













Auch auf die Gefahr hin, dass wir uns wiederholen, wollen wir vorab noch einmal auf die wichtigsten Neuerungen bei Vega eingehen. Mit der Vega64 bietet AMD nämlich nach der Vega Frontier Edition nunmehr eine neue GPU-Generation an, in die über 200 Änderungen und Verbesserungen bei der Umgestaltung der Architektur geflossen sein sollen. Auch wenn es am Ende wohl eher auf eine Art neue GCN-Generation hinausläuft: AMD betonte erneut, dass es sich um eine komplett neu geschaffene Lösung handelt.

HBM2 als skalierbare Speicherarchitektur
Als ersten Anhaltspunkt für Vegas Architekturänderung führt man seitens AMD den Speicher und die gesamte, dazugehörige Infrastruktur ins Feld. Grund genug für diesen Fokus ist der stetig wachsende Speicherbedarf. Sowohl AMD und Nvidia arbeiten beide separat an Möglichkeiten, um den Host-Prozessor-Overhead reduzieren, sowie den Durchsatz zu maximieren und auf diese Weise Engpässe beim Zugriff auf die GPU zu minimieren – insbesondere diejenigen, die angesichts der umfangreichen Datenmengen immer wieder auftreten können.
Es kommt somit darauf an, noch mehr Speicherkapazitäten noch näher an die GPU zu bringen und dabei die Kosten nicht explodieren zu lassen. Wie es scheint, hat AMD Vega mit einer deutlich flexibleren Speicherhierarchie einen großen Schritt näher an dieses wichtige Ziel gebracht. Mit HBM2 nutzt Vega dafür eine interessante, neue Komponente und man nennt diese Ansammlung von On-Package-Speicher, den man früher ziemlich unspektakulär auch schon als Frame-Buffer bezeichnete, nunmehr glanzvoll „High Bandwidth Cache“.

Bereits bei HBM (und Fiji) hatte AMD die Vision, den leistungsfähigsten Speicher so nah wie nur möglich an die GPU zu bringen. Das schließt auch den Arbeits- und Datenspeicher des gesamten Systems ein. Und auch wenn dies deutlich langsamere Technologien in diese Infrastruktur miteinschließt, sollte man HBM2 als konsequente Fortschreibung des eingeschlagenen Weges sehen. Denn eine bis zu achtfache Erhöhung der Kapazität eines jeden Stapels im direkten Vergleich zur ersten Generation ist durchaus ein beachtlicher Fortschritt, zumal auch die Verdopplung der Bandbreite pro Pin den maximal möglichen Durchsatz des Ganzen deutlich vergrößern hilft.
