











Gefühlte Berge an Salami-Scheibchen haben wir seit Dezember und AMDs Tech Summit 2016 im kalifornischen Sonoma schon veröffentlicht – und heute kommt mit Vega das vorerst letzte davon, denn für AMD geht es am Ende ja wirklich um die Wurst. Genauso sieht dann auch der eng gesteckte Fahrplan für 2017 aus: Vollgepackt und hektisch.
 Im ersten Quartal erwarten wir Ryzen für den Desktop (wir schrieben bereits darüber), Freesync 2 (wir berichteten ebenfalls) sowie im Verlaufe des Jahres noch diverse Server- und Notebook-Lösungen.
Im ersten Quartal erwarten wir Ryzen für den Desktop (wir schrieben bereits darüber), Freesync 2 (wir berichteten ebenfalls) sowie im Verlaufe des Jahres noch diverse Server- und Notebook-Lösungen.
Machine Learning wird ebenfalls ein heißes Thema für AMD – und dann natürlich Vega, die heiß erwartete dritte Generation von AMDs GCN-Architektur.
Fertige Produkte mit diesen Chips werden wir wohl irgendwann im ersten Halbjahr, jedoch spätestens bis Ende Juni erwarten dürfen. Nach der Messe ist vor der Messe – und vor der Computex sollte es dann doch passiert sein.
Bis dahin müssen wir leider erneut das ausquetschen, was uns AMD an Informationen vorab überlassen hat, auch wenn es jetzt nicht überbordend viel ist und noch keinerlei praxisbezogenen Tests beinhaltet. Sei es drum: Ein wenig (Theorie) hat AMD dann ja doch noch preisgegeben und man versprach uns zudem weitere Häppchen kurz vor dem wirklichen Start von Vega.

Raja Koduri, seines Zeichens Senior Vice President and Chief Architect der Radeon Technologies Group, stand bei AMDs Tech Summit wie ein aufgeregtes Kind auf der Bühne und zeigte uns stolz wie Bolle ein erstes Chip-Muster von Vega, in das seinerseits über 200 Änderungen und Verbesserungen bei der Umgestaltung der Architektur geflossen sein sollen.

Auch wenn es am Ende wohl auf eine neue GCN-Generation hinausläuft: AMD wurde nicht müde zu betonen, dass es eine komplett neu geschaffene Lösung sein wird. Das könnte man sogar glauben, denn es fließen ja nicht nur die Vorteile ein, die man sich von DirectX 12 verspricht, sondern auch das, was Nvidia bisher unter DirectX 11 in die Karten spielte und wo man durchaus einen gewissen Nachholbedarf AMDs sah und sieht, wenn es um das konsequente Ausnutzen der Ressourcen geht.

Um uns einen ersten Vorgeschmack zu geben, beschränkte sich Koduri jedoch auf das aus seiner Sicht wohl Wichtigste und grenzte die Häppchenauswahl auf ganze vier Geschmacksmuster ein, die es aber als technische Kalorienbömbchen durchaus in sich haben könnten. Diese vom Umfang her eher überschaubare Platte der vier Köstlichkeiten reichen wir natürlich gern an unsere Leser weiter.
1. HBM2 als skalierbare Speicherarchitektur
Als ersten Anhaltspunkt für Vegas Architekturänderung bezog sich Koduri auf den zur Verfügung stehenden Speicher und die gesamte, dazugehörige Infrastruktur.
Dazu holte er erst einmal kräftig aus, indem er uns zeigte, wie sich der Speicherbedarf der Spiele in den letzten Jahren auf dem Desktop-PC entwickelte und wie sich die Workloads bei den professionellen Anwendungen bis in den Petabyte-Bereich und beim Machine Learning und Training sogar bis in den Exabyte-Bereich verschoben haben bzw. verschieben werden. Dazu kartographierte er auch das Verhältnis zwischen Performance-Steigerung und entsprechendem Speicherbedarf.
