











Bevor ich mich als (Zukunfts-) Maler betätige und ein mögliches Package samt der bisher bekannten Abmessungen kreiere, sollten wir die Gerüchte und Leaks der letzten Tage noch einmal Revue passieren lassen. Nehmen wir einmal den für gewöhnlich gut informierten Kopite7kimi beim Wort Leak, der einen Tape-Out des GA102-Chips bei Samsung und nicht TSMC auf Twitter nannte. Damit ist ein Launch bereits in 2020 mehr als wahrscheinlich, zumal ja im Hintergrund schon diverse Aktivitäten zu verzeichnen waren, die auch die jeweiligen Boardpartner betrafen. Das Base-Design-Kit für die Platinen und der Thermal Design Guide für die Karten mit dem GA 102 sollen ja schon fleißig verteilt worden sein.
“NO EUV. GA102 has taped out. It was based on SAMSUNG 10nm. (You can call it 8nm?lol~~) And the new tegra will use the same process node.”
Sollte es diesmal also Samsung statt TSMC sein, könnte Nvidia unter Umständen bei TSMC etwas zu hoch gepokert haben, als es um die Preisverhandlungen für die 7-nm-Fertigung (der GA102) ging und man Samsung quasi als Argument für einen möglichen Preisnachlass ins Feld führte. Oder aber Nvidia sieht das Ganze generell unter wirtschaftlichen Aspekten und nutzt zunächst den deutlich günstigeren 8 nm Node von Samsung, der ja eigentlich ein verbesserter 10 nm Node ist. Damit läge immerhin noch ein Full-Node-Sprung zwischen dem, was Samsung bietet und dem was bisher bei TSMC in 12 nm für Nvidia gefertigt wurde.

Betrachtet man die Wirtschaftlichkeit, dürfte ein noch größerer Chip in Samsungs 8 nm Node eh kaum noch ökonomisch einen Sinn ergeben. Damit klingen zudem alle bisher kolportierten Daten zum GA102 und der weiteren Ableger durchaus plausibel. Auch möchte ich noch einmal darauf verweisen, dass man die Nodes nicht wirklich miteinander vergleichen kann. Samsungs 8-nm-Node liegt eigentlich näher an den 10 nm als an den 7 nm, zumal der Fin Pitch zwischen 10 und 8 nm vergleichbar bleibt und nur der Gate Pitch um 6 Prozent reduziert wurde.
Das mögliche Package als Grafik
Und nun kommt mein kleines, hochspekulatives Kunstwerk ins Spiel, das auf kolportieren Abmessungen beruht und sich mit meiner damaligen Hochrechnung recht gut deckt. Die Kantenlängen des Chips ergäben, falls die neuesten Informationen richtig sind, eine Chipfläche von 627,12 mm². Geht man davon aus, dass der Prozess von Samsung gegenüber dem alten Node die gleiche Transistoranzahl auf ca. 40% der Fläche unterbringen kann, dann wäre auch die bereits getätigte Hochrechnung von ca. 6000 bis 6100 Shadern für den Vollausbau bei dieser Chipgröße durchaus realistisch. Wobei sich die Anzahl der Shader natürlich auch auf deren Komplexität bezieht und auch noch niemand sagen kann, wie sich das Verhältnis von CUDA- zu RT- und vor allem auch Tensor-Cores gestalten wird.