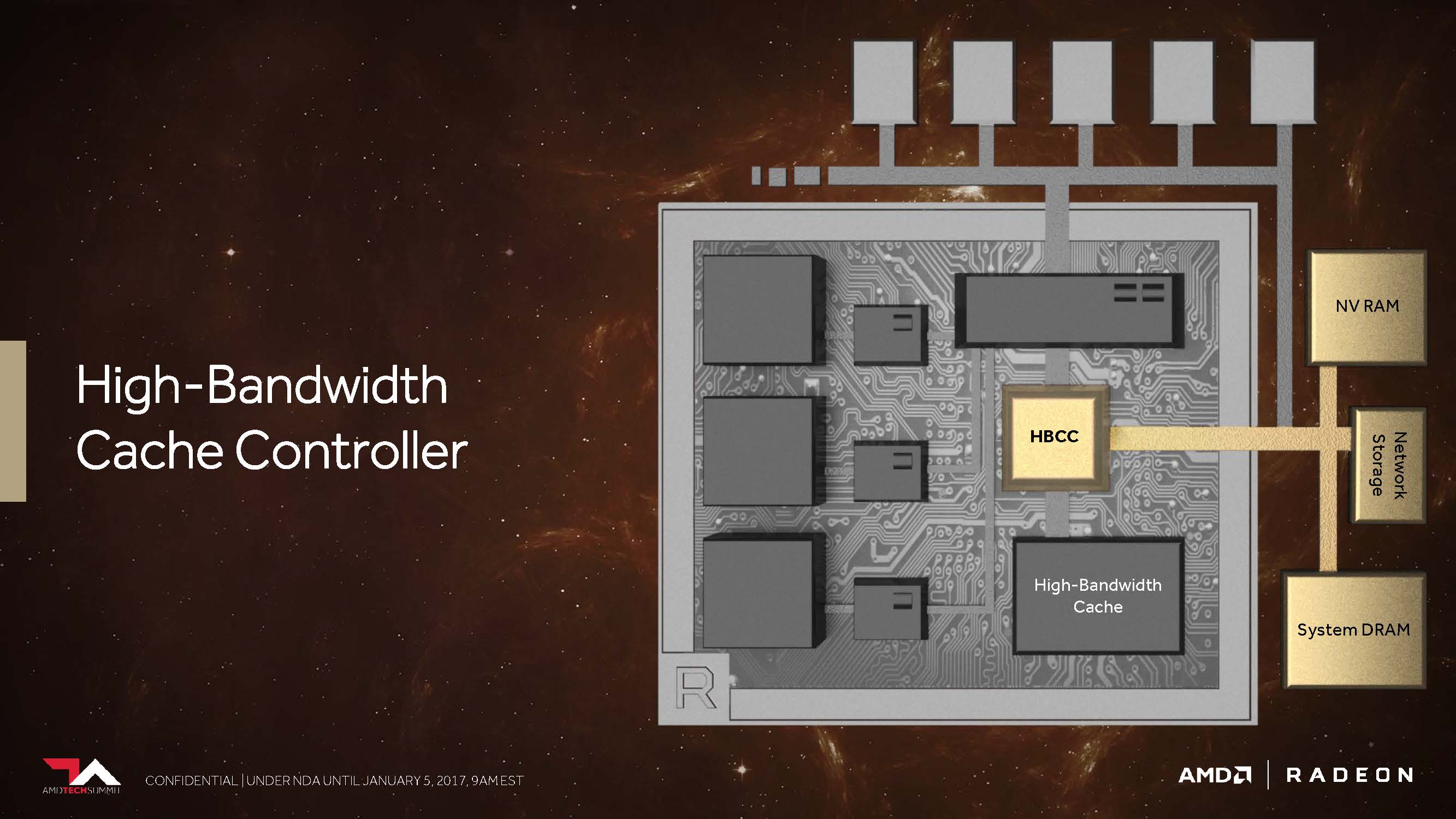
Das könnte die größten Auswirkungen auf die Gaming-Performance haben, sofern es sich auf das eigentliche Speichersubsystem bezieht. AMD gibt zudem dem neuen „High Bandwidth Cache“-Controller (HBCC), der mehr als der bisherige Speicher-Controller leisten muss, immerhin virtuell adressierbare 512 Terabyte für extrem große Datenmengen mit auf den Weg. Nur nutzen muss man es dann natürlich auch. Vega ist Dank HBCC jedoch in der Lage, mittels verschiedener programmierbarer Techniken Speicherseiten noch feiner abgestuft zu bewegen. So kann eine erhaltene Datenanforderung über den DMA-Transfer asynchron realisiert werden, während die GPU bereits zu einem anderen Thread gewechselt ist, um dort unterbrechungsfrei weiterarbeiten zu können.
Damit erhält der Controller die Daten faktisch „on-demand“, er kann sie aber auch vorausschauend zurückliefern. Dazu kommt, dass im HBM abgelegte Informationen im Systemspeicher wie ein zusätzlicher Cache einfach repliziert werden können oder aber der HBCC – was noch deutlich wichtiger scheint – mit einer einzigen Instanz auskommt, um Platz sparen und den Overhead reduzieren zu können.
Neue programmierbare Geometrie-Pipeline
Erinnern wir uns kurz zurück: Die erste Hawaii-GPU auf der Radeon R9 290 X brachte seinerzeit einige durchaus bemerkenswerten Verbesserungen im Vergleich zur Tahiti-GPU auf der Radeon HD 7970 mit. Eine davon betraf ein verbessertes Frontend mit nunmehr vier statt zwei Geometrie-Einheiten, von denen jede einzelne wiederum jeweils einen Geometry-Assembler, einen Vertex-Assembler und eine Tessellation-Einheit besaß.
Die darauffolgende Fiji-GPU als Radeon R9 Fury X setzte dann zwar erneut auf diese bereits von Hawaii bekannte Konfiguration, brachte aber dafür einige andere Neuerungen – beispielsweise eine deutlich gesteigerte Tessellation-Performance – mit. Aktuell nutzt die Ellesmere-GPU (Radeon RX 480) eine neue Handvoll Techniken, um aus der gleichen Konstellation mit den vier Geometrieeinheiten durch diverse Filteralgorithmen bzw. das Verwerfen unnötiger Polygone einen Leistungsvorteil herauszuarbeiten.