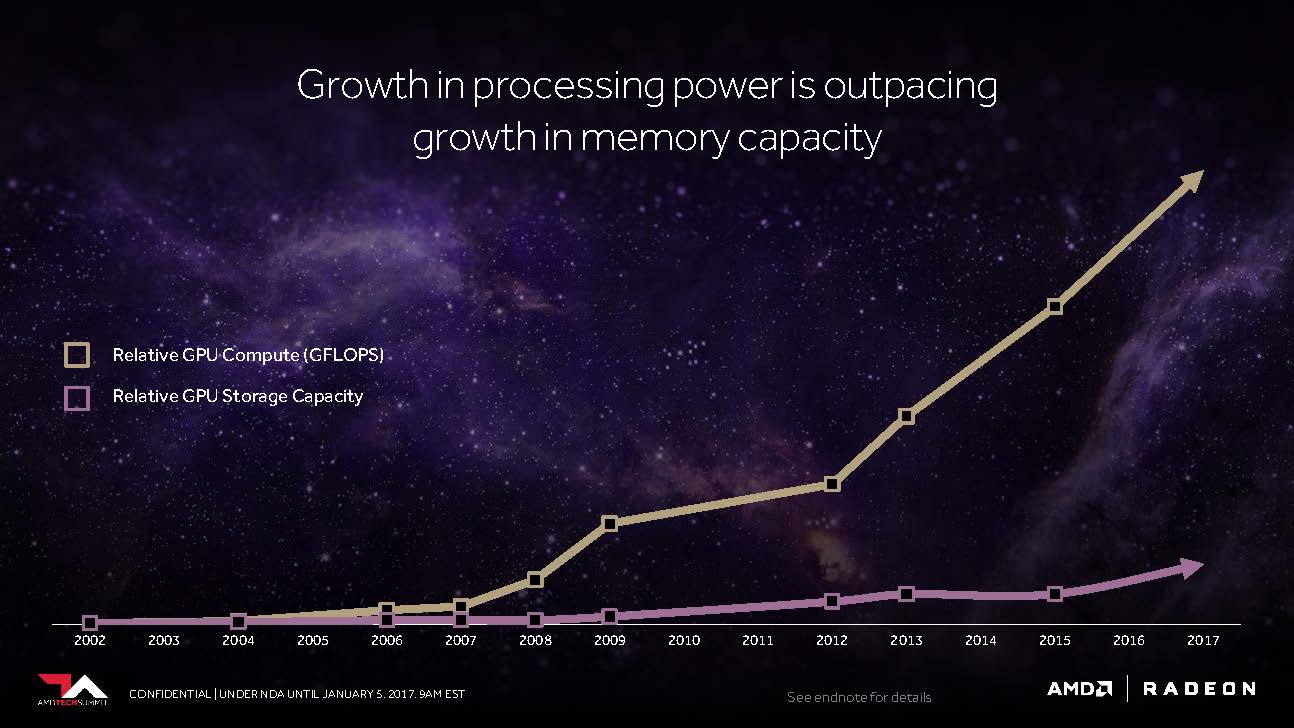
AMD und Nvidia arbeiten beide (natürlich jeder für sich) an Möglichkeiten, um den Host-Prozessor-Overhead reduzieren sowie den Durchsatz zu maximieren und auf diese Weise Engpässe beim Zugriff auf die GPU zu minimieren – insbesondere diejenigen, die angesichts der umfangreichen Datenmengen immer wieder auftreten (können).
Es kommt somit darauf an, noch mehr Speicherkapazitäten noch näher an die GPU zu bringen und dabei die Kosten nicht explodieren zu lassen. Wie es scheint, hat AMD Vega mit einer deutlich flexibleren Speicherhierarchie einen großen Schritt näher an dieses wichtige Ziel gebracht.
Dass Vega HBM2 nutzen kann und wird, ist natürlich mittlerweile kein Geheimnis mehr. Aber AMD hat hier zumindest noch einmal explizit bestätigt, was man auf den ganzen Roadmaps des letzten Jahres bereits sehen bzw. vermuten konnte. Aber man wird konkreter und nennt diese Ansammlung von On-Package-Speicher, den man früher ziemlich unspektakulär auch schon als Frame-Buffer bezeichnete, nunmehr glanzvoll “High Bandwidth Cache”. Nettes Schlagwort – doch was stellt sich AMD nun darunter eigentlich konkret vor?

Folgt man hierzu den Worten von Joe Macri, Corporate Fellow and Product CTO, hatte man ja bei HBM die Vision, den leistungsfähigsten Speicher so nah wie nur möglich an die GPU zu bringen. Das schließt nach seinen Worten auch den Arbeits- und Datenspeicher des gesamten Systems ein – womit er dem oben genannten neuen Zugpferd “High Bandwidth Cache” etwas mehr Futter gab.
Und auch wenn dies deutlich langsamere Technologien in diese Infrastruktur mit einschließt, wollen wir HBM2 weiter als das sehen, was es in Wirklichkeit ist: Ein bedeutender Schritt nach vorn.
Eine bis zu achtfache Erhöhung der Kapazität eines jeden Stapels im direkten Vergleich zur ersten Generation sollte auch diverse Enthusiasten, die noch an der Zukunftsfähigkeit der Radeon R9 Fury X gezweifelt haben, endgültig ruhigstellen können – zumal auch die Verdopplung der Bandbreite pro Pin den maximal möglichen Durchsatz des Ganzen deutlich vergrößern hilft.
Man kann es auch so sehen: Würde AMD die gleichen 4-Hi-Stacks mit auf 700 MHz getaktetem HBM2-Speicher nutzen, wie es Nvidia auf den Tesla-P100-Beschleunigern vorgemacht hat, dann hätte man mit Vega dann beispielsweise eine 16-GByte-Karte mit satten 720 GBit/s, wobei noch genügend Luft für sowohl noch höhere Speicherkapazität als auch Bandbreite wäre.
