













Bei einigen Anwendungen und Spielen sind wir auf Leistungstrends gestoßen, die nicht mit unseren Erwartungen einhergingen. Wenn man bedenkt, dass Skylake X sowohl einen Geschwindigkeitsvorteil durch höhere Taktraten, als auch neue architektonische Eigenschaften mitbringt, wie etwa die neugestalteten Caches oder die 2D-Mesh-Topologie, hätten wir nicht erwartet, dass Broadwell-E-Modelle ihre Nachfolger in irgendeinem Szenario überhaupt hätten übertrumpfen könnten. Doch genau das geschieht in einigen Fällen. Wir haben Intel diesbezüglich kontaktiert und ist die Antwort unsere Nachfrage:
…we have noticed that there are a handful of applications where the Broadwell-E part is comparable or faster than the Skylake-X part. These inversions are a result of the “mesh” architecture on Skylake-X vs. the “ring” architecture of Broadwell-E.
Every new architecture implementation requires architects to make engineering tradeoffs with the goal of improving the overall performance of the platform. The “mesh” architecture on Skylake-X is no different.
While these tradeoffs impact a handful of applications; overall, the new Skylake-X processors offer excellent IPC execution and significant performance gains across a variety of applications.
Wir beschäftigten uns nun gründlich mit Intels neuer Mesh-Architektur, zumindest mit den wenigen Details, die Intel Anfang vergangener Woche zur Verfügung stellte. An dieser Stelle bieten wird daher vorab noch kurz eine inhaltliche Übersicht dazu, bevor wir zu unseren eigentlichen Tests zurückkehren.
Der Hintergrund
Prozessor-Interconnects sind Leitungen, um Daten zwischen den Schlüsselkomponenten im Inneren eines Prozessors, also den CPU-Kernen, den Caches, sowie dem PCIe- und Speicher-Controller zu bewegen. Dieser Grundgedanke beim Prozessordesign berührt nahezu jede interne Komponente und hat damit gleichermaßen auch großen Einfluss auf die Latenz, die in vielen Fällen mit der Leistung korreliert. Genauso beeinflusst es die Leistungsaufnahme und spiegelt sich damit auch (in Ansätzen) in der ausgewiesenen TDP wieder.
Die Interconnects von Intel und AMD debütierten vor mehr als zehn Jahren. Intels Ring-Bus wurde beispielsweise 2007 mit Nehalem vorgestellt, AMDs HyperTransport stammt aus dem Jahr 2001. Beide Strukturen entwickelten sich, doch die schnell wachsende Kernzahl, die zunehmenden Caches, die steigende Performance und der I/O-Durchsatz, wurden zur permanent steigendenden Belastung der Interconnects. Es gibt zwar eine Unzahl von Technologien, um die Leistung der bestehenden Interconnects zu erhöhen, wie etwa ein verbessertes Scheduling und Routing, doch damit wird zumeist eine Erhöhung der Frequenz und somit auch der Spannung notwendig, um überhaupt noch größere Leistungszuwächse zu realisieren.
Intels bidirektionaler Ring-Bus – oben in Rot auf einem Broadwell-LCC-Die (Low Core Count) dargestellt – dient als ein gutes Beispiel für die Herausforderungen. Die Daten bewegen sich auf einem recht umständlichen Weg, um zu den Kernen, dem Cache und den I/O-Komponenten zu gelangen. Die Latenz wächst dann als logische Folge mit einer wachsenden Anzahl an Kernen. Das zweite Bild zeigt ein Broadwell-HCC-Die (High Core Count) mit 24 Kernen. Ein Aneinanderreihen aller Kerne in einem monolithischen Bus, führt zu übermäßigen Einbußen – also teilte Intel das größere Die einfach in zwei separate Ring-Busse. Das erhöht nicht nur die Komplexität beim Scheduling, sondern die gepufferten Switches, die die Kommunikation zwischen den beiden Ringen erleichtern, sorgen zusätzlich für eine Verzögerung von fünf Zyklen. Das begrenzt die Skalierbarkeit enorm.
Auch AMDs HyperTransport war letztendlich über seine Belastungsgrenzen hinausgewachsen, sodass der Hersteller mit der Zen-Architektur das neue Infinity Fabric präsentierte. Das Design ist angelehnt an zwei Quadcore-Prozessoren (CCX), die über eine 256 Bit breite, bidirektionale Querverbindung miteinander kommunizieren, die gleichermaßen für Northbrigde- und PCIe-Verkehr zuständig ist. Sie teilen auch den Speicher-Controller. Die Verbindung über Infinity Fabric zu dem nächsten Core Complex (CCX) mit seinen vier Kernen, führt jedoch zu einer erhöhten Latenz bei der Kommunikation. Ein ausführlicher Blick auf das Design und die Latenzen findet sich in unserem Test des Ryzen 5 1600X.