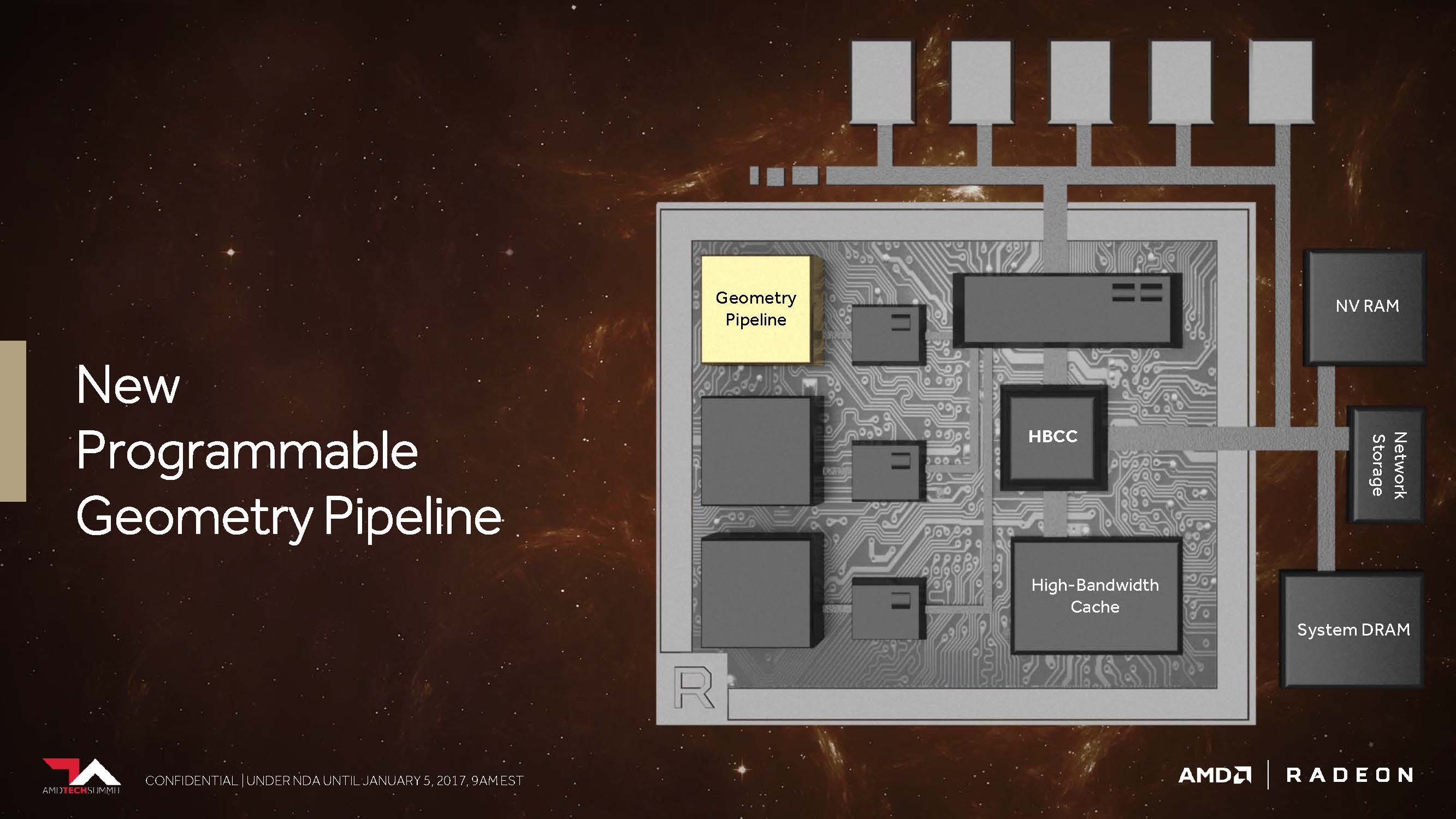
AMD versprach uns bereits letztes Jahr, dass Vega nunmehr in der Lage sein soll, in der Spitze immerhin bis 11 statt der maximal vier Polygone per Taktzyklus abarbeiten zu können, was dem bis zu 2,75-fachen entspricht. Dies ist die Folge dessen, was AMD als „New Primitive Shader Stage“ in die Geometrie-Pipeline eingefügt hat. Anstelle der in der Hardware fest verankerten, dadurch jedoch unflexiblen Funktionen nutzt man jetzt ein flexibel ausgelegtes Shader-Array für die Verarbeitung der anfallenden Polygone.
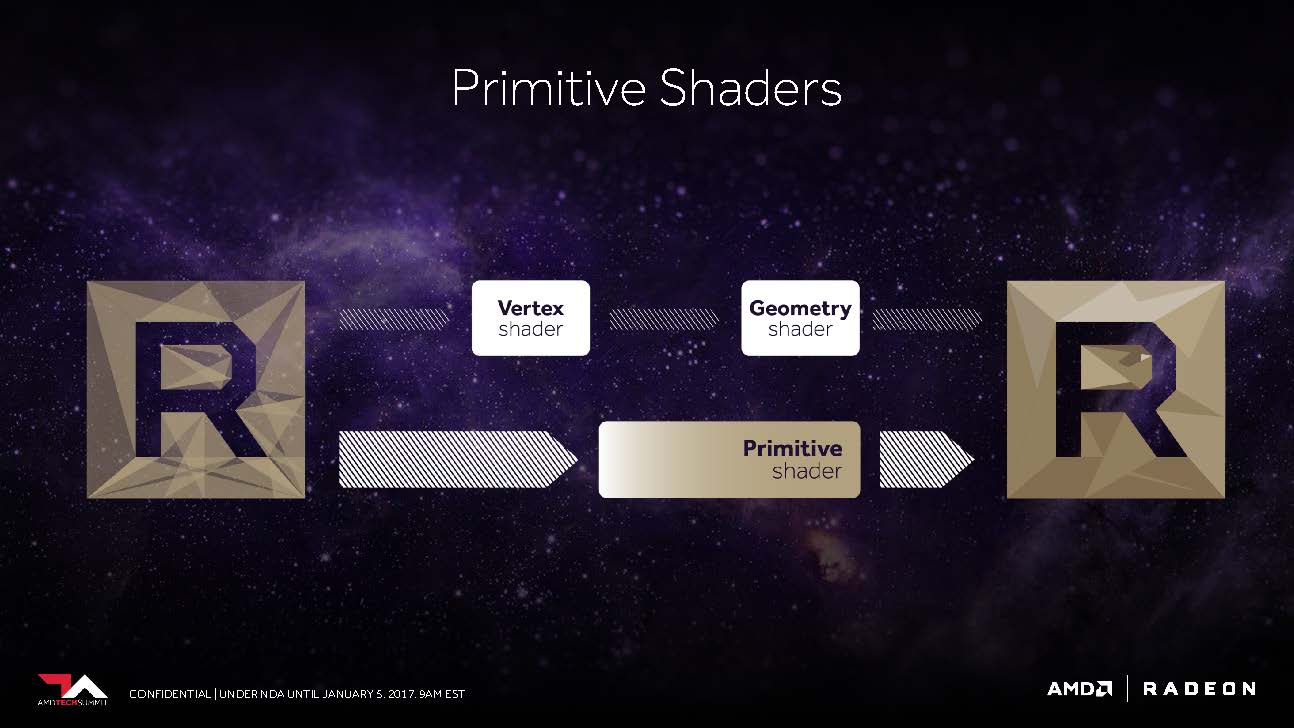
Vergleichen kann man dies am ehesten mit der Funktionalität eines Compute-Shaders für die Verarbeitung der Geometrieaufgaben – leicht und programmierbar sowie mit der Fähigkeit ausgestattet, nicht benötigte Polygone mit einer hohen Rate auch verwerfen zu können. Natürlich enthält diese Shader-Funktionalität auch vieles von dem, was auch DirectX mit seinen Vertex-, Hüllkurven-, Domain- und Geometrie-Shader-Stufen anbietet, aber man möchte flexibler sein, in welcher Reihenfolge und Priorität die eigentliche Abarbeitung erfolgt.
