












GTX vs. RTX in einem Nicht-RTX-Spiel
Wie bereits auf der vorherigen Seite angespoilert, lasse ich nun eine GeForce GTX 1080 Ti und eine in etwa gleichschnelle GeForce RTX 2070 Super auf Tom Clancy’s Ghost Recon Breakpoint los. Beide Karten schaffen ohne aktiviertes RTX Voice 71 bzw. 72 FPS als Mittelwert, es herrscht also faktisch Gleichstand, wenn man auf Ultra-HD und dem Preset „Hoch“ spielt. Die Speicherauslastung liegt knapp über 6 GB, lässt also auch der GeForce RTX 2080 noch genügend Raum für die ca. 600 MB, die RTX Voice benötigt. Diesen Wert sollte man bei Benchmarks unbedingt mit einkalkulieren, um keine verzerrten Werte zu erhalten.
Jetzt wird es wirklich spannend: CUDA- gegen Tensor-Kerne und die Frage, welchen Vorteil sich die RTX-Karte verschaffen kann (oder vielleicht auch nicht)! Es ist knapp, extrem knapp, denn am Ende liegen beide Karte in etwa auch gleichauf. Doch wie kann das sein, wenn RTX Voice durch die Nutzung der externen Tensor-Kerne die eigentlicher Shader gar nicht belastet?
NVIDIAs Nullsummenspiel als Ursache für den faktischen Gleichstand
Jetzt kann man sich natürlich wundern, oder aber einfach mal logisch weiterdenken. Um das Folgende zu verstehen, muss ich dann doch noch einmal kurz abschweifen und auf wichtige Basics zurückkommen. Denn wir müssen uns jetzt über den Begriff Total Board Power (TBP) klar werden. Das ist alles ja noch noch recht einfach an allen Zuführungen nachzumessen, aber was NVIDIA und AMD komplett unterscheidet, ist die Kontroll- und Regelwut bei NVIDIAs aktuellen Grafikkarten, bei denen das jeweilige Power Target (Default Power Limit, Werksvorgabe) und das maximale Power Limit (Max Power Limit, Absolutwert) in der Firmware fest hinterlegt sind.

Im Gegensatz zu AMD überwacht Nvidia nämlich alle 12-Volt-Eingänge penibel mittels eines speziellen Monitoring-Chips, der sowohl die Spannung hinter und vor dem Shunt (sehr niederohmiger Widerstand) misst und somit auch den Spannungsabfall längs über diesem Shunt auswertet (daraus errechnet man den Stromfluss). Da in jeder 12-Volt-Zuleitung solch ein Shunt sitzt, kann somit die exakte Leistungsaufnahme des Boards bei 12 Volt gemessen und auch für die interne Begrenzung der Leistungsaufnahme zugrunde gelegt werden. Wir sehen links einen Shunt mit Längsspule zur Eingangsglättung und rechts einen NCP45491 von On Semi fürs Monitoring der Spannungen und Ströme.


