











Ich hatte ja in einigen Artikel bereits über NVIDIAs neue Generation der Ampere-Karten berichtet und mir auch das Feedback dazu durchgelesen. Interessant waren dort vor allem die Hochrechnungen der Anzahl möglicher CUDA Cores, an denen man alle Vergleiche zu Turing in Bezug auf Performance und Effizienz sowie als Folge dessen auch mit der möglichen Leistungsaufnahme festmacht. Oder besser: man glaubt, es daran festmachen zu können. Nur hat die alleinige Skalierung der CUDA Cores als Maßstab einer Schätzung einen dicken Pferdefuß, den ich gern erklären möchte.

Wichtige Vorbemerkung
Der heutige Artikel ist ein reines Gedankenspiel, basierend auf vielen Tests mit der Quadro RTX 6000, 5000 und 4000 im Workstationbereich und vielen aufgetauchten Flaschenhälsen bei der gemeinsamen Nutzung von den CUDA-Cores über die RT- bis hin zu den Tensor-Cores. Die Messungen und Vergleichsdaten lassen durchaus auf ein gewisses Dilemma schließen, das aus NVIDIAs selbst auferlegten festen Power Limit resultiert und der Art, wie Boost mit seinem Auf und Ab letztendlich auch indirekt die Tensor- und RT-Leistung beeinflusst. Paritätisch und ausgeglichen ist das nämlich nicht immer.
Worauf ich hinaus will und warum wir vielleicht endlich einen wesentlich effizienteren Lösungsansatz für die Spannungsversorgung sehen werden, das könnte Ihr im nachfolgenden Artikel lesen, der kein Leak ist, sich jedoch an vielen Tatsachen orientiert, die man eigentlich nur erkennen, einsammeln und auch zusammenfügen muss. Trotzdem möchte ich explizit voranstellen, dass es lediglich meine Sicht der Dinge ist und dass alles am Ende doch etwas anders kommen könnte. Wie auch immer
Gedankenansatz
Worauf ich hinaus will? Vielen dürfte durchaus unbewusst aufgefallen sein, dass Nvidia vor allem das Thema AI und insbesondere auch lokales DLSS (Deep Learning Super Sampling) in letzter Zeit immer weiter (und fast schon aggressiv) in den Fokus rückt. Und das nicht nur für die Spieler, sondern auf breiter Front auch im Produktivbereich. Das hier neben den RT-Cores vor allem die Tensor-Cores eine nicht unerhebliche Rolle spielen, ist sicher auch kein Geheimnis. Was mich jedoch verblüfft ist der Umstand, dass sie bei allen Leaks und Schätzungen alles nur einzig und allein um die klassischen Shader dreht und man das, was RTX eigentlich ausmacht, schlichtweg beiseitelässt.
Für “Big Navi” darf man seitens AMD durchaus so Einiges an Performance erwarten und sicher nicht ganz unbegründet kolportiert man ja gerade, dass der GA102 bereits am Launchtag als Vollausbau genau deswegen mit von der Partie sein wird. Die RT-Leistung der AMD-Karte kann man schlecht abschätzen, aber auch hier wird wohl so Manches machbar sein. Was “Big Navi” jedoch ganz offensichtlich noch fehlt, sind die spezialisierten Tensor-Cores, die für die AI und mittlerweile auch unzählige Anwendungsfälle in Produktiv-Programmen eine nicht kleine Rolle spielen. Und genau da wird es interessant, denn warum sollte Nvidia das einzige wirklich noch exklusive Feld gegenüber dem direkten Mitbewerber sträflich vernachlässigen? Man hat mit Raytracing bereits seinerzeit vorgelegt und ich müsste mich schon stark irren, wenn man jetzt nicht den Fokus verstärkt auf die Tensor-Leistung richtet.
Würde man jedoch den Anteil der Tensor-Cores am Energieversorgungskonzept signifikant vergrößern, stünde man plötzlich vor einem richtigen Problem. Erinnert Ihr Euch noch an meinen Test (“NVIDIA RTX Voice im Test mit GeForce GTX und GeForce RTX: Tensor-Kerne gefangen im TBP-Korsett, nur die GTX nutzt CUDA”) zu RTX Voice und den Vergleich zwischen CUDA- und Tensor-Cores? Wer immer schon einmal nach einem Test gesucht hat, wie man die Last bzw. die Leistungsaufnahme der Tensor-Cores ermitteln kann: im Idle geht das sogar mit RTX Voice, weil dadurch nämlich keine Grafik-Last entsteht. Einen ähnlichen Effekt kann man übrigens immer dann feststellen, wenn z.B. bei diversen Filtern die Bildbearbeitung oder das Videoschnittprogramm diese spezialisierten Kerne nutzt. Leistungsaufnahme hoch, GPU-Last angeblich bei null.
Der Flaschenhals der Spannungsversorgung bei Turing
Betrachten wir jetzt einmal Turings Spannungsversorgungs-Schema für die erste RTX-Generation. Um das Folgende zu verstehen, muss ich zunächst auf wichtige Basics zurückkommen. Denn wir müssen uns jetzt über den Begriff Total Graphics Power (TGP) klar werden. Das ist alles ja noch noch recht einfach an allen Zuführungen nachzumessen, aber was NVIDIA und AMD komplett unterscheidet, ist die Kontroll- und Regelwut bei NVIDIAs aktuellen Grafikkarten, bei denen das jeweilige Power Target (Default Power Limit, Werksvorgabe) und das maximale Power Limit (Max Power Limit, Absolutwert) in der Firmware fest hinterlegt sind.
Wir sehen für die GeForce RTX 2080 Ti z.B. 13 Spannungswandlerkreise für VDDC, die sich auf 8 Phasen verteilen. Dazu kommen dann noch 3 Phasen für den Speicher (MVDD) sowie jede Menge kleiner Teilspannungen, die als Posten jedoch nicht groß ins Gewicht fallen.