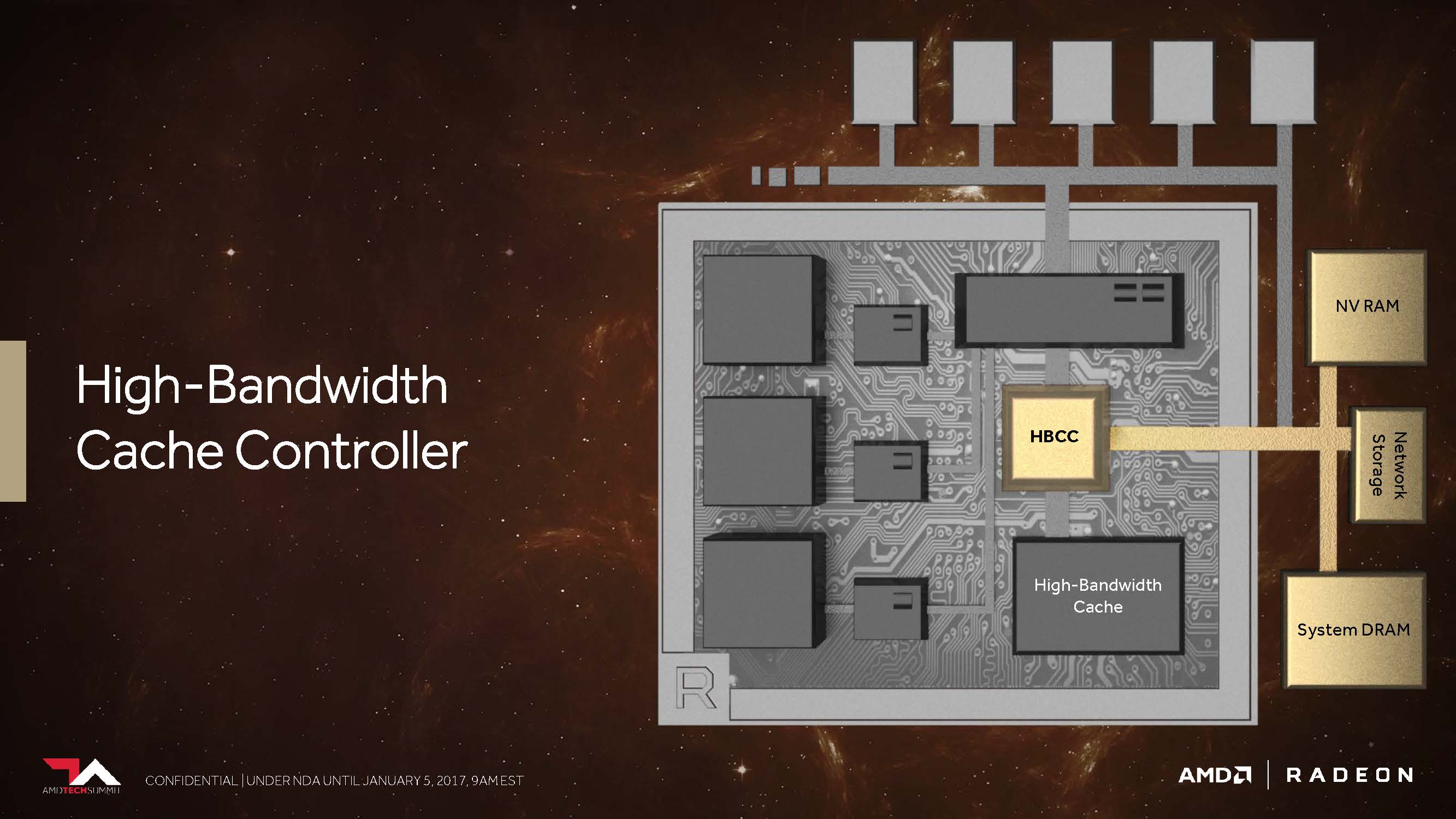
Wir denken, dass dies die größten Auswirkungen auf das Gaming und die Spieler selbst haben dürfte, sofern es sich auf das eigentliche Speichersubsystem bezieht. Aber das allein ist ja bei weitem noch nicht alles: AMD gibt dem neuen “High Bandwidth Cache”-Controller (HBCC), der mehr als der bisherige Speicher-Controller leisten muss, immerhin virtuell adressierbare 512 Terabyte für extrem große Datenmengen mit auf den Weg.
Damit schließt sich der Kreis zu Raja Koduris Einführung wieder und auch die Schnittmengen zu Radeon Instinct – worüber wir bereits im Dezember 2016 berichteten – werden deutlich klarer. Doch es blieben damals schon wichtige Fragen offen, wie die Vega-Architektur in der Lage sein wird, diese breiter angelegte Speicherhierarchie auch nutzen zu können.
Scott Wasson, Senior Product Marketing Manager bei AMD, verschaffte uns dann wenig Klarheit zu diesem Thema, indem er einige der Verwendungsmöglichkeiten des “High Bandwidth Cache”-Controllers erklärte.
Laut Wasson ist Vega dank HBCC in der Lage, mittels verschiedener programmierbarer Techniken Speicherseiten noch feiner abgestuft zu bewegen. So kann eine erhaltene Datenanforderung über den DMA-Transfer asynchron realisiert werden, während die GPU bereits zu einem anderen Thread gewechselt ist, um dort unterbrechungsfrei weiterarbeiten zu können.
Damit erhält der Controller die Daten faktisch “on-demand”, er kann sie aber auch vorausschauend zurückliefern. Dazu kommt, dass im HBM abgelegte Informationen im Systemspeicher wie ein zusätzlicher Cache einfach repliziert werden können oder aber der HBCC – was noch deutlich wichtiger scheint – mit einer einzigen Instanz auskommt, um Platz sparen und den Overhead reduzieren zu können.
