











Eine Forschungsstudie aus China hat enthüllt, dass der hauseigene KI-Verarbeitungschip “ACCEL” eine Leistung bieten soll, die 3000-mal schneller ist als die GPUs A100 & A800 von NVIDIA. Angesichts globaler Sanktionen arbeitet China daran, seine eigenen Lösungen zu verbessern, um das bisherige Tempo des industriellen Wachstums aufrechtzuerhalten. Die Tsinghua University in China hat eine neue Technik für KI-Berechnungen entwickelt und den ACCEL-Chip entworfen, der die Kraft der Photonik und Analogtechnologie nutzt, um eine beeindruckende Leistung zu erzielen. Die veröffentlichten Zahlen sind äußerst beeindruckend, aber natürlich mit der nötigen Vorsicht zu genießen.

Ohne einen Echtzeit-Benchmark kann man nicht behaupten, dass ein Chip der schnellste in seiner Branche ist. Daher hat man ACCEL in Experimenten gegen Fashion-MNIST, die 3-Klassen-ImageNet-Klassifikation und Zeitraffer-Videorekognitionsszenarien getestet, um die Leistungsfähigkeit des “Deep Learning”-Chips zu ermitteln. Dabei erreichte er Genauigkeiten von 85,5%, 82,0% und 92,6%, was zeigt, dass der Chip in verschiedenen Industriebereichen eingesetzt werden kann und nicht nur auf einen bestimmten Bereich beschränkt ist. Dies macht ACCEL besonders interessant und man darf gespannt sein, welche Zukunftsperspektiven der Chip noch bietet.
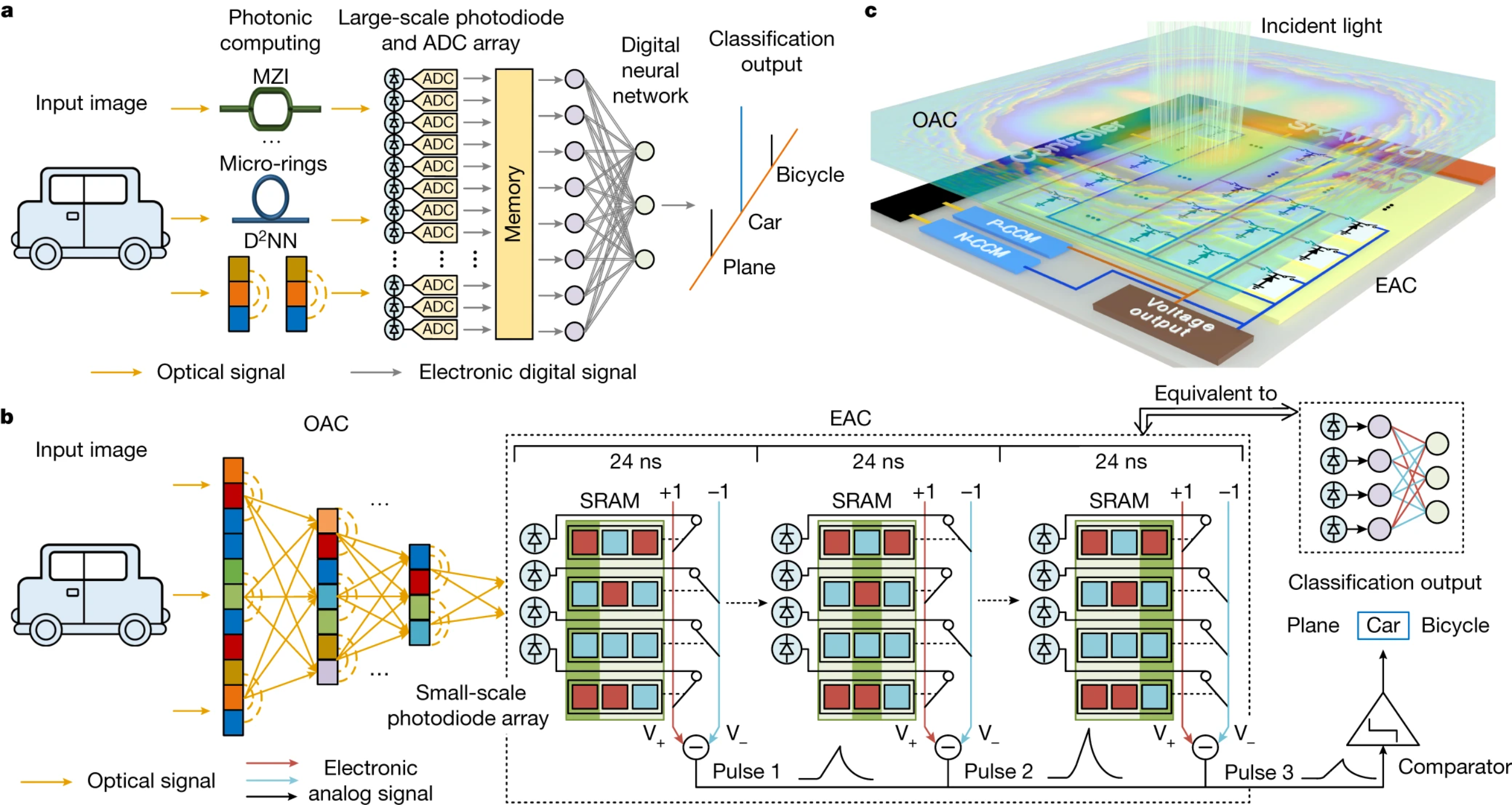
Dieser Chip kombiniert die Fähigkeiten der diffraktiven optischen analogen Berechnung (OAC) und der elektronischen analogen Berechnung (EAC) mit Skalierbarkeit, Nichtlinearität und Flexibilität. Um solche Effizienzwerte zu erreichen, nutzt der Chip eine Hybridarchitektur aus Optik und Elektronik, um große Mengen an Analog-Digital-Wandlungen (ADCs) bei umfangreichen Arbeitslasten zu reduzieren. Dadurch wird eine erheblich verbesserte Leistung erzielt. In einem veröffentlichten Forschungspapier wird der Mechanismus des Chips ausführlich behandelt.