Im Gegensatz zu AMD überwacht Nvidia alle 12-Volt-Eingänge penibel mittels eines speziellen Monitoring-Chips, der sowohl die Spannung hinter und vor dem Shunt (sehr niederohmiger Widerstand) misst und somit auch den Spannungsabfall längs über diesem Shunt auswertet (daraus errechnet man den Stromfluss). Da in jeder 12-Volt-Zuleitung solch ein Shunt sitzt, kann somit die exakte Leistungsaufnahme des Boards bei 12 Volt gemessen und auch für die interne Begrenzung der Leistungsaufnahme zugrunde gelegt werden. Wir sehen links einen Shunt mit Längsspule zur Eingangsglättung und rechts einen NCP45491 von On Semi fürs Monitoring der Spannungen und Ströme.


Genau dieser hier ermittelte Wert wird auch in der Praxis nie überschritten (werden können), dafür sorgt die sehr aufmerksame und schnell regelnde Firmware. Was viele nämlich nicht bedenken: in diese Berechnung fließen auch Lüfter, RGB-Flutlicht, Mikrocontroller und Displays mit ein. Je mehr an “Peripherie” mitversorgt werden muss, umso weniger Leistung steht dann der GPU zur Verfügung! Hätte NVIDIA die ca. 35 bis 45 Watt, die man z.B. bei der RTX 2080 Ti für die maximale Belastung der Tensor- und RT-Kerne veranschlagen könnte, nicht so restriktiv mit im Monitoring eingepreist, könnten die Karten bei Volllast auf CUDA-, Tensor- und RT-Kernen natürlich deutlicher profitieren!
Leider erfolgt die Spannungsversorgung der beiden weiteren Rechenwerke über eine gemeinsame Leitung (VDDC) zusammen mit den CUDA-Cores und liegt auch hinter den überwachten Zuführungen. Und die Versorgungsspannung schwankt zudem und unterliegt der Regel-Wut von Boost. Womit sich der Kreis beim Gedankenspiel endlich wieder schließt und auch der Letzte begreift, dass hier eine neue Lösung eigentlich mehr als überfällig ist.
Was wäre wenn? Wie man die kolportierten bis zu 350 Watt erklären und aufteilen könnte
Bisher versorgt man die Turing-GPU neben den anderen, in der Summe eher geringer zu wichtenden Teilspannungen, mit einer einzigen Spannung für alles, nämlich VDDC. Nun hatte ich ja bereits in älteren Veröffentlichungen erwähnt, dass man für die große SKU10 (ich vermeide absichtlich einen Namen, der sich mit Sicherheit eh noch ändern wird) eine TGP von bis zu 350 Watt und für die SKU20 und SKU30 eine TGP von 320 Watt. Das ergäbe nach meiner ersten Schätzung ca. 230 Watt für den gesamten Chip einschließlich der CUDA-, RT- und Tensor-Cores.
| SKU 10 | Estimated Power Consumption / Losses |
| Total Graphics Power TGP | 350 Watts |
| 24 GB GDDR6X Memory (2.5 Watts per Module) | -60 Watts |
| MOSFET, Inductor, Caps GPU Voltage | -26 Watts |