2. Neue programmierbare Geometrie-Pipeline
Erinnern wir uns kurz zurück: Die erste Hawaii-GPU auf der Radeon R9 290 X brachte seinerzeit einige durchaus bemerkenswerten Verbesserungen im Vergleich zur Tahiti-GPU auf der Radeon HD 7970 mit. Eine davon betraf ein verbessertes Frontend mit nunmehr vier statt zwei Geometrie-Einheiten, von denen jede einzelne wiederum jeweils einen Geometry-Assembler, einen Vertex-Assembler und eine Tessellation-Einheit besaß.
Die darauffolgende Fiji-GPU als Radeon R9 Fury X setzte dann zwar erneut auf diese bereits von Hawaii bekannte Konfiguration, brachte aber dafür einige andere Neuerungen – beispielsweise eine deutlich gesteigerte Tessellation-Performance – mit. Aktuell nutzt die Ellesmere-GPU (Radeon RX 480) eine neue Handvoll Techniken, um aus der gleichen Konstellation mit den vier Geometrieeinheiten durch diverse Filteralgorithmen bzw. das Verwerfen unnötiger Polygone einen Leistungsvorteil herauszuarbeiten.
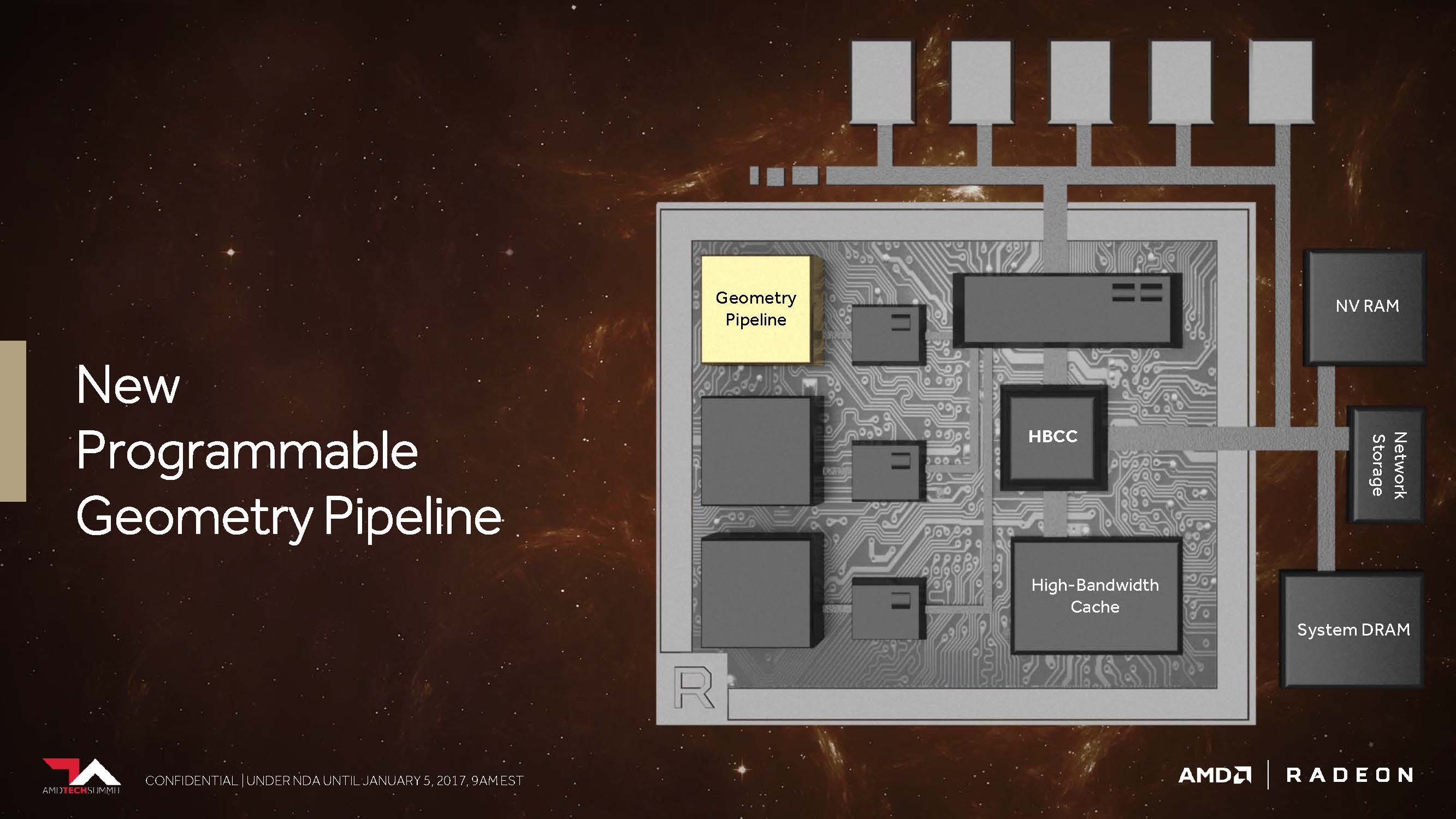
AMDs Folien sagen aus, dass Vega nunmehr in der Lage sein soll, in der Spitze immerhin bis 11 statt der maximal vier Polygone per Taktzyklus abarbeiten zu können, was dem bis zu 2,75-fachen entspricht. Dies ist die Folge dessen, was AMD als “New Primitive Shader Stage” in die Geometrie-Pipeline eingefügt hat. Anstelle der in der Hardware fest verankerten, dadurch jedoch unflexiblen Funktionen nutzt man jetzt ein flexibel ausgelegtes Shader-Array für die Verarbeitung der anfallenden Polygone.
