











The next generation APU, internally called “Strix”, will be based on a 4-nanometer process. This process promises a balanced combination of performance and energy efficiency. The APU is aimed equally at professional users and those looking for sophisticated entertainment experiences. One particularly notable feature of the “Strix” APU is its innovative Big.Little CPU architecture. The coexistence of 4 Performance cores and 8 Efficiency cores strives for a harmonious balance between processing power and energy consumption.
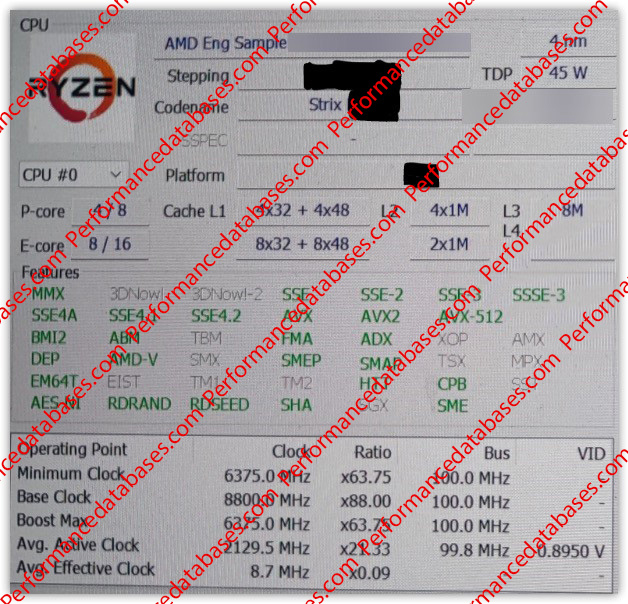
This architecture enables the APU to efficiently handle both compute-intensive tasks and everyday applications. Hyper-threading technology, which is supported by both categories of cores, opens up advanced parallel processing. This means that the APU is able to run multiple tasks simultaneously, resulting in smoother and more responsive performance overall. Hyper-threading support helps optimize the user experience, whether it’s for productive applications with multitasking requirements or seamlessly switching between different applications and games.
Cache memory plays an important role in the performance of modern processors and APUs. In the case of the “Strix” APU, the generous L1 data cache is sized at 48 KB to enable fast data accesses. This ensures a smooth provision of the required data for the cores. In addition, a 32 KB L1 instruction cache is available to support efficient instruction execution and thus increase overall performance. The APU’s performance cores are equipped with a 1 MB cache that keeps frequently used data in close proximity. This minimizes latency to access this data and increases overall performance, especially for compute-intensive tasks that require fast data processing.
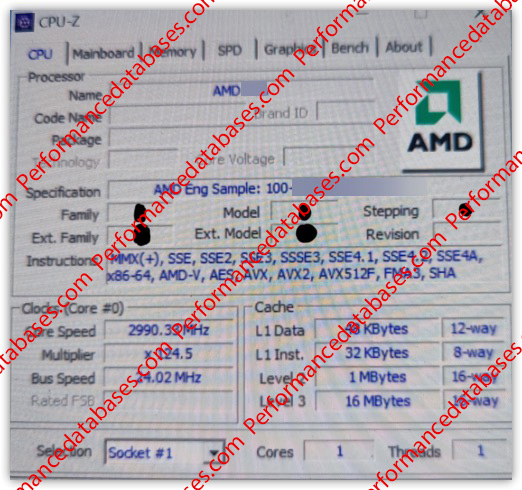
The Efficiency cores use an intelligent cache structure where 4 cores each share a common L2 cache of 1 MB. This approach improves resource utilization and maximizes energy efficiency. The efficiency cores can be used efficiently especially for tasks with low computing demands to achieve an optimal balance between performance and energy consumption. The similarity of the cache design to Intel’s shows how technology innovations can inspire across different manufacturers. However, it should be noted that the “Strix” APU is still in the Engineering Sample phase (ES phase). In this phase, further developments and optimizations take place before the final product is launched.
The developers are aware of this dynamic and have emphasized that they will continuously update the public on the development process. Future updates and progress in the development of the “Strix” APU will be communicated transparently to build anticipation and understanding of this technological innovation. The world can look forward to seeing how the “Strix” APU will take computing performance in new directions.
Source: PerformanceDatabases
















8 Antworten
Kommentar
Lade neue Kommentare
Urgestein
Neuling
Urgestein
Urgestein
Urgestein
Mitglied
Veteran
Alle Kommentare lesen unter igor´sLAB Community →