| MOSFET, Inductor, Caps Framebuffer Voltage | -6 Watts |
| MOSFET, Inductor, Caps PCIExpress Voltage | -2 Watts |
| Other Voltages, Input Section (AUX) | -4 Watts |
| Fans, Other Power | -7 Watts |
| PCB Losses | -15 Watts |
| GPU Power | approx. 230 Watts |
Ich bin mir ziemlich sicher, dass Nvidia die Tensor- und sicher auch die RT-Performance deutlich erhöhen wird. Trotz des feineren Nodes sollten hier damit aber auch die Leistungsaufnahmewerte für diese Rechenwerke (leicht) steigen, wenn man einen signifikanten Unterschied sehen möchte. Das ist über eine gemeinsame Spannungsversorgung aller drei Rechenwerke eigentlich nicht mehr sinnvoll lösbar. Und selbst wenn, müsste man ein deutlich intelligenteres Balancing hinbekommen.
Ich denke mal, 60 bis 70 Watt wird man für die zusätzlichen Rechenwerke im GA102-Vollausbau mindestens ansetzen können und wenn man das Ganze von den CUDA-Cores entkoppelt, dann kann auch dort die Versorgung ein wenig einfacher gestaltet werden. Ich hatte in einer früheren Berechnung mit 16 Spannungswandler-Kreisen für die reine GPU-Power bei 230 Watt gerechnet. Dazu kämen für den Speicher, zumindest bei 24-GB-Vollausbau, noch einmal bis zu 4 Regelkreise hinzu.
Auch jetzt kann man natürlich Taschenrechner und Datenblatt nutzen, um hier eine Schätzung vorzunehmen, wie die mögliche Aufteilung der GPU-Spannungen aussehen könnte. Zweimal 8 Regelkreise wären reichlich sinnlos, weil sie dem Leistungsanteil nicht entsprechen würden. Der größte, zu normalen Preisen erhältliche PWM-Controller, generiert derzeit maximal 10 Phasen. Mit etwas Phantasie (und Glück beim Raten), könnte man die Versorgung der Shader mit bis 10 Phasen ansetzen, wobei dann je eine Phase auch nur einen Power Stage ansprechen würde. Die restlichen bis zu 6 Phasen entfielen dann auf eine weitere Teilspannung mit der gleichen Power-Stage-Aufteilung.
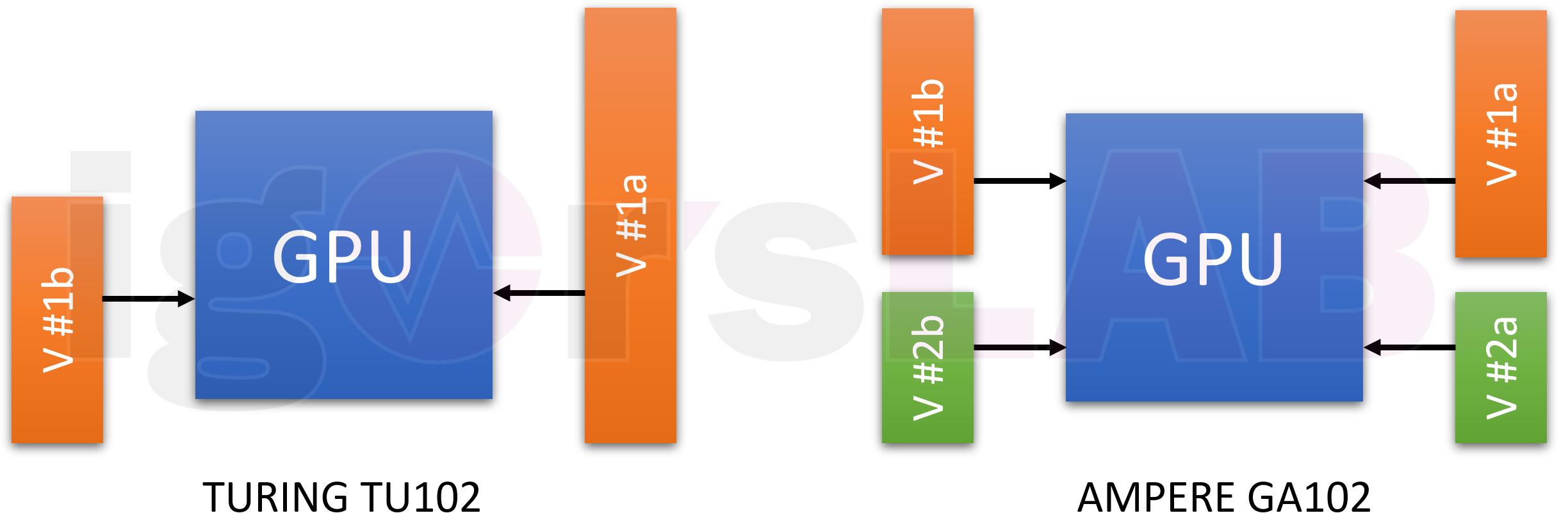
Wenn man das weiterrechnet, dann läge der Anteil der Shader nur noch bei maximal 160 bis 170 Watt, womit dann auch das Verhältnis zwischen Turing und Ampere wieder realistischer ausfallen würde. Bei den Notebooks setzt man ja beispielsweise auf Dynamic Boost, wo die Leistungsverteilung je nach Bedarf verschoben wird, um im thermischen und Power-Limit zu bleiben. Ein smartes Balancing zwischen den möglichen beiden Teilspannungen, wo die Tensor – und RT-Cores zumindest paritätischer gewichtet würden, wäre eigentlich nur logisch.
Wie bereits geschrieben, das sind reine Gedankenspiele. Aber es wäre schon smart, wenn der tatsächliche Lösungsansatz so oder wenigstens ähnlich aussehen würden.



















Kommentieren