











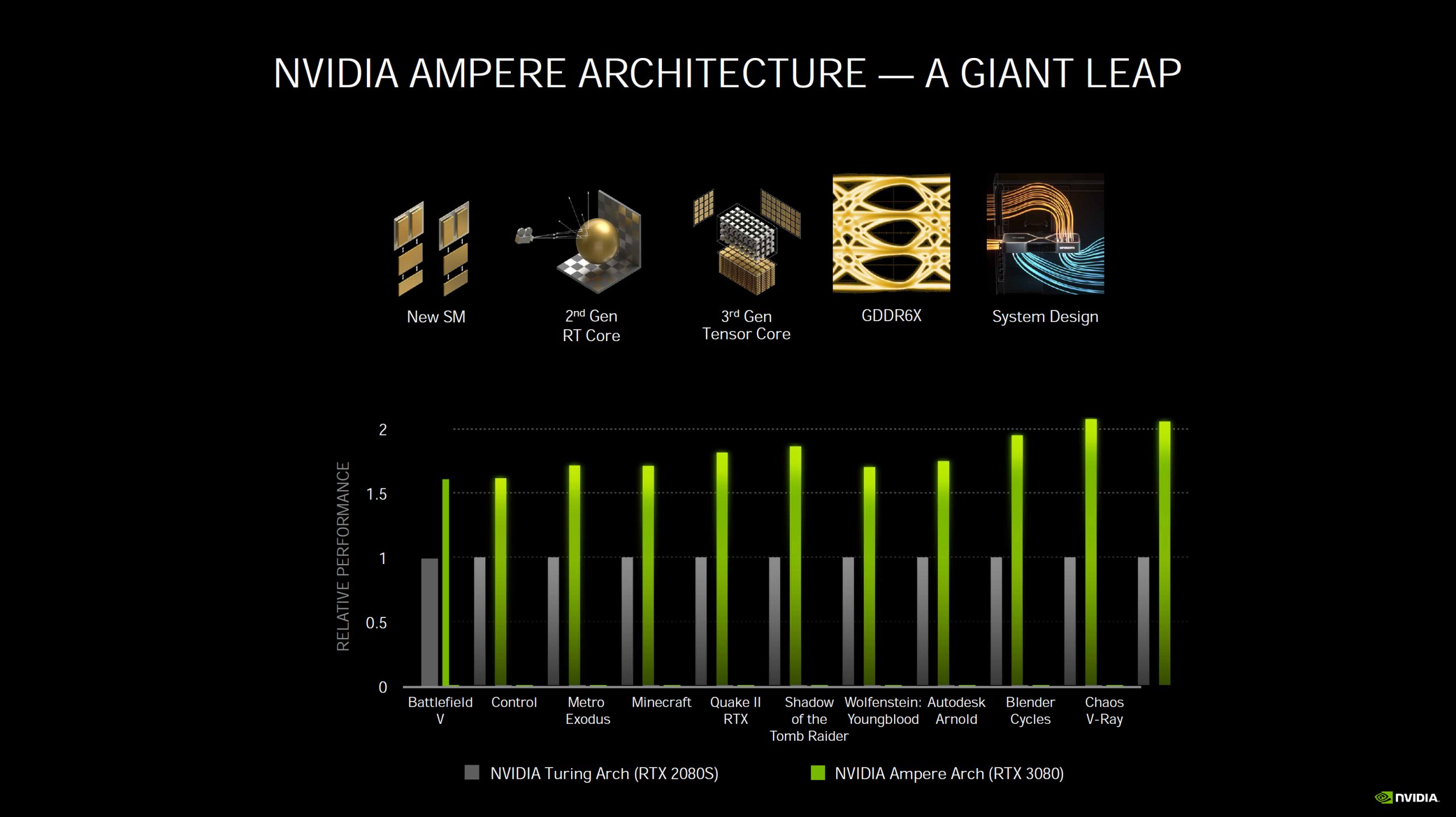
Die GeForce RTX 3090 als kommender Top Dog und die RTX 3080 als aktuelles Flaggschiff setzen auf den GA102-Prozessor, der so ziemlich alles anders macht als bisher. Mit den angegebenen 10.496 CUDA Cores knallt man zumindest auf dem Papier (aber nicht nur dort) eine eigentlich unglaubliche Anzahl an ALUs hin, die sicher nicht nur AMD auf den ersten Blick geschockt haben dürfte. Aber dass man diesen wirklich smarten Kunstgriff mit Hilfe des doch eher etwas granulären 8-nm-Nodes von Samsung geschafft haben will, erfordert allerdings eine nähere Betrachtung. Doch wie erreicht man nun so eine theoretische Rechenleistung von unglaublichen 35,7 FP32-TFLOPS?

