











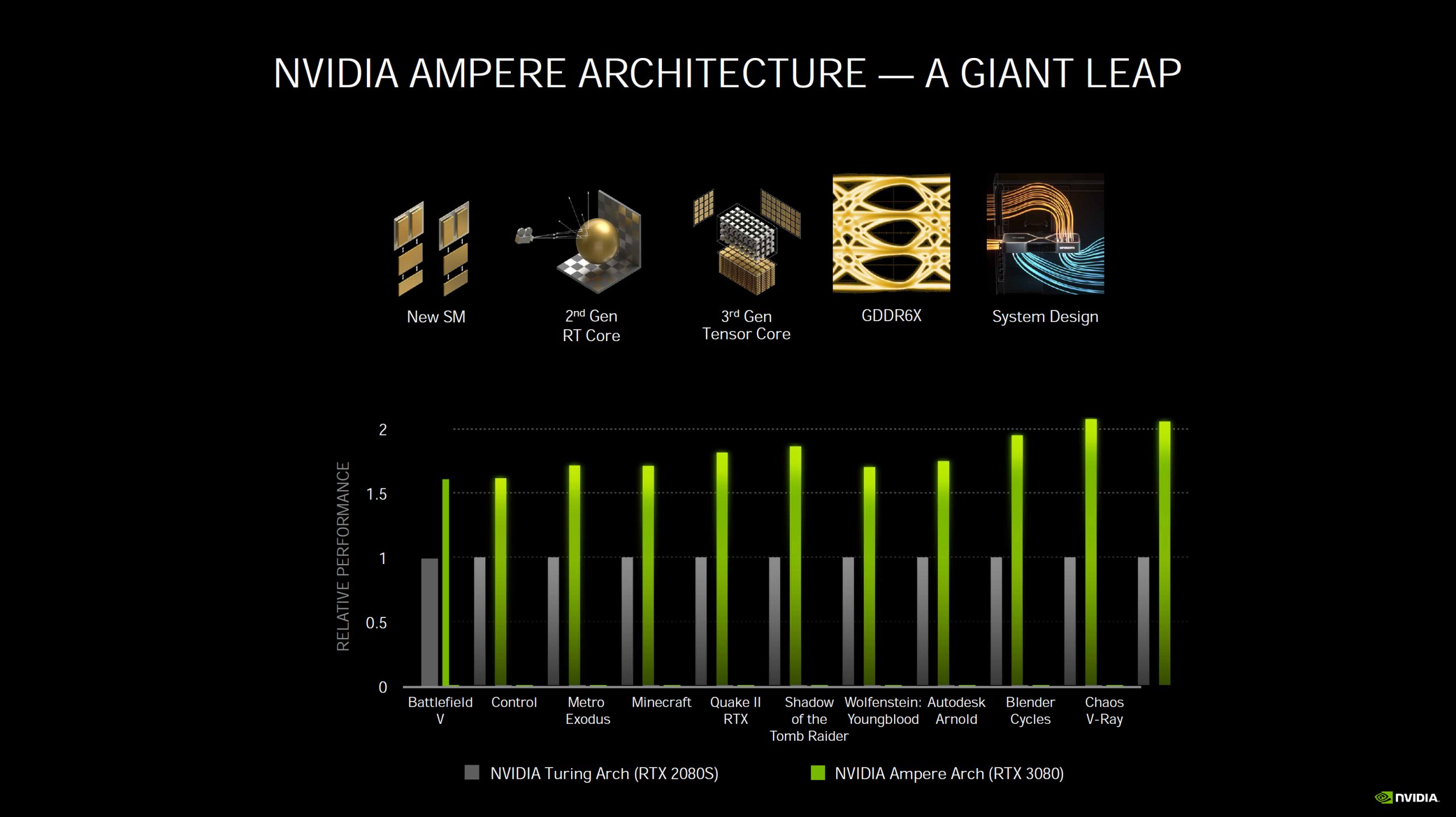
The GeForce RTX 3090 as the upcoming top dog and the RTX 3080 as the current flagship rely on the GA102 processor, which does pretty much everything differently than before. With the stated 10,496 CUDA cores, at least on paper (but not only there), an incredible number of ALUs are banged in, which surely shocks not only AMD at first sight. But that this really smart trick is supposed to have been achieved with the help of Samsung’s rather granular 8-nm node, however, requires a closer look. But how do you achieve such a theoretical computing power of an incredible 35.7 FP32-TFLOPS?