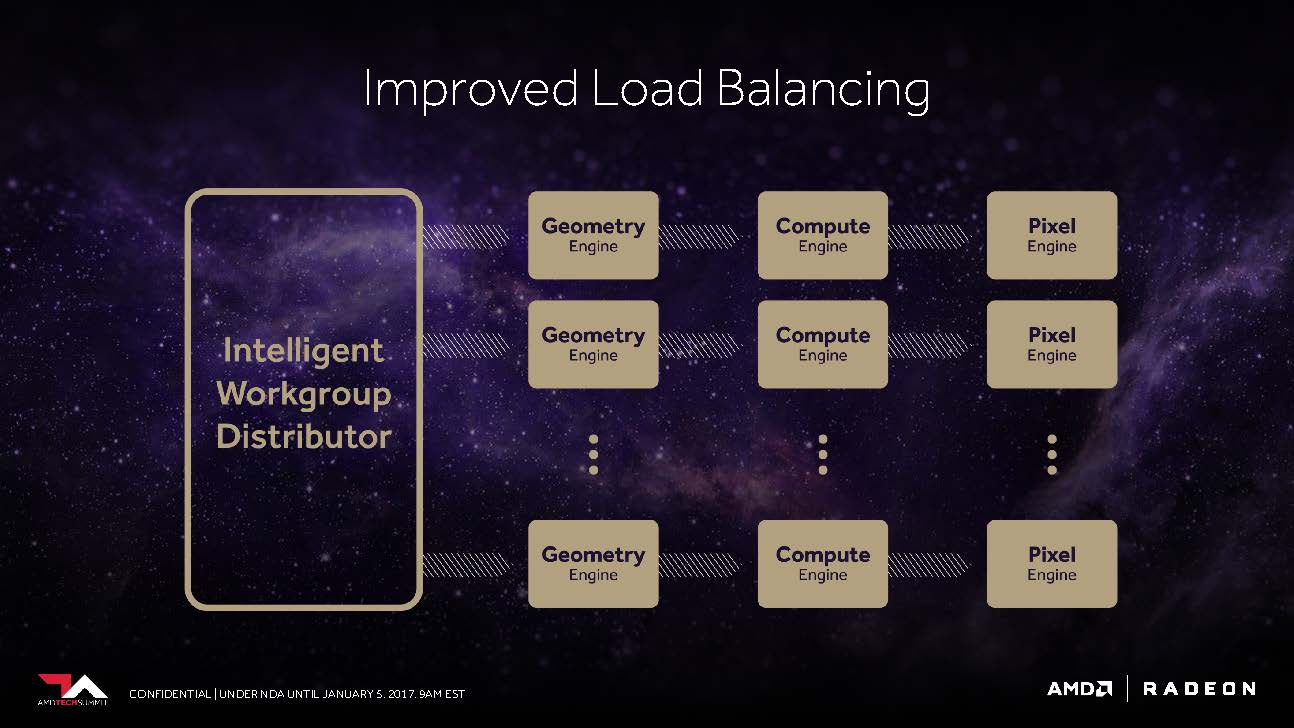
Das Frontend profitiert auch von einem verbesserten „Workgroup Distributor“, dem es gelingen soll, das Load-Balancing rund um die nunmehr programmierbare Hardware möglichst optimal zu gewährleiten.
