











Ich habe das erste Board für Leistungsmessungen lange vor der Veröffentlichung von Nvidias PCAT gebaut. Nvidia hatte etwa ein Jahr vor der Veröffentlichung von PCAT auch ein Powenetics-System gekauft, um es zu studieren. Und man hat mich dort irgendwie aus den Augen verloren, also schätze ich, dass die Dinge für sie nicht wie erwartet gelaufen sind oder man meinte, es vielleicht auch anders bzw. besser zu können. Wer weiß das schon?

Ich hatte schon lange vor, ein neues Powenetics-System zu bauen, das noch vielseitiger, einfacher einzurichten und mit einer viel schnelleren Abfragerate ausgestattet sein würde. Die Produktionskosten standen an letzter Stelle auf meiner Liste, da dieses System nicht für den Durchschnittsnutzer, sondern für sehr enthusiastische Nutzer oder Rezensenten gedacht ist, also ging ich am Ende, technisch gesehen, all-in.
Die ersten Entwürfe wurden geliefert, und wir begannen langsam mit dem Prozess. Die verrückte Zeit, die wir durchlebten, schränkte meine IC-Optionen ein, und wir fanden am Ende nur zwei ICs, um überhaupt ein paar Boards zu bauen. Trotz aller Widrigkeiten und Hindernisse erreichten wir die gewünschte Datenabfragerate von 1000 Samples pro Sekunde von ALLEN Sensoren, sowohl für Spannung als auch für Strom. Und Powenetics v2 hat 12 dieser Sensoren, die ATX12V und ATX12VO Netzteile unterstützen! Es gibt auch zwei 12+4 Pin PCIe Anschlüsse auf dem Board für die kommenden GPUs.

Nun zum technischen Teil: Ich wollte den High-End-IC INA228AIDGSR verwenden, aber es war nicht auf Lager! Also verwenden die ersten beiden Boards den PAC195X, der einen 16-Bit-ADC hat, im Gegensatz zum oben erwähnten 20-Bit-ADC. Das Gehirn der Karte ist eine 32-Bit-MCU, PIC32MZ, die bis zu 48 Eingänge unterstützt!
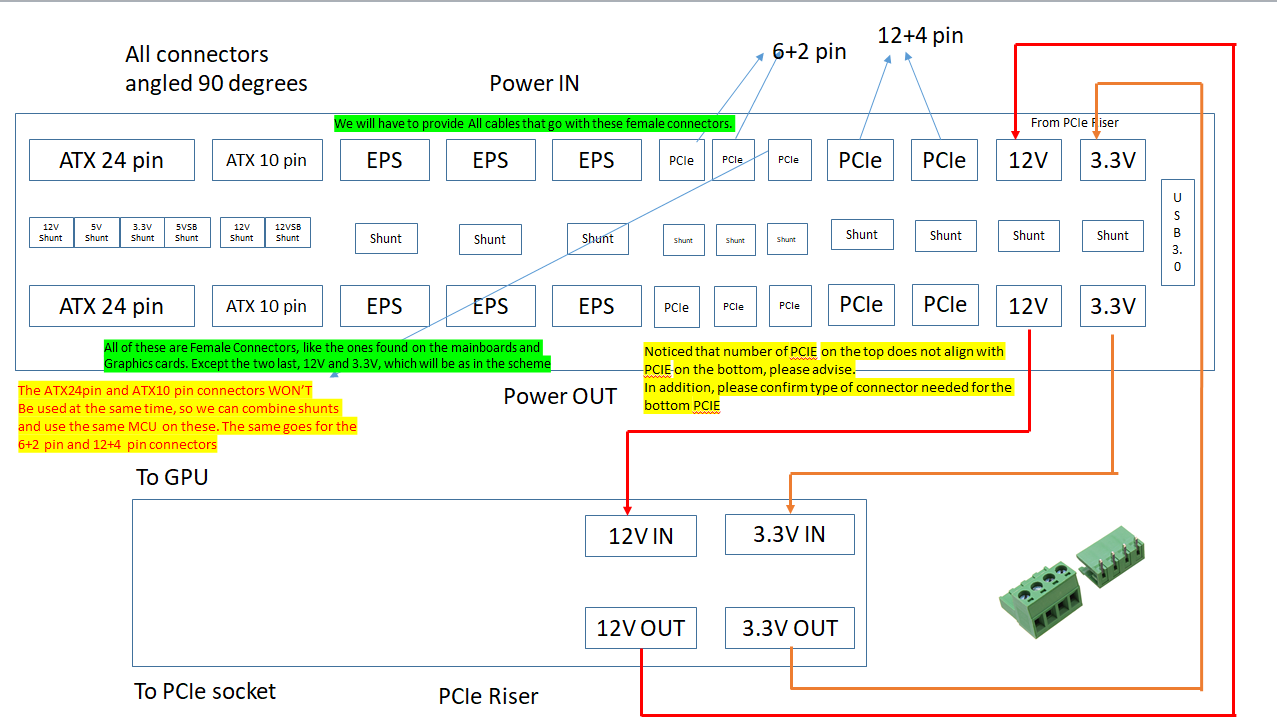
Das Wichtigste ist, dass das PMD auch von einem PCI-Extender begleitet wird, so dass es die Leistung, die der PCIe-Steckplatz liefert, mühelos messen kann. Beim ursprünglichen Powenetics mussten wir einige einzigartige und sehr teure PCIe-Erweiterungskarten kaufen, und ich wollte nicht, dass dies beim neuen System der Fall ist.

Wie ich bereits erwähnt habe, waren mir die Produktionskosten egal und ich wollte das Beste, was ich bauen konnte. Man muss also immer beachten, dass es sich um ein Laborgerät und nicht um ein “Spielzeug” handelt. In Anbetracht der aktuellen Situation und sobald wir genügend Teile finden, um mehr zu produzieren, wird der Preis des Powenetics v2 ca, 500 Euro/Dollar betragen, ohne Mehrwertsteuer und Versand. Für diesen Betrag erhält mane das gesamte System, einschließlich aller Kabel, des PCIe-Extenders und der Software, und wir sind bereits in Gesprächen mit dem Gründer von CapFrameX, um diese fantastische App unterstützen zu lassen.
Wir wissen nicht, wann wir weitere Teile finden werden, und wir müssen das System durch unsere Evaluierungsboards optimieren und gründlich prüfen. Aber sobald wir so weit sind, werden wir damit beginnen, sie in Stückzahlen zu bauen, und wir werden das Problem der genauen Leistungsmessung in Systemen auf elegante Art und Weise lösen!
Quelle: hwbusters (Gastbeitrag von Aris)
















21 Antworten
Kommentar
Lade neue Kommentare
Veteran
1
Veteran
Neuling
Veteran
Neuling
Veteran
1
Veteran
1
Veteran
1
Veteran
1
1
Veteran
1
Urgestein
Veteran
Alle Kommentare lesen unter igor´sLAB Community →