Genau dieser hier ermittelte Wert wird auch in der Praxis nie überschritten (werden können), dafür sorgt die sehr aufmerksame und schnell regelnde Firmware. Was viele nämlich nicht bedenken: in diese Berechnung fließen auch Lüfter, RGB-Flutlicht, Mikrocontroller und Displays mit ein. Je bunter und schriller so ein Gaming-Protz daherkommt, umso weniger Leistung steht dann der GPU zur Verfügung! Und jetzt kommt Papa Turing und muss auch noch die zwei Kleininder RT und Tensor füttern! Bei AMDs Radeon-Karten gibt es eine derartige Limitierung bisher übrigens nicht. Das kann man jetzt sehen wie man möchte, aber es lässt zumindest mehr Freiraum.
Hätte NVIDIA die ca. 35 bis 40 Watt, die man z.B. für die maximale Belastung der Tensor- und RT-Kerne veranschlagen könnte, nicht so restriktiv mit im Monitoring eingepreist, könnten die Karten bei Volllast auf CUDA-, Tensor- und RT-Kernen natürlich deutlicher profitieren! Leider erfolgt die Spannungsversorgung der beiden weiteren Rechenwerke über eine gemeinsame Leitung (VDDC) zusammen mit den CUDA-Cores und liegt auch hinter den überwachten Zuführungen.
Fazit und Zusammenfassung
Um einen echten Benefit aus einer wirklich zusätzlichen Rechenleistung zu erzielen, hätte Nvidia die Versorgung entkoppeln und mit eigenen Spannungswandlern realisieren müssen, die man noch vor das Monitoring gepackt hätte. Oder man hätte zumindest per Firmware das Power Limit um den benötigten Wert angehoben. Beides ist aber nicht der Fall und so fällt die Erfindung des Perpetuum Mobile heute leider aus. Denn der faktische Performance-Gleichstand bei den CUDA -vs. Tensor-Kernen basiert auf der Tatsache, dass die Leistungsaufnahme bei beiden Karten gleich bleibt und sie sich bei der GeForce RTX 2070 Super (im Beispiel oben) lediglich verschiebt. Dass die GeForce RTX 2070 Super dabei zumindest einen kleinen Tick schneller ist als die GeForce GTX 1080 Ti, liegt wohl auch an der etwas höheren Effizienz der Tensor-Kerne.
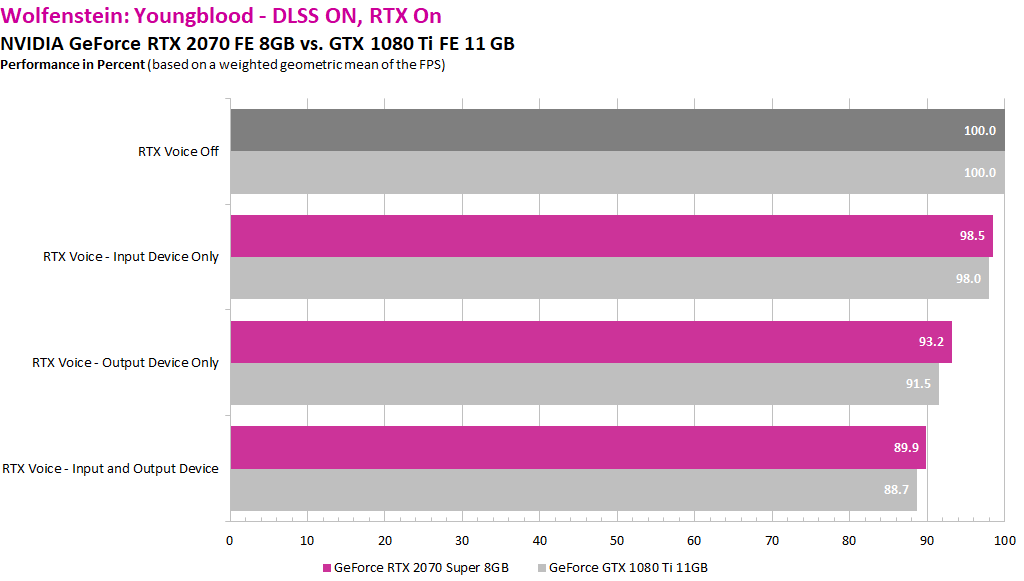
Jetzt kann man sich natürlich fragen, warum bei den getesten Spielen wie Control oder Wolfenstein: Youngblood der Effekt nicht so deutlich sichtbar wurde, vor allem bei der kleinen GeForce RTX 2060 und deaktiviertem RTX Voice. Hier bliebe nur die Mutmaßung, dass ein vorhandenes Fenster bis zum maximalen Power Limit die Tensor-Cores abfedern kann oder dass die Tensor-Kerne in solchen Spielen eh immer eine gewisse Last samt dazugehöriger Leistungsaufnahme generieren, die dann den CUDA-Kernen generell fehlt, auch ohne RTX Voice. Hier müsste noch einmal länger und im Detail nachgetestet werden, wobei man sich fragen muss, ob es sich für so ein Beta-Programm vom Aufwand her überhaupt lohnt.
















Kommentieren