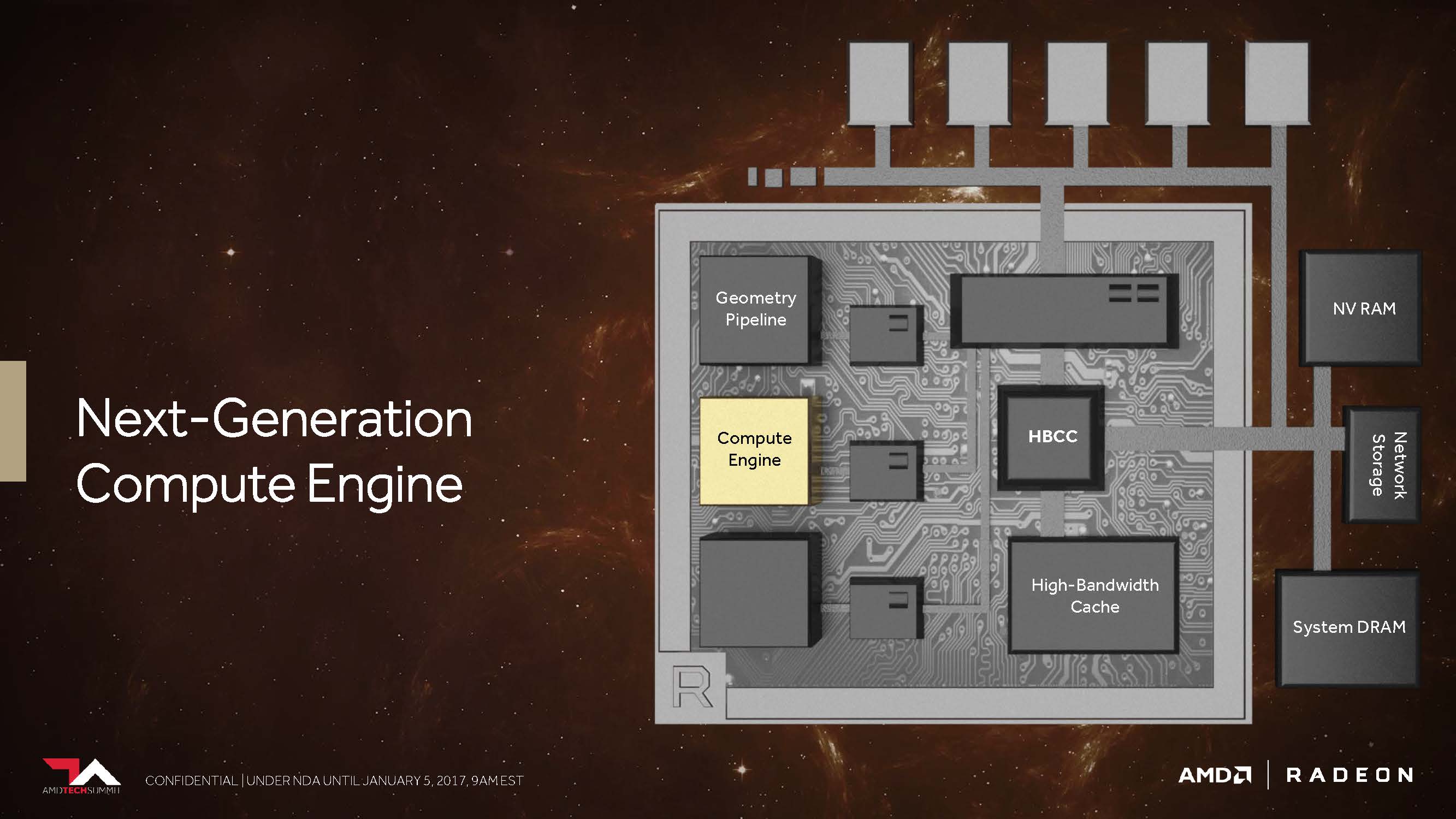
Die Vega-NCU (Next-Generation Compute Unit)
Mit seinen mittlerweile umfangreich am Markt vertretenen Pascal-basierten GPUs bedient Nvidia derzeit jedes Segment. Der größte und teuerste GP100-Prozessor bietet eine FP32-Spitzenleistung von bis zu 10,6 TFLOPS (bei maximalem Boost-Takt). Ein 1:2-Verhältnis der FP64-Kerne ergibt somit eine Spitzenleistung bei doppelter Genauigkeit von bis zu 5,3 TFLOPS. Die Unterstützung von FP16 (Half-Precision) beim Berechnen und Speichern ermöglicht dann bis zu 21,2 TFLOPS.
Die für den normalen Heimanwendermarkt konzipierten GP102- und GP104-GPUs bieten zwar immer noch die für Ihre Shader-Anzahl äquivalente FP32-Performance, aber sowohl die FP64- als auch die FP16-Performance werden künstlich beschnitten, sodass diese deutlich günstigeren Karten nicht sonderlich gut für bestimmte wissenschaftliche Berechnungen geeignet sind.
Im Gegensatz dazu ist AMD mit Vega und insbesondere der Frontier Edition bestrebt, auch außerhalb der vorgestellten MI-Karten die volle Rechenleistung an den Endkunden weiterzugeben und somit gegenüber den Mitbewerberkarten einen gewissen Mehrwert für normale Endanwender zu schaffen. Zumindest als Marketing-Ansatz ergibt dies sogar einen Sinn, denn man ist sich sicher, damit eine komplett neue Zielgruppe zu erreichen.

Der CU-Block mit seinen 64 zu IEEE 754-2008 kompatiblen Shadern bleibt als solcher bestehen – nur, dass AMD ihn jetzt NCU (Next-Generation Compute Unit) nennt, der auch die Unterstützung für neue Datentypen beinhaltet. Logischerweise ergeben dann diese 64 Shader samt Ihrer Maximalleistung von zwei Gleitkomma-Operationen pro Zyklus ein Maximum von 128 32-Bit-Operationen pro Takt.