For state-of-the-art GPU, we used NVIDIA A100, whose claimed computing speed reaches 156 TFLOPS for float32 (ref. 33). ACCEL with two-layer OAC (400 × 400 neurons in each OAC layer) and one-layer EAC (1,024 × 3 neurons) experimentally achieved a testing accuracy of 82.0% (horizontal dashed line in Fig. 6d,e). Because OAC computes in a passive way, ACCEL with two-layer OAC improves the accuracy over ACCEL with one-layer OAC at almost no increase in latency and energy consumption (Fig. 6d,e, purple dots). However, in a real-time vision task such as automatic driving on the road, we cannot capture multiple sequential images in advance for a GPU to make full use of its computing speed by processing multiple streams simultaneously48 (examples as dashed lines in Fig. 6d,e). To process sequential images in serial at the same accuracy, ACCEL experimentally achieved a computing latency of 72 ns per frame and an energy consumption of 4.38 nJ per frame, whereas NVIDIA A100 achieved a latency of 0.26 ms per frame and an energy consumption of 18.5 mJ per frame.
Die Auswirkungen von ACCEL und ähnlichen analogen KI-Chip-Entwicklungen auf die Branche sind derzeit schwer vorherzusagen, da die Einführung von auf Analogtechnologie basierenden KI-Beschleunigern noch in der Zukunft liegt. Obwohl die Leistungszahlen und Statistiken recht optimistisch sind, ist zu beachten, dass die “Implementierung” in der Branche keine einfache Aufgabe ist und Zeit, beträchtliche finanzielle Ressourcen und gründliche Forschungsarbeit erfordert. Dennoch kann niemand bestreiten, dass die Zukunft des Computings vielversprechend ist, und es ist nur eine Frage der Zeit, bis wir eine solche Leistung im Mainstream sehen.
Quelle: Tom’s Hardware

















7 Antworten
Kommentar
Lade neue Kommentare
Veteran
Urgestein
Veteran
Mitglied
Urgestein
Veteran
Alle Kommentare lesen unter igor´sLAB Community →