Getrennte Spannungsversorgung soll kommen
Ich hatte ja auch schon spekuliert, dass es aus Sicht eines effizienteren Betriebes nötig werden würde, die Spannungsversorgung der CUDA-Cores von der der RT- und Tensor-Cores extern zu entkoppeln und dies nicht mehr in der GPU über verschiedene Pfade zu lösen. Auf das würde noch einmal Platz schaffen und die Effizienz erhöhen. Mit NVDD und MSVDD (“Gedönsspannung”), wäre dann auch dieses kleine Problem elegant aus der Welt geschafft. Zumal der Anteil von MSVDD deutlich höher ausfallen soll and der von VDDCI bei den AMD-Karten. Und was ist dann mit den bereits hochgerechneten 230 Watt, die maximal an die GPU geliefert werden sollen?
Ich denke mal, 60 bis 70 Watt wird man für die zusätzlichen Rechenwerke im GA102-Vollausbau mindestens ansetzen können und wenn man das Ganze von den CUDA-Cores entkoppelt, dann kann auch dort die Versorgung ein wenig einfacher gestaltet werden. Ich hatte in einer früheren Berechnung mit 16 Spannungswandler-Kreisen für die reine GPU-Power bei 230 Watt gerechnet. Dazu kämen für den Speicher, zumindest bei 24-GB-Vollausbau, noch einmal bis zu 4 Regelkreise hinzu.
Auch jetzt kann man natürlich Taschenrechner und Datenblatt nutzen, um hier eine Schätzung vorzunehmen, wie die mögliche Aufteilung der GPU-Spannungen aussehen könnte. Mit etwas Phantasie (und Glück beim Raten), könnte man die Versorgung der Shader mit bis 10 Phasen ansetzen, wobei dann je eine Phase auch nur einen Power Stage ansprechen würde. Die restlichen bis zu 6 Phasen entfielen dann auf eine weitere Teilspannung mit der gleichen Power-Stage-Aufteilung.
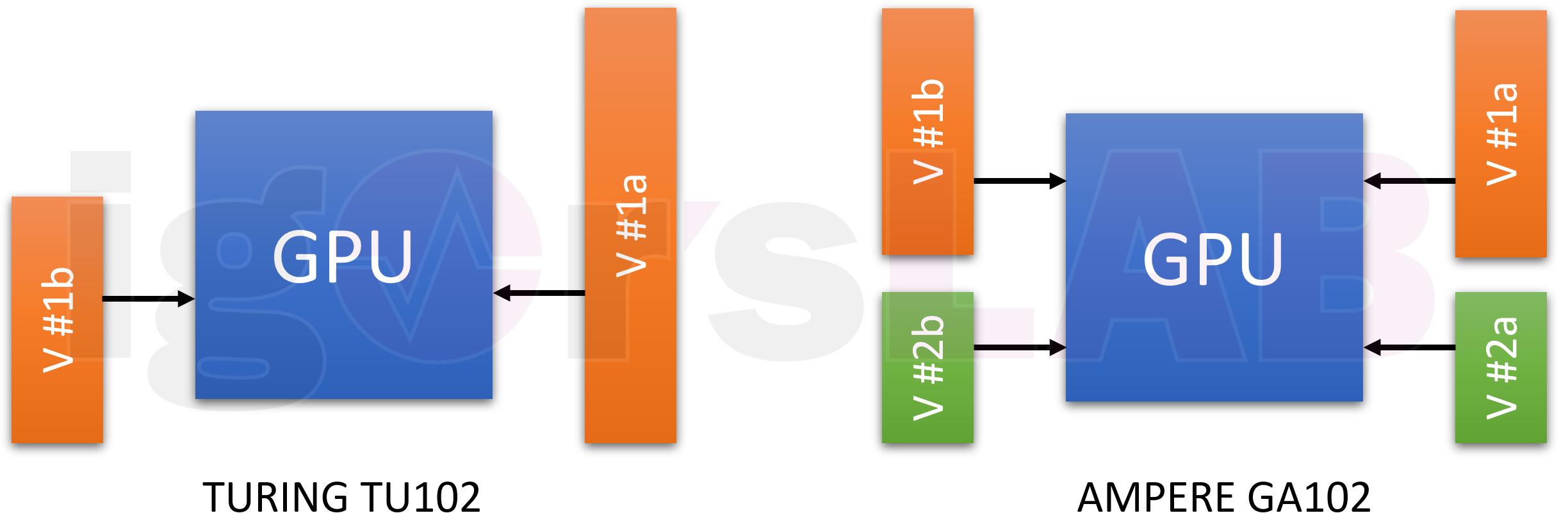
Wenn man das weiterrechnet, dann läge der Anteil der Shader nur noch bei maximal 160 bis 170 Watt, womit dann auch das Verhältnis zwischen Turing und Ampere wieder realistischer ausfallen würde. Bei den Notebooks setzt man ja beispielsweise auf Dynamic Boost, wo die Leistungsverteilung je nach Bedarf verschoben wird, um im thermischen und Power-Limit zu bleiben. Ein smartes Balancing zwischen den möglichen beiden Teilspannungen, wo die Tensor – und RT-Cores zumindest paritätischer gewichtet würden, wäre eigentlich nur logisch.
Das soll es für heute erst einmal gewesen sein, denn wir wollen ja auch nicht so sehr spekulieren. Nur ein bisschen. Aber wenigstens ein Körnchen Salz wird wohl wie immer dran sein, das dann auch ein wenig nach Wahrheit schmeckt. Hoffen wir es mal 🙂
Quellen: eigene
















Kommentieren