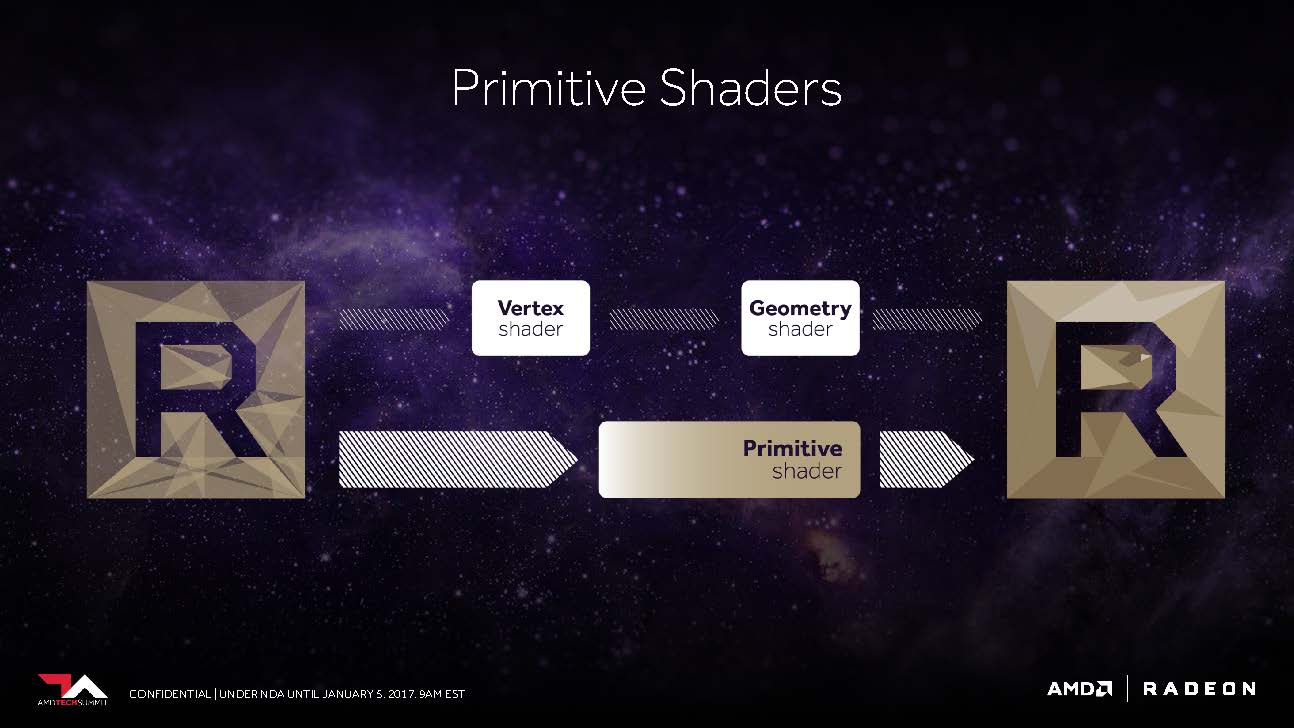
Mike Mantor, AMD Corporate Fellow, vergleicht dies mit der Funktionalität eines Compute-Shaders für die Verarbeitung der Geometrieaufgaben – leicht und programmierbar sowie mit der Fähigkeit ausgestattet, nicht benötigte Polygone mit einer hohen Rate auch verwerfen zu können.
AMDs Wasson erklärte uns weiter, dass diese Shader-Funktionalität auch vieles von dem enthält, was DirectX mit seinen Vertex-, Hüllkurven-, Domain- und Geometrie-Shader-Stufen anbietet, dabei jedoch flexibler darin sein soll, in welcher Reihenfolge und Priorität die eigentliche Abarbeitung erfolgt.