New SM and lots of floating point
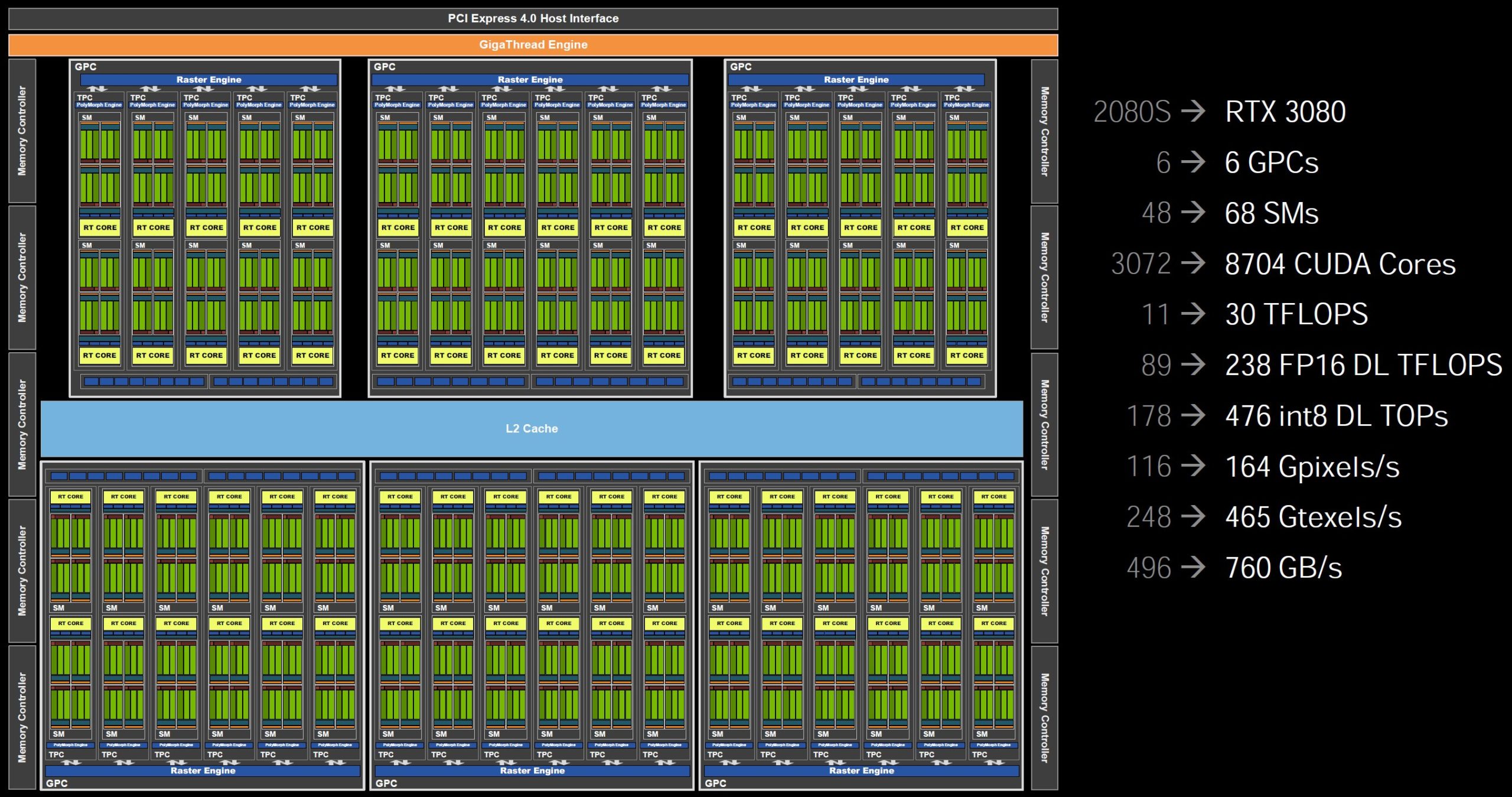
The trick lies in Ampere’s Streaming Multiprocessors (SM), which have been fundamentally redesigned. The base might be similar to Turing’s, but there are important and most important things changed, which I will discuss in a moment. Of course this also applies to the RT and Tensor cores. Let’s have a look at the GeForce RTX 3080’s scheme below. As usual, the GPU itself consists of several GPC (Graphics Processor Cluster). There we find the SM (Streaming Multiprocessors) with the known computing units, the TPC (Texture Processing Clusters) which contain the texture units, the usual geometry units and – this is new – also the ROPs.