Neue SM und ganz viel Gleitkomma
Der Trick liegt in den Streaming Multiprocessors (SM) von Ampere, die grundlegend umgebaut wurden. Die Basis mag noch ähnlich der von Turing sein, aber es haben sich wichtige und vor allem entscheidende Dinge geändert, auf die ich gleich eingehen werde. Die RT- und Tensor-Cores betrifft dies natürlich auch. Betrachten wir doch einmal das untenstehende Schema der GeForce RTX 3080. Die GPU selbst besteht wie gehabt aus mehreren GPC (Graphics Processor Cluster). Dort finden wir dann jeweils die SM (Streaming Multiprocessors) mit den bekannten Recheneinheiten, die TPC (Texture Processing Cluster) welche die Textureinheiten beinhalten, die üblichen Geometrieeinheiten und – das ist neu – auch die ROPs.
Bis einschließlich Turing hingen die ROPs ja noch am Speicherinterface, weshalb deren Anzahl auch von der Breite des Interfaces abhing. Nun aber sind die ROPs direkt im GPC untergebracht das über 2 ROP-Partitionen mit jeweils 8 ROPs verfügt. Damit steigert sich auch die Anzahl der ROPs gegenüber der bisherigen Zählweise signifikant. Da aber pro GPC zwei ROP-Partitionen verbaut sind und der volle Chip über sieben GPC verfügt, ergibt dies maximal 14 Partitionen und damit 112 ROPs statt 96. Auf der GeForce RTX 3080 ist im Vergleich zur Maximum jedoch ein GPC abgeschaltet, was die Anzahl der ROPs entsprechend auch sinken lässt.
Die SM haben eine wirklich große Wandlung vollzogen, die letztendlich auch in der gesteigerten Leistung resultiert. Ein einzelner SM bei Turing bestand noch aus 64 FP32-ALUs für die Gleitkomma-Berechnungen sowie 64 INT32-ALUs für Ganzzahl-Berechnungen, aufgeteilt in vier Blöcke zu je 16 FP32- und 16 INT32-ALUs. Der Trick dabei: die FP- und die INT-ALUs können gleichzeitig angesprochen werden. Und Ampere? Die 64 reinen FP32-ALUs pro SM bleiben weiterhin erhalten, aber die 64 INT32-ALUs stockt man um 64 weitere auf, die nach wie vor auch wahlweise Floating-Point- und zusätzlich Integer-Berechnungen durchführen können, mit einer Einschränkung: das geht nun nicht mehr parallel. Die Aufteilung in jeweils 4 Blöcke bleibt erhalten, jedoch mit einem getrennten Datenpfad.

Fasst man das nun zusammen, dann merkt man, dass ein Turing SM bis zu 64 FP32- und 64 INT32-Berechnungen gleichzeitig ausführen konnte. Bei Ampere hingegen können im Idealfall exklusiv sogar bis zu 128 FP32-Berechnungen durchgeführt werden, was einer faktischen Verdopplung entspricht. Ansonsten bleibt es im „Mischbetrieb“ bei jeweils bis zu 64 FP32- und 64 INT32-Berechnungen und einer ähnlichen Rechenleistung. Und nun haben wir auch den Grund für die Verdopplung der theoretischen FP32-Rechenleistung bei Ampere gegenüber Turing.