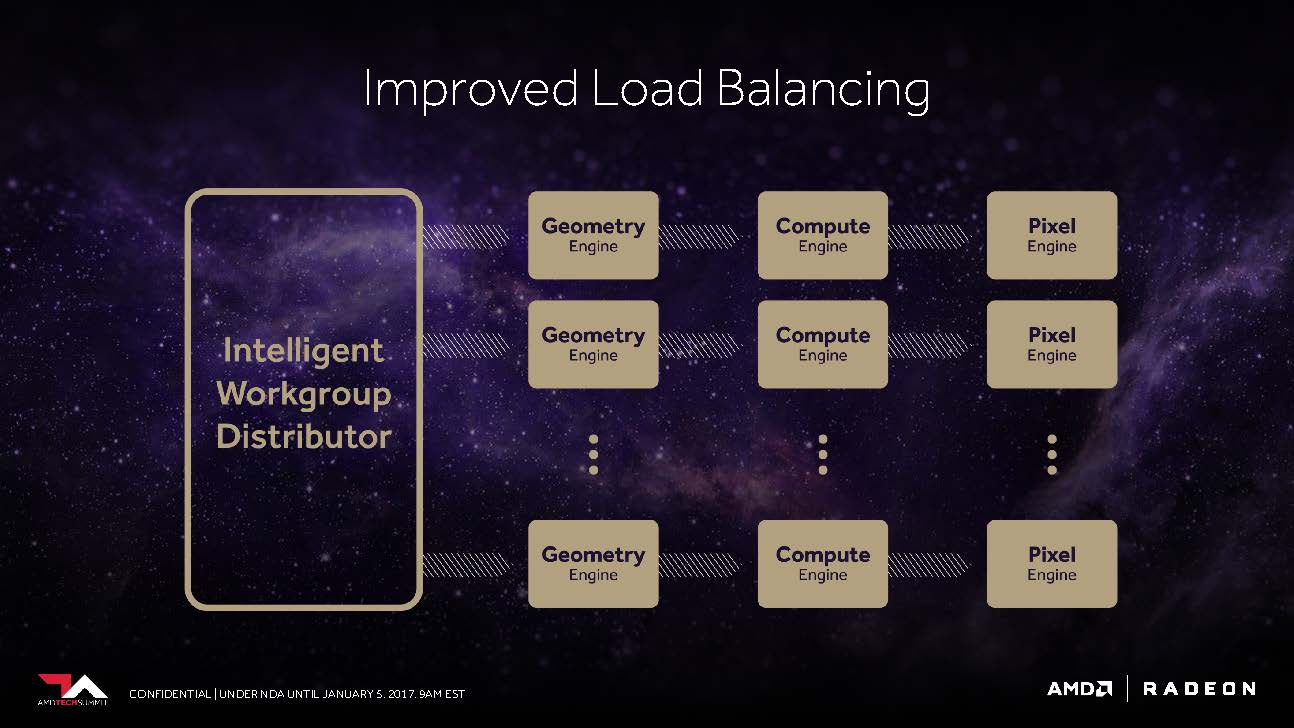
Das Frontend profitiert auch von einem verbesserten “Workgroup Distributor”, dem es gelingen soll, das Load-Balancing rund um die nunmehr programmierbare Hardware möglichst optimal zu gewährleiten. AMD bezog sich dabei auf die Zusammenarbeit mit den auf Effizienz fokussierten Konsolen-Entwicklern, deren Erfahrungen nun auch den PC-Spielern zu Gute kommen werden.
3. Die Vega-NCU (Next-Generation Compute Unit)
Mit seinen mittlerweile umfangreich am Markt vertretenen Pascal-basierten GPUs bedient Nvidia derzeit jedes Segment. Der größte und teuerste GP100-Prozessor bietet eine FP32-Spitzenleistung von bis zu 10,6 TFLOPS (bei maximalem Boost-Takt). Ein 1:2-Verhältnis der FP64-Kerne ergibt somit eine Spitzenleistung bei doppelter Genauigkeit von bis zu 5,3 TFLOPS. Die Unterstützung von FP16 (Half-Precision) beim Berechnen und Speichern ermöglicht dann bis zu 21,2 TFLOPS.
Die für den normalen Heimanwendermarkt konzipierten GP102- und GP104-GPUs bieten zwar immer noch die für Ihre Shader-Anzahl äquivalente FP32-Performance, aber sowohl die FP64- als auch die FP16-Performance werden künstlich beschnitten, so dass diese deutlich günstigeren Karten nicht sonderlich gut für bestimmte wissenschaftliche Berechnungen geeignet sind.
Im Gegensatz dazu scheint es so zu sein, dass AMD mit Vega bestrebt ist, auch außerhalb der vorgestellten MI-Karten die volle Rechenleistung an den Endkunden weiterzugeben und somit gegenüber den Mitbewerberkarten einen gewissen Mehrwert für normale Endanwender zu schaffen.

Der CU-Block mit seinen 64 zu IEEE 754-2008 kompatiblen Shadern bleibt als solcher bestehen – nur dass AMD ihn jetzt NCU (Next-Generation Compute Unit) nennt, der auch die Unterstützung für neue Datentypen beinhaltet. Logischerweise ergeben dann diese 64 Shader samt Ihrer Maximalleistung von zwei Gleitkomma-Operationen pro Zyklus ein Maximum von 128 32-Bit-Operationen pro Takt.
Nutzt man mit F16 gepackte Berechnungen, ergeben sich daraus bereits bis zu 256 16-Bit-Operationen pro Takt. AMD schlussfolgert daraus, dass es unter optimalen Voraussetzungen sogar bis zu 512 8-Bit-Operationen pro Taktzyklus sein könnten. Auch bei FP64 (Double Precision) scheint AMD kein Problem zu haben, die volle, unbeschnittene Leistung auf die Allgemeinheit loszulassen.
Der Anstoß für diese Flexibilität dürfte wohl aus der Konsolenwelt gekommen sein. Immerhin wissen wir ja, dass Sonys PlayStation 4 Pro bis zu 8,4 TFLOPS bei der FP16-Performance erreichen kann, also das Zweifache ihrer Leistung bei 32-Bit-Operationen. Oder vielleicht sind auch AMDs Bestrebungen, im Bereich des Machine Learning und Training mit Produkten wie der MI25 Fuß zu fassen, der eigentliche Auslöser.

Unter Umständen ist es am Ende sogar beides, um auch in Bereichen außerhalb von Nvidias aktueller Marktpräsenz zu wildern. In beiden Fällen können neue Konsolen, ganze Rechenzentren und natürlich auch PC-Gamer sowie semi-professionelle Anwender im gleichen Maße profitieren.