Up to and including Turing the ROPs still hung on the memory interface, so their number depended on the width of the interface. But now the ROPs are located directly in the GPC which has 2 ROP partitions with 8 ROPs each. This also significantly increases the number of ROPs compared to the previous counting method. But since there are two ROP partitions per GPC and the full chip has seven GPCs, this results in a maximum of 14 partitions and thus 112 ROPs instead of 96. However, a GPC is disabled on the GeForce RTX 3080 in comparison to the maximum, which also reduces the number of ROPs accordingly.
The SM have made a really big transformation, which ultimately results in the increased performance. A single SM at Turing still consisted of 64 FP32-ALUs for floating point calculations and 64 INT32-ALUs for integer calculations, divided into four blocks of 16 FP32 and 16 INT32-ALUs each. The trick here is that the FP and INT ALUs can be addressed simultaneously. The 64 pure FP32-ALUs per SM are still available, but the 64 INT32-ALUs are increased by 64 more, which can still perform floating point and integer calculations, with one restriction: this is no longer possible in parallel. The division into 4 blocks each remains, but with a separate data path.

If you now summarize this, you will notice that a Turing SM could execute up to 64 FP32 and 64 INT32 calculations simultaneously. With amps, on the other hand, ideally even up to 128 FP32 calculations can be carried out exclusively, which corresponds to a de facto doubling. Otherwise it remains in “mixed mode” with up to 64 FP32 and 64 INT32 calculations and similar computing power. And now we also have the reason for doubling the theoretical FP32 computational power at ampere compared to Turing.
The fact that Nvidia now writes twice the number of FP32 ALUs as many CUDA cores is understandable, but only correct if you really only do FP32 calculations. So in scenarios where floating point calculations are needed, Ampere will be much faster than Turing, logically. But if both floating-point and integer numbers have to be calculated, the additional performance drops significantly, depending on the proportion and the optimal distribution of tasks (which is a real challenge) to the individual SM. Nevertheless Ampere is still faster than Turing, even in the worst case.
Very important for an optimal distribution of tasks and thus also for a target-oriented workload and the avoidance of unnecessary idle time are the areas of shared memory and L1 cache in every SM, which work almost twice as fast. The L1 cache of the GeForce RTX 3080 also grows from 96 to 128 KB and can also increase its bandwidth once again to 219 GB/s. The fast L2-Cache of the RTX 3080 sank in relation to Turing from 6 to 5 MB, for the RTX 3090 there are no statements, but it should be identical.
Summary of the structure of the GeForce RTX 3090, 3080 and 3070
The GA102 has 7 GPCs with 12 SMs each, which corresponds to 10,752 CUDA cores. However, in the GeForce RTX 3090, two SM are deactivated, resulting in 10,496 ALUs. In contrast, the GeForce RTX 3080 with the same GA102 has an entire GPC turned off, and only four out of six GPCs use the full 12 SMs, while the two are reduced to 10 SMs. If you now extrapolate the SMs, the result is 68 and thus 8,704 CUDA cores. The GeForce RTX 3070 with GA104-GPU has only 4 GPCs, by the way, of which 48 SMs should also be switched off, resulting in 5,888 CUDA cores that were communicated.