Dass Nvidia in Bezug auf die Anzahl der FP32-ALUs jetzt von der doppelten Anzahl CUDA-Cores schreibt, ist nachvollziehbar aber nur dann korrekt, wenn man wirklich nur FP32-Berechnungen durchführt. Bei Szenarien, in denen Gleitkomma-berechnungen benötigt werden, wird Ampere also deutlich schneller sein als Turing, logisch. Müssen aber sowohl Gleitkomma- als auch Ganzzahlen berechnet werden, sinkt die Mehrperformance deutlich ab, je nach Anteil und der optimalen Aufgaben-Verteilung (die eine echte Herausforderung ist) auf die einzelnen SM. Trotzdem ist Ampere auch im ungünstigsten Fall noch schneller als Turing, immerhin.
Ganz wichtig für eine optimale Aufgabenverteilung und damit auch die zielführende Auslastung und die Vermeidung von unnützem Leerlauf sind die quasi doppelt so schnell arbeitenden Bereiche beim Shared Memory und L1-Cache in jedem SM. Der L1-Cache der GeForce RTX 3080 wächst zudem von 96 auf 128 KB und kann auch seine Bandbreite noch einmal auf 219 GB/s steigern. Der schneller L2-Cache der RTX 3080 sank gegenüber Turing von 6 auf 5 MB, für die RTX 3090 gibt es keine Aussagen, aber es sollte identisch sein.
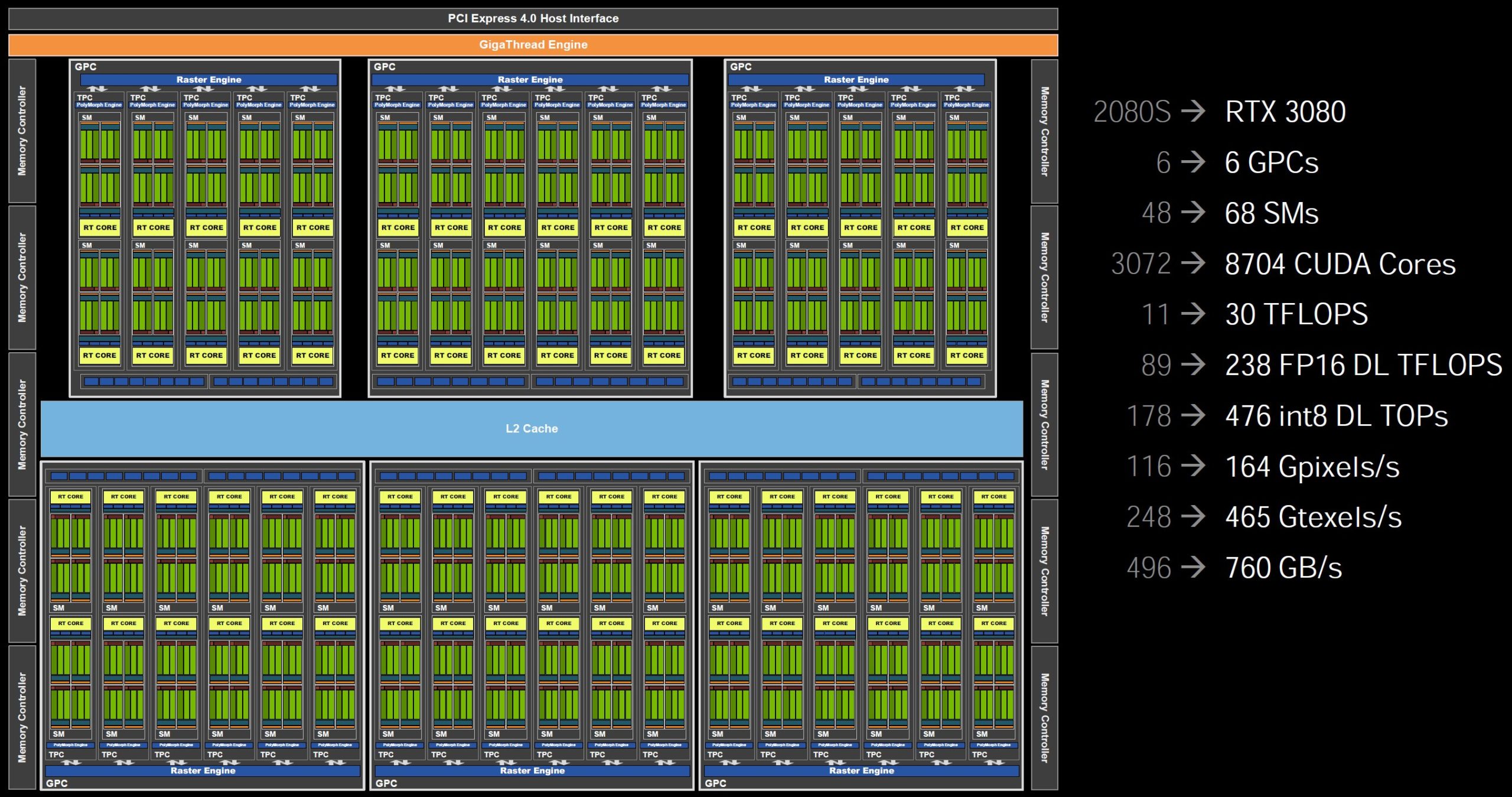
Zusammenfassung des Aufbaus der GeForce RTX 3090, 3080 und 3070
Der GA102 verfügt im ungekürzten Maximalausbau über 7 GPCs mit je 12 SMs was 10.752 CUDA-Cores entspräche. Bei der GeForce RTX 3090 sind jedoch zwei SM deaktiviert, was 10.496 ALUs ergibt. Bei der GeForce RTX 3080 mit dem gleichen GA102 ist hingegen ein ganzer GPC abgeschaltet und nur