AMD meinte auch, dass die NCUs für höhere Taktraten optimiert sind, was jedoch nicht besonders verwunderlich ist. Aber man setzt gleichzeitig auch auf größere Anweisungspuffer (Instruction Buffer), um die Recheneinheiten über die gesamte Zeit möglichst gut auslasten zu können.
4. Die Next-Generation Pixel Engine
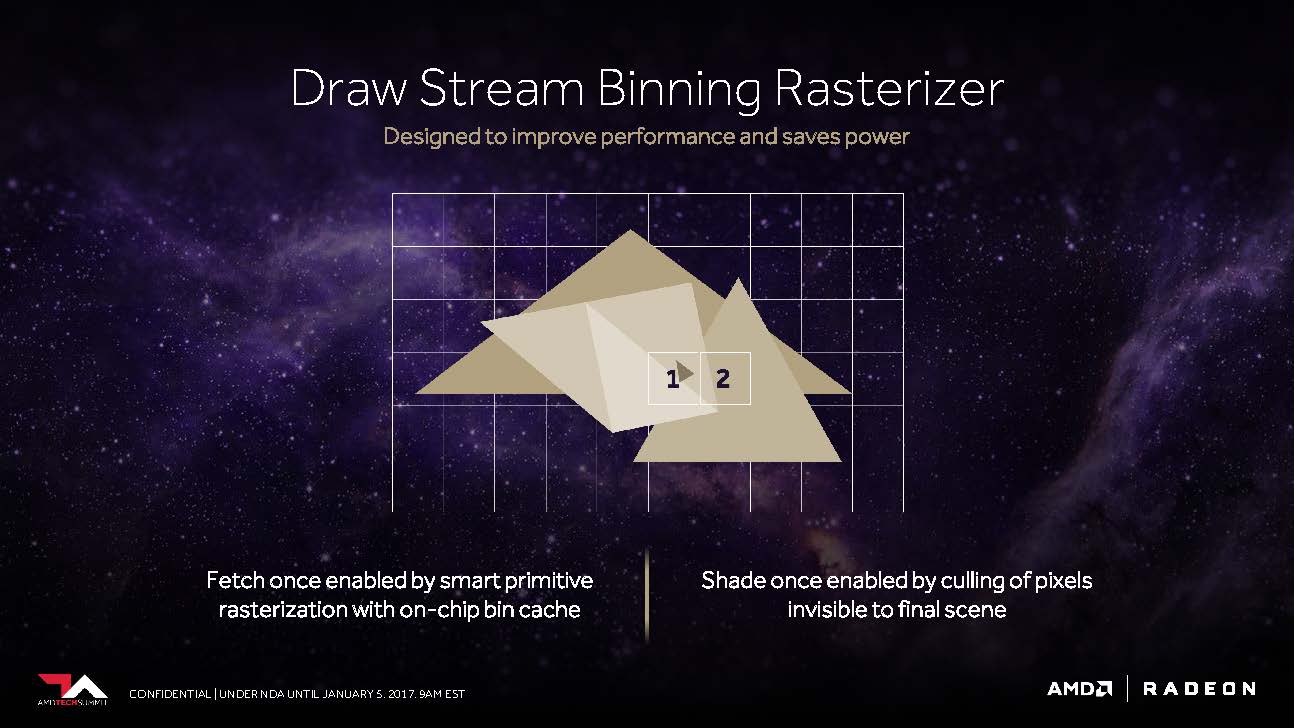
Das vierte Kernthema bei AMDs Ausführungen besteht eigentlich sogar aus zwei Teilbereichen. Das erste wäre das, was Raja Koduri als “Draw Stream Binning Rasterizer” bezeichnet und das als Ergänzung des traditionellen ROP in der Lage sein soll, die Performance zu steigern und trotzdem gleichzeitig noch Energie zu sparen.
So soll es ein spezieller Cache auf dem Chip ermöglichen, dass der Rasterizer die Daten für sich überschneidende Polygone nur einmal bearbeiten muss und all jene Pixel weglässt, die in der fertigen Szene sowieso nicht sichtbar wären.
Der zweite Punkt ist der, dass AMD seine Cache-Hierarchie generell und grundlegend so geändert hat, dass die Back-Ends für das Rendering nun direkt am L2-Cache angebunden sind.