Nutzt man mit F16 gepackte Berechnungen, ergeben sich daraus bereits bis zu 256 16-Bit-Operationen pro Takt. AMD schlussfolgert daraus, dass es unter optimalen Voraussetzungen sogar bis zu 512 8-Bit-Operationen pro Taktzyklus sein könnten. Auch bei FP64 (Double Precision) scheint AMD kein Problem zu haben, die volle, unbeschnittene Leistung auf die Allgemeinheit loszulassen.
Der Anstoß für diese Flexibilität dürfte wohl aus der Konsolenwelt gekommen sein. Immerhin wissen wir ja, dass Sonys PlayStation 4 Pro bis zu 8,4 TFLOPS bei der FP16-Performance erreichen kann, also das Zweifache ihrer Leistung bei 32-Bit-Operationen. Oder vielleicht sind auch AMDs Bestrebungen, im Bereich des Machine Learning und Training mit Produkten wie der MI25 Fuß zu fassen, der eigentliche Auslöser.

Unter Umständen ist es am Ende sogar beides, um auch in Bereichen außerhalb von Nvidias aktueller Marktpräsenz zu wildern. In beiden Fällen können neue Konsolen, ganze Rechenzentren und natürlich auch PC-Gamer sowie semi-professionelle Anwender im gleichen Maße profitieren. Neben dem Umstand, dass die NCUs auch für höhere Taktraten optimiert worden sind, setzt gleichzeitig auch auf größere Anweisungspuffer (Instruction Buffer), um die Recheneinheiten über die gesamte Zeit möglichst gut auslasten zu können.
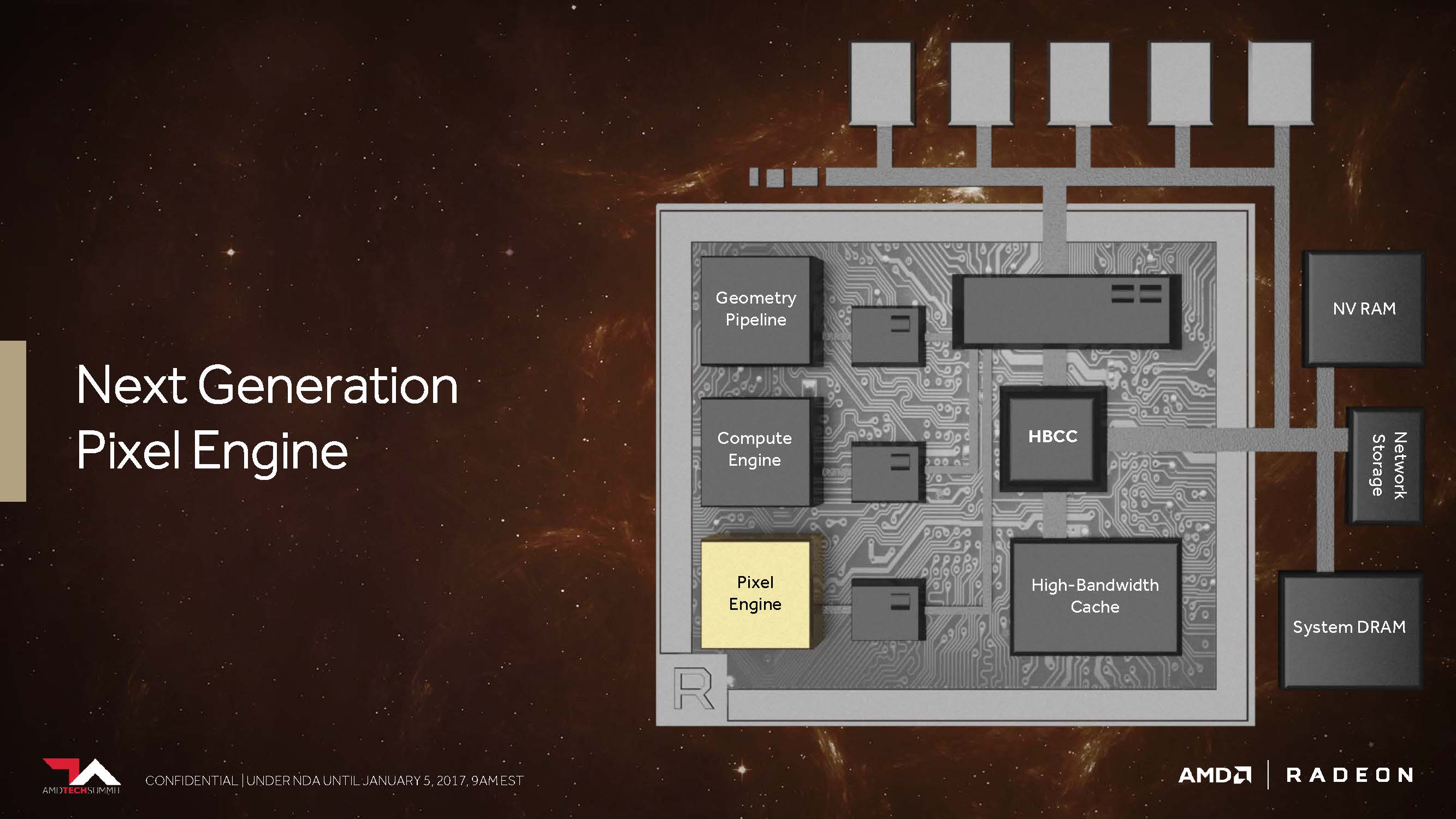
Next-Generation Pixel Engine und ein Fragezeichen
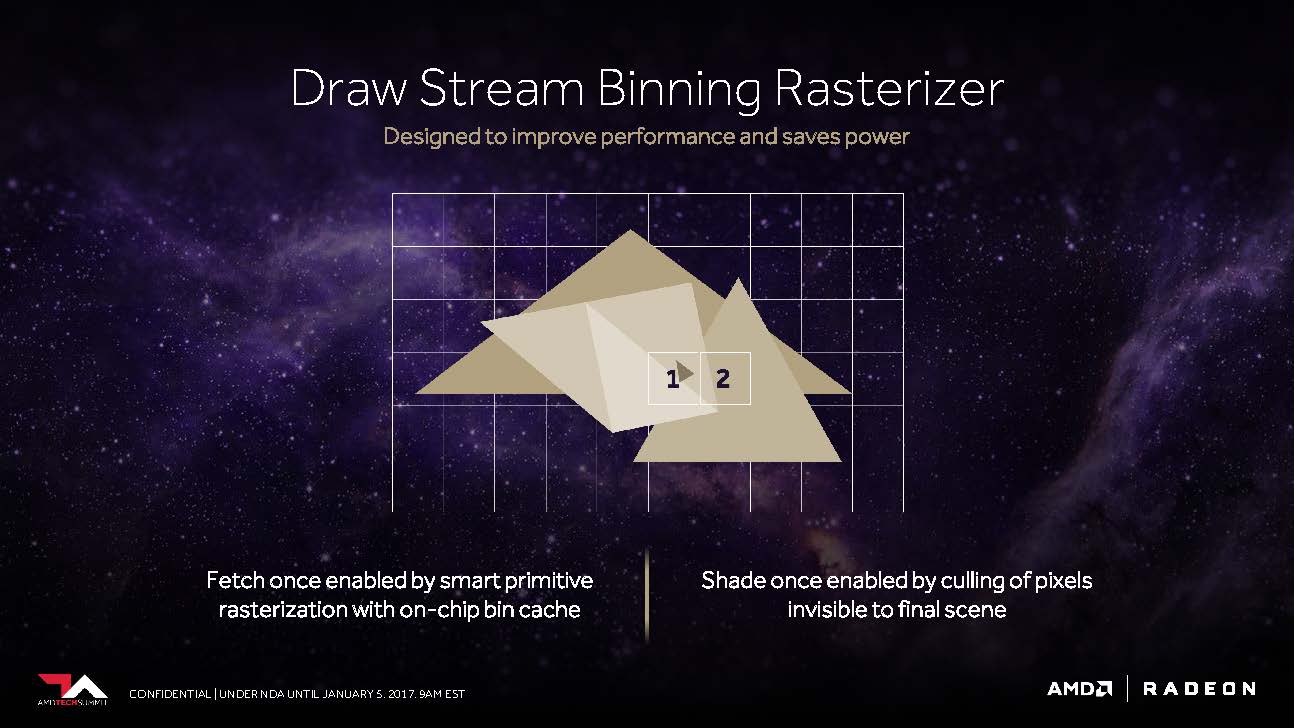
Kommen wir nun zu dem, was AMD als „Draw Stream Binning Rasterizer“ bezeichnet und das als Ergänzung des traditionellen ROP in der Lage sein soll, die Performance zu steigern, sowie trotzdem gleichzeitig auch noch Energie zu sparen.
So soll es ein spezieller Cache auf dem Chip ermöglichen, dass der Rasterizer die Daten für sich überschneidende Polygone nur einmal bearbeiten muss und all jene Pixel weglässt, die in der fertigen Szene sowieso nicht sichtbar wären.
Der zweite Punkt ist der, dass AMD seine Cache-Hierarchie generell und grundlegend so geändert hat, dass die Back-Ends für das Rendering nun direkt am L2-Cache angebunden sind.