vier von sechs GPC nutzen die vollen 12 SMs, den zwei sind wiederum auf 10 SMs reduziert. Rechnet man nun die SMs hoch, ergibt die 68 und somit 8.704 CUDA-Cores. Die GeForce RTX 3070 mit GA104-GPU besitzt übrigens nur noch 4 GPCs, von deren 48 SMs ebenfalls zwei abgeschaltet sin müssten, was dann in 5.888 CUDA Cores resultiert, die kommuniziert wurden.


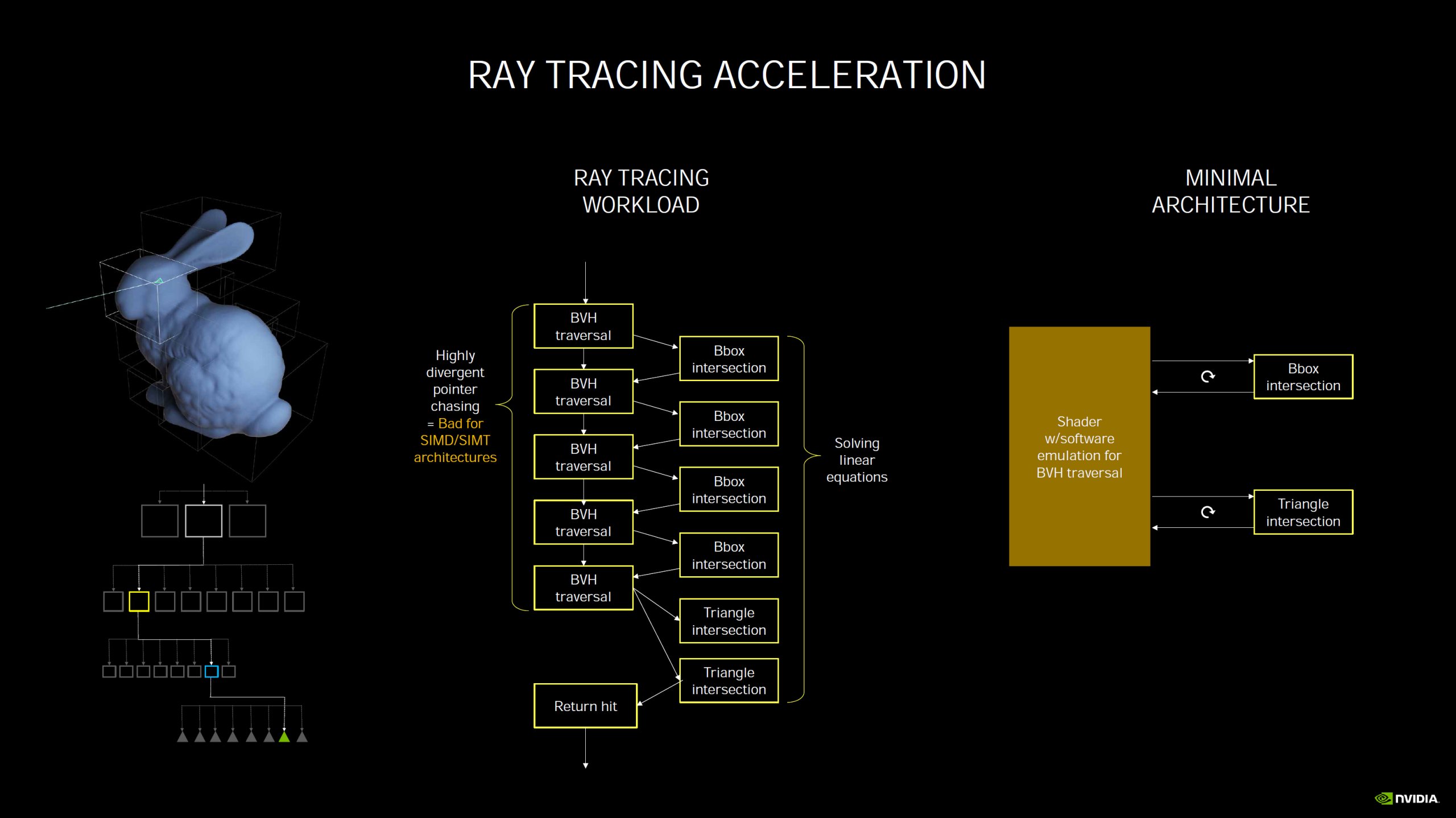
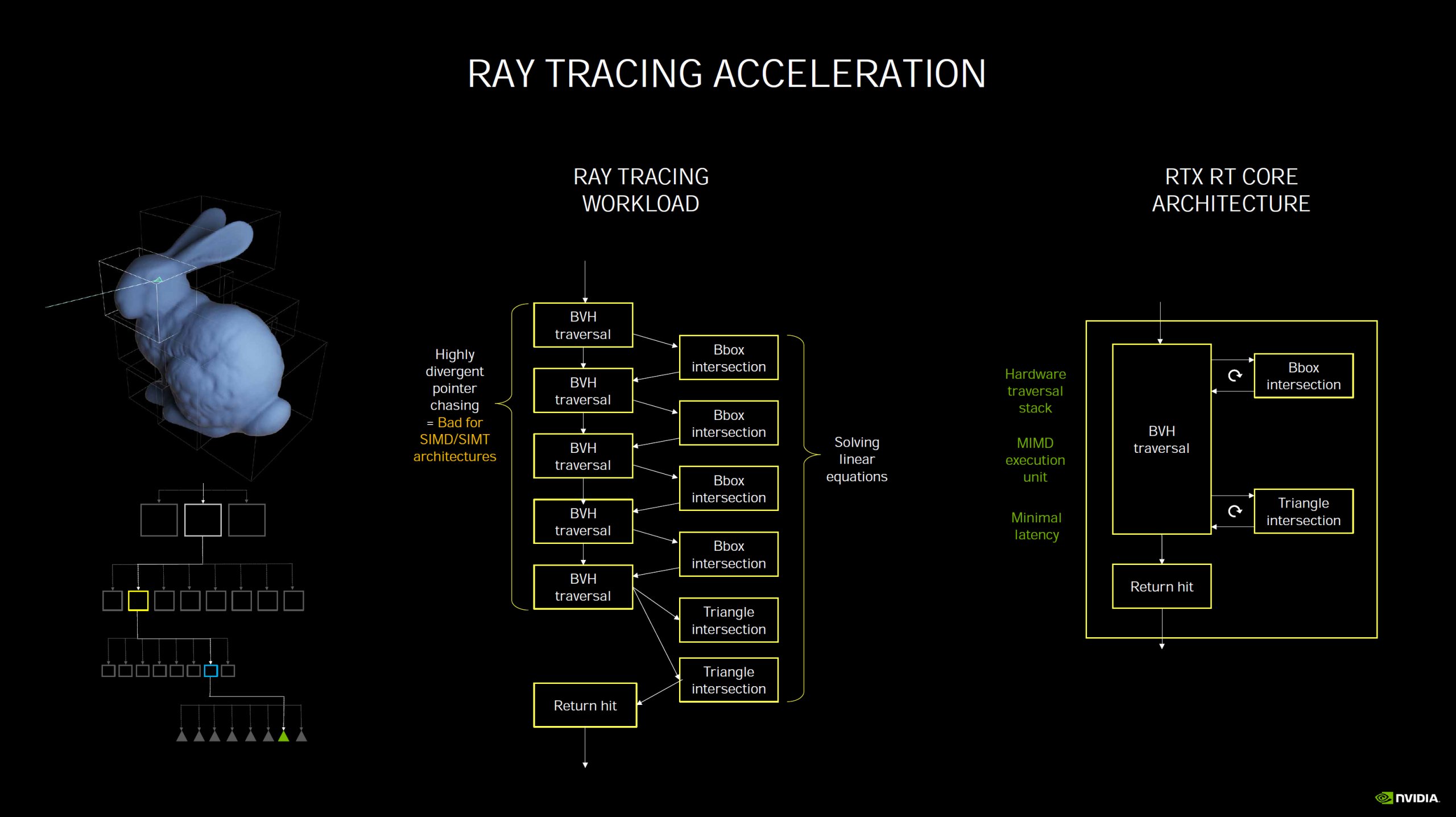
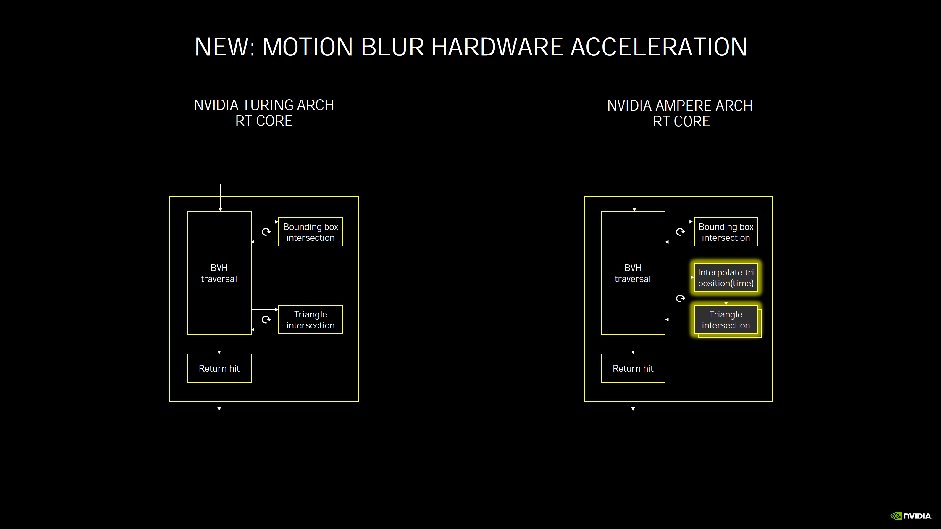



















Kommentieren