Wir konnten auch feststellen, dass die Erhöhung des Speichertakts zu Verbesserungen bei der Charakteristik der Latenzen von Infinity Fabric führen kann, was sehr wahrscheinlich einer der wesentlichen Gründe ist, warum sich die Leistung der Ryzen mit einem schnelleren Speicher verbessert, der zu höheren Datentransferraten fähig ist.
AMD drängt auf Software- und Plattform-Optimierungen, mit denen einige der Auffälligkeiten bei der Performance – die wir in unseren Tests nachvollziehen konnten – aus der Welt geschafft werden könnten. Und bei dem, was wir gesehen haben, hat dies in der Tat funktioniert! AMDs Bemühungen und eine unaufhörliche Folge von BIOS-, Chipsatz- und Software-Updates sorgen mittlerweile für deutlich bessere Leistungen als die, die wir noch in unserem ersten Ryzen-7-Test messen konnten. Und AMDs Arbeit geht sicher auch weiter.
Nun sieht sich Intel den gleichen Herausforderungen gegenübergestellt und wir sind gespannt, wie schnell der blaue Riese diesbezüglich reagieren kann und wird.
Was für ein Mesh!
Intels neue Mesh-Architektur feierte ihren Start in den Knights-Landing-Chips. Das Mesh besteht aus Zeilen und Spalten von Interconnects, die Kerne, Caches und I/O-Controller miteinander verbinden. Wie man sehen kann, sind die gepufferten Switches, die für niedrige Latenzen absolut tödlich sind, einfach verschwunden. Die Möglichkeit, Informationen durch die Kerne „durchreichen“ zu können, erlaubt ein wesentlich komplexeres – und angeblich effizienteres – Routing unter den Komponenten. Intel behauptet zudem, dass sein 2D-Mesh eine niedrigere Frequenz und Spannung als der Ring-Bus benötigt, dafür aber eine höhere Bandbreite und eine niedrigere Latenz bewerkstelligt. Beides überprüfen wir natürlich gleich noch.
Intel hat die DDR4-Controller an die linke und rechte Seite des 18-Kern-HCC-Dies (High Core Count) verschoben – ähnlich wie beim Design von Knights Landing. Beim Ring-Bus wurden sie üblicherweise noch an der Unterseite untergebracht. Das Die-Foto von Skylake X deutet darüber hinaus sechs weitere Speicher-Controller an (zweite Zeile von unten, in der linken und der rechten Spalte). Es scheint also, dass Intel zwei der Controller standardmäßig deaktiviert hat. Vermutlich nutzt Intel für den Core i9-7900X das kleinere LCC-Die (Low Core Count), offiziell wurden dazu jedoch keine Details preisgegeben.
Die Dinge werden „meshy“
Intel hat sein 2D-Mesh entwickelt, um auch die Skalierbarkeit zu verbessern – doch wie der Hersteller andeutet, mit gewissen Abstrichen. Wir haben SiSoft Sandra’s Processor Multi-Core Efficiency Test herangezogen, um die Inter-Core, Inter-Module- und Inter-Package-Latenz zu messen. Der Benchmark bietet Multi-Threaded, Multi-Core-Only- und Single-Threaded-Tests. Für unseren Test haben wir den Multi-Threaded-Test mit der „Best Pair Match“-Einstellung (geringste Latenz) verwendet.
Mit dem Test kann die Leistung zwischen den Kernen mit allen möglichen Thread-Paarungen gemessen werden. Für den Intel Core i9-7900X bedeutete das am Ende 189 verschiedene Ergebnisse, was natürlich in der Darstellung zu unübersichtlich wird. Wir haben daher auf einen Daten-Parser zurückgegriffen, um die Messergebnisse in Durchschnittswerte zu überführen.
|
Prozessor |
Intra-Core Latency |
Core-To-Core Latency |
Core-To-Core Average Latency |
Average Transfer Bandwidth |
|---|---|---|---|---|
|
Core i9-7900X |
14.5 – 16ns |
69.3 – 82.3ns |
75.56ns |
83.21 GB/s |
|
Core i9-7900X @ 3200 MT/s |
16 – 16.1ns |
76.8 – 91.3ns |
83.93ns |
87.31 GB/s |
|
Core i7-6950X |
13.5 – 15.4ns |
54.5 – 70.3ns |
64.64ns |
65.67 GB/s |
|
Core i7-7700K |
14.7 – 14.9ns |
36.8 – 45.1ns |
42.63ns |
35.84 GB/s |
|
Core i7-6700K |
16 – 16.4ns |
41.7 – 51.4ns |
46.71ns |
32.38 GB/s |
Die Intra-Core-Messung drückt die Latenzen zwischen Threads in Zahlen aus, die mit einem physischen Kern abgearbeitet werden, während die Core-to-Core-Zahl die Thread-zu-Thread-Latenz zwischen zwei physischen Kernen widerspiegelt. Der i9-7900X ist an dieser Stelle vergleichbar mit dem i7-6950X, der ebenfalls zehn CPU-Kerne besitzt. Als Referenz haben wir aber auch die Vierkern-Pendants hinzugefügt.
