











A research study from China has revealed that its in-house AI processing chip “ACCEL” is said to offer performance that is 3000 times faster than NVIDIA’s A100 & A800 GPUs. In the face of global sanctions, China is working to improve its own solutions to maintain the current pace of industrial growth. Tsinghua University in China has developed a new technique for AI computation and designed the ACCEL chip, which harnesses the power of photonics and analog technology to achieve impressive performance. The published figures are extremely impressive, but should of course be taken with a grain of salt.

Without a real-time benchmark, you can’t claim that a chip is the fastest in its industry. Therefore, ACCEL was tested in experiments against Fashion-MNIST, the 3-class ImageNet classification and time-lapse video recognition scenarios to determine the performance of the deep learning chip. It achieved accuracies of 85.5%, 82.0% and 92.6%, which shows that the chip can be used in various industries and is not limited to a specific domain. This makes ACCEL particularly interesting and it will be interesting to see what future prospects the chip offers.
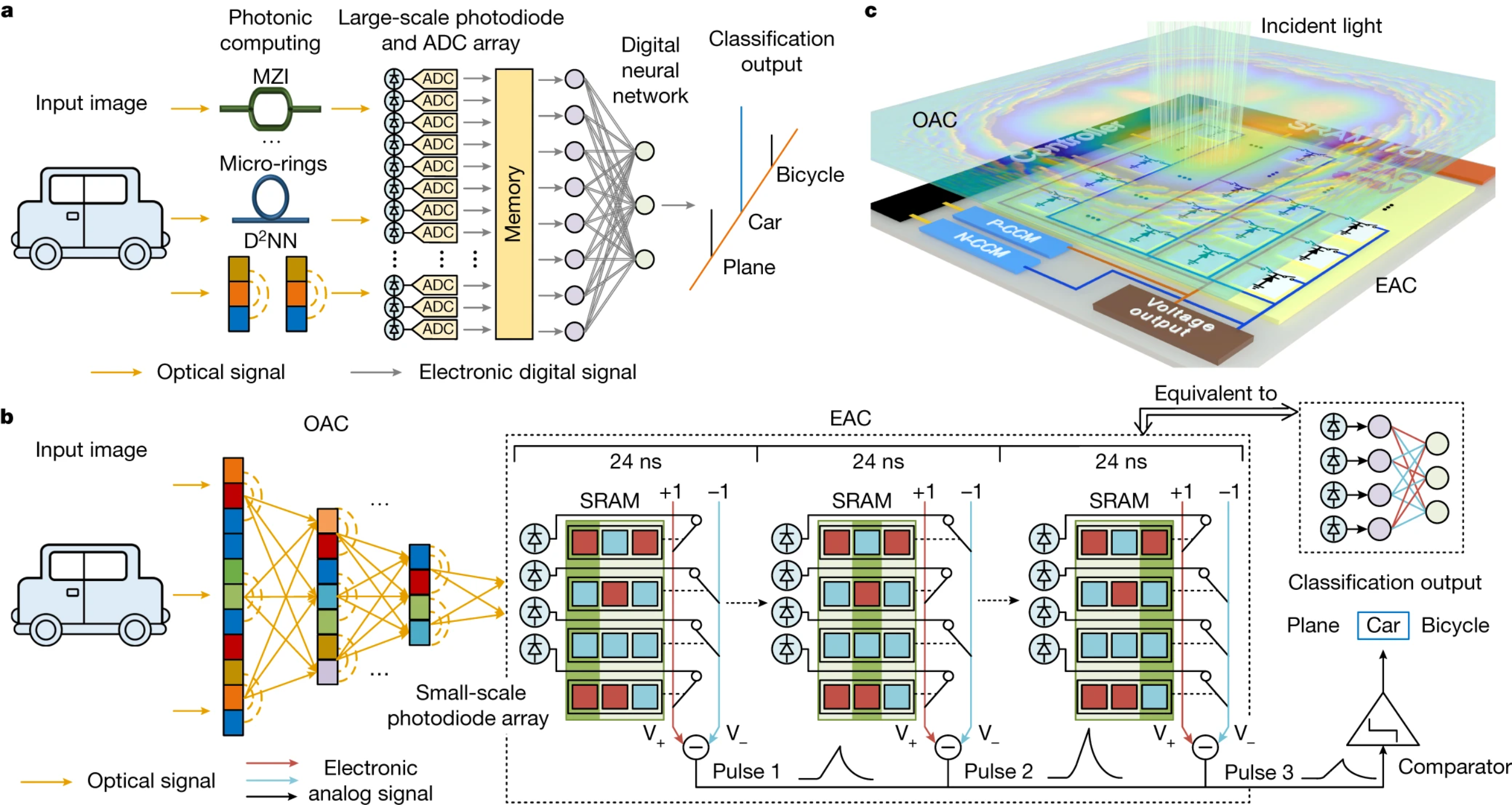
This chip combines the capabilities of diffractive optical analog computation (OAC) and electronic analog computation (EAC) with scalability, nonlinearity and flexibility. To achieve such efficiencies, the chip uses a hybrid architecture of optics and electronics to reduce large amounts of analog-to-digital conversions (ADCs) in large workloads. This results in significantly improved performance. A published research paper discusses the chip’s mechanism in detail.

For state-of-the-art GPU, we used NVIDIA A100, whose claimed computing speed reaches 156 TFLOPS for float32 (ref.33). ACCEL with two-layer OAC (400 × 400 neurons in each OAC layer) and one-layer EAC (1,024 × 3 neurons) experimentally achieved a testing accuracy of 82.0% (horizontal dashed line in Fig. 6d,e). Because OAC computes in a passive way, ACCEL with two-layer OAC improves the accuracy over ACCEL with one-layer OAC at almost no increase in latency and energy consumption (Fig. 6d ,e, purple dots). However, in a real-time vision task such as automatic driving on the road, we cannot capture multiple sequential images in advance for a GPU to make full use of its computing speed by processing multiple streams simultaneously48 (examples as dashed lines in Fig. 6d,e). To process sequential images in serial at the same accuracy, ACCEL experimentally achieved a computing latency of 72 ns per frame and an energy consumption of 4.38 nJ per frame, whereas NVIDIA A100 achieved a latency of 0.26 ms per frame and an energy consumption of 18.5 mJ per frame.
The impact of ACCEL and similar analog AI chip developments on the industry is currently difficult to predict, as the introduction of AI accelerators based on analog technology is still in the future. Although the performance figures and statistics are quite optimistic, it should be noted that “implementation” in the industry is not an easy task and requires time, significant financial resources and thorough research. Nevertheless, no one can deny that the future of computing is bright, and it is only a matter of time before we see such performance in the mainstream.
Source: Tom’s Hardware


















7 Antworten
Kommentar
Lade neue Kommentare
Veteran
Urgestein
Veteran
Mitglied
Urgestein
Veteran
Alle Kommentare lesen unter igor´sLAB Community →