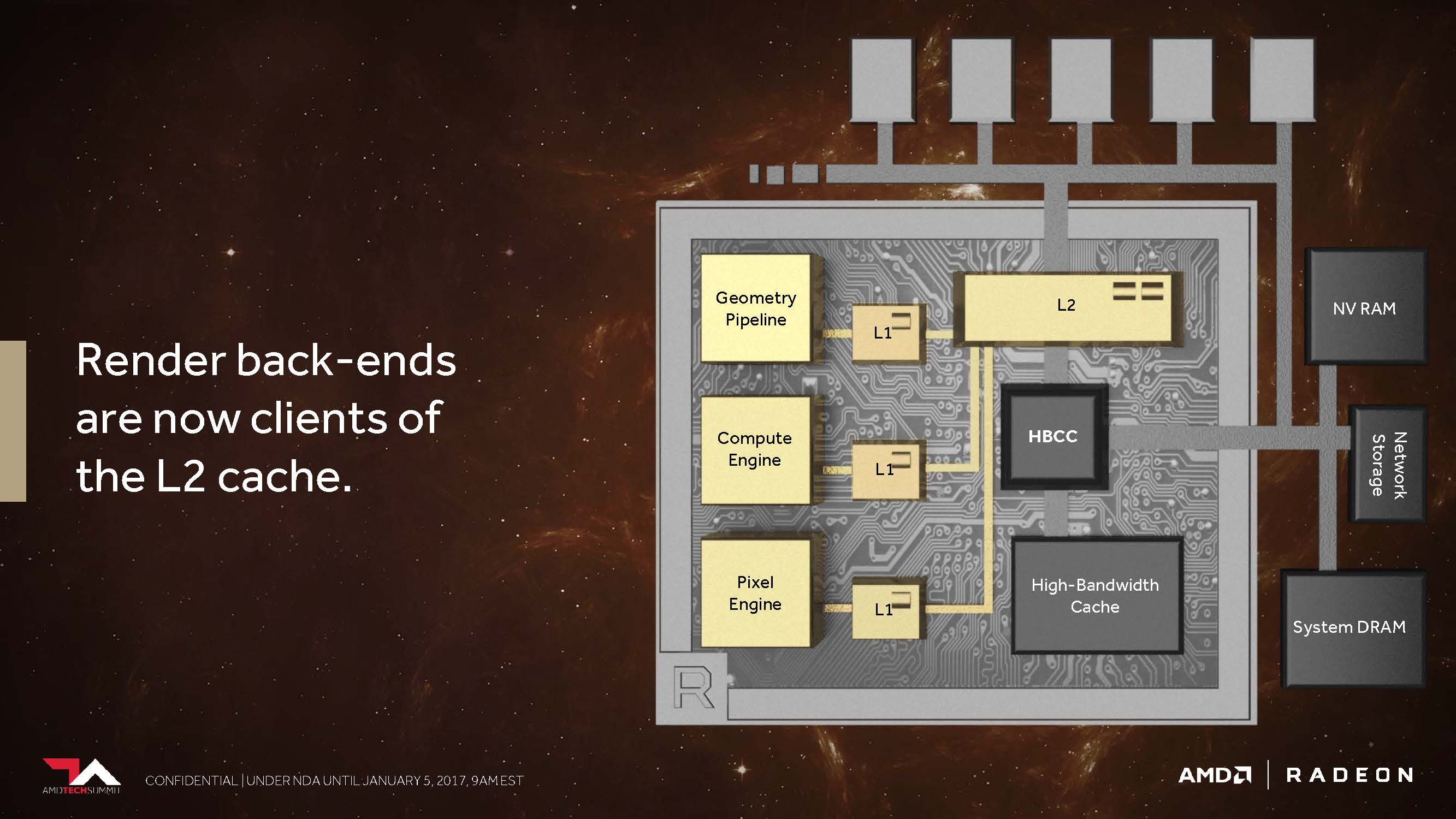
In den Architekturen vor Vega besaß AMD weder für nicht-kohärente Pixel noch die Texturen einen passenden Speicherzugriff, der es den einzelnen Pipelinestufen ermöglicht hätte, diese über einen gemeinsam genutzten Punkt zu synchronisieren. So wurde beispielsweise eine Textur, die als Resultat einer Szene für die spätere Verwendung gerendert wurde, wieder den ganzen Weg zurück bis hin zum Grafikspeicher außerhalb des Grafikchips geschickt, bevor sie dann erneut aufgerufen werden konnte. Dies alles umgeht AMD nun mit dem kohärenten Zugriff, welcher – so sagt es jedenfalls AMD – immer dann eine enorme Performance-Steigerung bieten soll, wenn beispielsweise Deffered Shading zum Einsatz kommt.
Aber – ohne jetzt bereits ausführlich spoilern zu wollen – so recht hat diese versprochene Rakete auch mit dem Einsatz des neuesten Treibers noch nicht zünden können. BIOS-Update, Treiber oder doch nichts – alles ist im Verlaufe der Zeit sicher noch möglich. Und so wird es wohl darauf hinauslaufen, was schon bei Fiji und Hawaii der Fall war – guter Wein muss erst einmal reifen (vor allem roter). Aber eine Sensation? Warten wir auf die Benchmarks der nächsten Seiten.
- 1 - Einführung und Übersicht
- 2 - Details zu Architektur und HBM2-Speicher
- 3 - Demontage, Kühler und Interposer-Details
- 4 - Platinendesign und Detailinformationen
- 5 - Ashes of the Singularity: Escalation
- 6 - Battlefield 1
- 7 - Warhammer 40,000: Dawn of War III
- 8 - Doom (2016)
- 9 - Tom Clancy's Ghost Recon Wildlands
- 10 - Hitman (2016)
- 11 - Metro Last Light (Redux)
- 12 - Rise of the Tomb Raider
- 13 - Tom Clancy's The Division
- 14 - The Witcher 3
- 15 - Und kann sie Mining?
- 16 - Leistungsaufnahme im Detail
- 17 - Takt, Temperaturen und Geräuschemission
- 18 - Zusammenfassung und Fazit

















Kommentieren