at least six months away from realizing such a combination, so one can only speculate about the potential of such a connection at the moment.
But if the current event has shown us one thing, it is this: AMD is honestly struggling to make up ground and not only follow the current trends, but also set its own trends. Whether and how well all this succeeds and whether even a lead is possible in one or the other area will have to show the near and medium-term future.

















Kommentieren