Zwischen den beiden Chips konnten wir eine etwas höhere Intra-Core-Latenz feststellen und einen Durchschnittswert von 10,92 ns ermitteln. Abgesehen von einer leicht erhöhten Latenz, konnten wir beim Core i9-7900X eine ordentliche Steigerung der Bandbreite messen, die im Durchschnitt um 17,54 GB/s höher ausfiel – was einen satten Zuwachs von 26,7 Prozent bedeutet.
Wir generierten unseren ersten Satz an Ergebnissen mit DDR4-2666-RAM und wiederholten die Messungen mit DDR4-3200-Arbeitsspeicher. Wir erhielten in allen Bereichen höhere Latenzen, konnten aber auch eine höhere Bandbreite messen. Wir befürchten, dass diese Ergebnisse nur vorläufig sind und werden zu einem späteren Zeitpunkt weitere Latenz- und Gaming-Tests mit unterschiedlichen Speichertransferraten und -timings durchführen, um eine tiefgründigere Analyse liefern zu können.
|
Processor |
Intra-CCX Core-to-Core Latency |
Cross-CCX Core-to-Core Latency |
Cross-CCX Average Latency |
Average Transfer Bandwidth |
|---|---|---|---|---|
|
Ryzen 7 1800X |
40.5 – 82.8ns |
120.9 – 126.2ns |
122.96ns |
48.1 GB/s |
|
Ryzen 5 1600X |
40.6 – 82.8ns |
121.5 – 128.2ns |
123.48ns |
43.88 GB/s |
Die Architektur von AMDs Ryzen-Prozessoren unterscheidet sich an dieser Stelle erheblich, was natürlich zu anderen Messergebnissen führt. Die Intra-Core-Latency-Messung repräsentiert die Kommunikation zwischen zwei logischen Threads auf dem gleichen Kern, die Speichergeschwindigkeit spielt dabei keine Rolle.
Die Intra-CCX-Messungen bei AMD quantifizieren die Latenzen zwischen Threads im selben CCX-Modul, aber auf verschiedenen Kernen. In der Vergangenheit beobachteten wir an dieser Stelle leichte Varianzen, doch auch die Intra-CCX-Latenz wird ebenfalls kaum von der Speichergeschwindigkeit beeinflusst. Bei der Cross-CCX-Latenz konnten wir hingegen einen Rückgang um 50 Prozent messen. Wie das geht, ist einfach erklärt. Diese Art der Latenz entsteht, wenn Threads auf zwei unterschiedlichen CCX-Modulen verortet sind. Wenn nun aber die Datenraten des Speichers verbessert werden, indem von DDR4-1333- auf DDR4-3200-RAM gewechselt wird, sinken auch diese Latenzen als logische Folge.
Strukturelle Bandbreite
Wir haben auch unsere Testergebnisse hinsichtlich der strukturellen Bandbreite aufgezeichnet. An dieser Stelle bietet der Core i9-7900X einen erheblichen Vorteil gegenüber seinem Broadwell-E-Vorgänger.
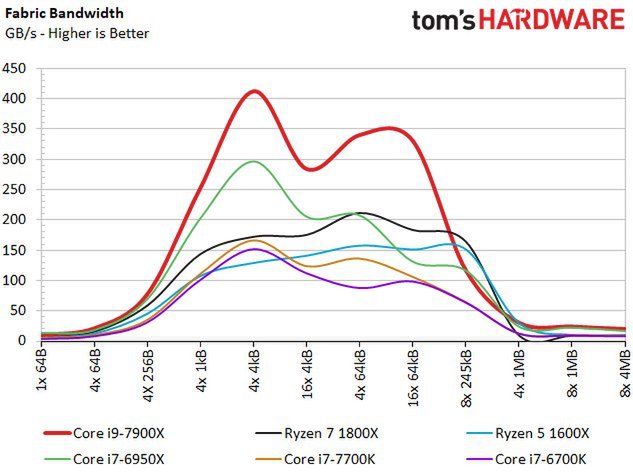
Laut Intel soll die Struktur zudem mit einer niedrigeren Frequenz und Spannung arbeiten, was darauf hindeutet, dass der Hersteller die Breite des Busses erhöht hat. AMDs Ryzen überflügelt Intels Vierkerner, bietet im Durchschnitt aber eine geringere Bandbreite als Intels Zehnkern-Modelle.
- 1 - Einführung und Übersicht
- 2 - Intels Fabric - Mesh statt Ringbus
- 3 - Cache und Latenzen, IPC, AVX und Kryptographie
- 4 - Chipsatz, Testsystem und -methoden
- 5 - Problemanalyse mit Civilization VI und VRMark
- 6 - AotS Escalation, Battlefield 1, Deus Ex: Mankind
- 7 - GTA V, Hitman, Shadow of Mordor
- 8 - Project Cars, Rise of the Tomb Raider, The Division
- 9 - Workstation und HPC
- 10 - Leistungsaufnahme und Übertaktung
- 11 - Temperaturverläufe und thermische Probleme
- 12 - Zusammenfassung und Fazit
















Kommentieren