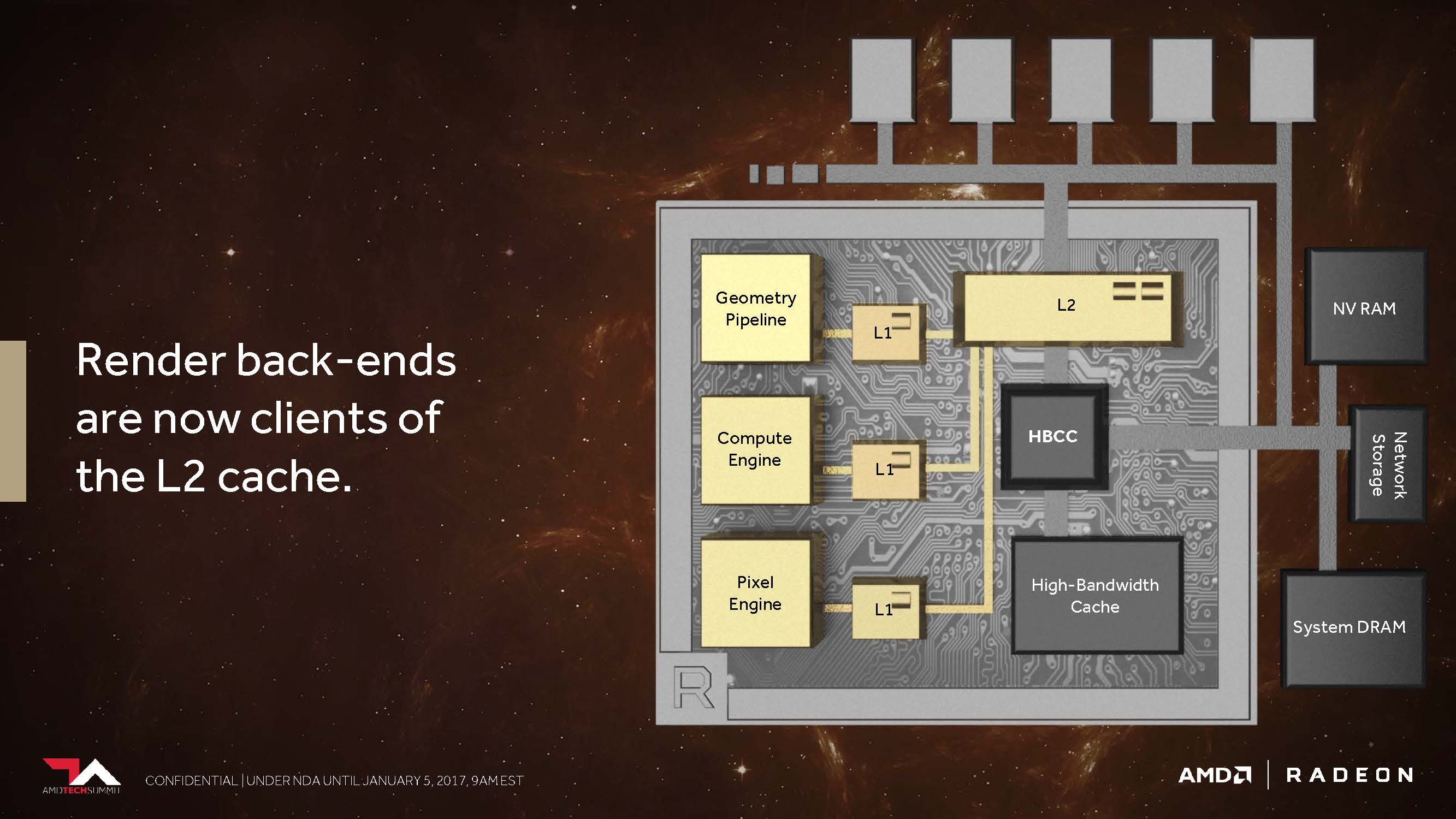
In den Architekturen vor Vega besaß AMD weder für nicht-kohärente Pixel noch die Texturen einen passenden Speicherzugriff, der es den einzelnen Pipelinestufen ermöglicht hätte, diese über einen gemeinsam genutzten Punkt zu synchronisieren.
So wurde beispielsweise eine Textur, die als Resultat einer Szene für die spätere Verwendung gerendert wurde, wieder den ganzen Weg zurück bis hin zum Grafikspeicher außerhalb des Grafikchips geschickt, bevor sie dann erneut aufgerufen werden konnte.
Dies umgeht AMD nun mit dem kohärenten Zugriff, welcher – so sagt es jedenfalls AMD – immer dann eine enorme Performance-Steigerung bieten soll, wenn beispielsweise Deffered Shading zum Einsatz kommt.
Fazit
Das Vega-Kapitel auf dem Tech Summit 2016 war am Ende ein vollgepackter Vortrag mit einigen wenigen echten Highlights und auch so einigen Füllstoffen aus dem, was wir bereits kannten.
Das, was uns Raja Koduri in seinem Vortrag über die neue Hardware zeigte, wird natürlich auch Software-seitig noch einen sehr großen Entwicklungsaufwand fordern. Um die neuen Features wirklich effizient und vollumfänglich nutzen zu können, wird wohl noch einige Zeit für die richtigen Anpassungen benötigt werden.
Einen ersten Einblick auf das, was möglich sein könnte, war die Doom-Demonstration in Ultra-HD bei maximalen Settings, bei der ein frühes Vega-Board immerhin im gut spielbaren 70-FPS-Bereich rendern konnte. Leider war das Testsystem vor lauter Geheimniskrämerei komplett zugeklebt, was auch die Lüftungsöffnungen betraf, so dass die daher garantiert am thermischen Limit arbeitende Karte mit Sicherheit nicht die volle Performance bieten konnte.
So bleibt uns am Ende als Fazit nur die Erkenntnis, dass alles anders und besser werden soll, man aber noch nicht bereit oder willens war, mehr Details zu zeigen als wir hier gerade beschrieben haben. Damit heißt es also erneut zu warten, bis sich aus der Fata Morgana dann endlich reale und für alle verfügbare Hardware materialisiert.
















Kommentieren