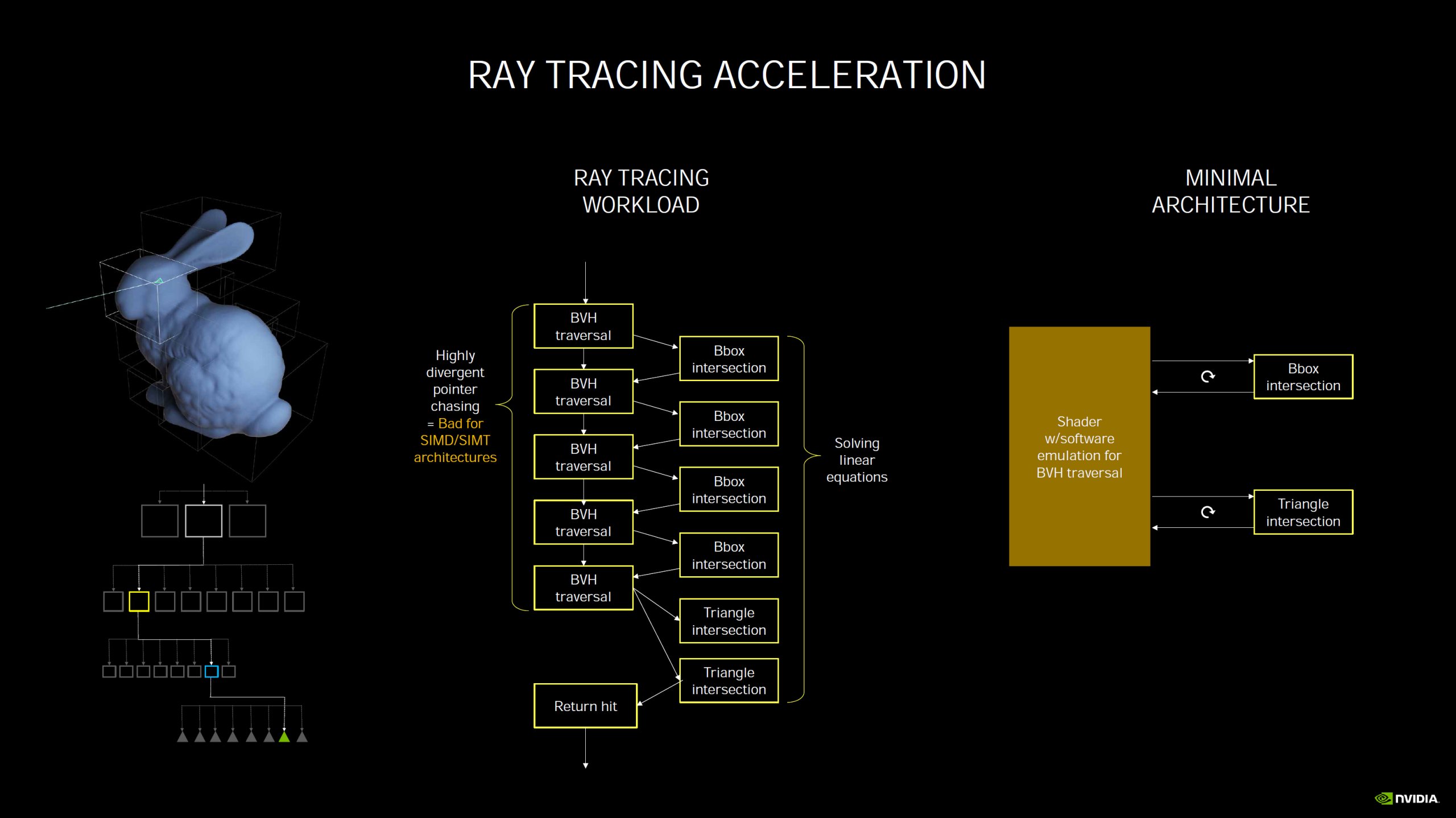
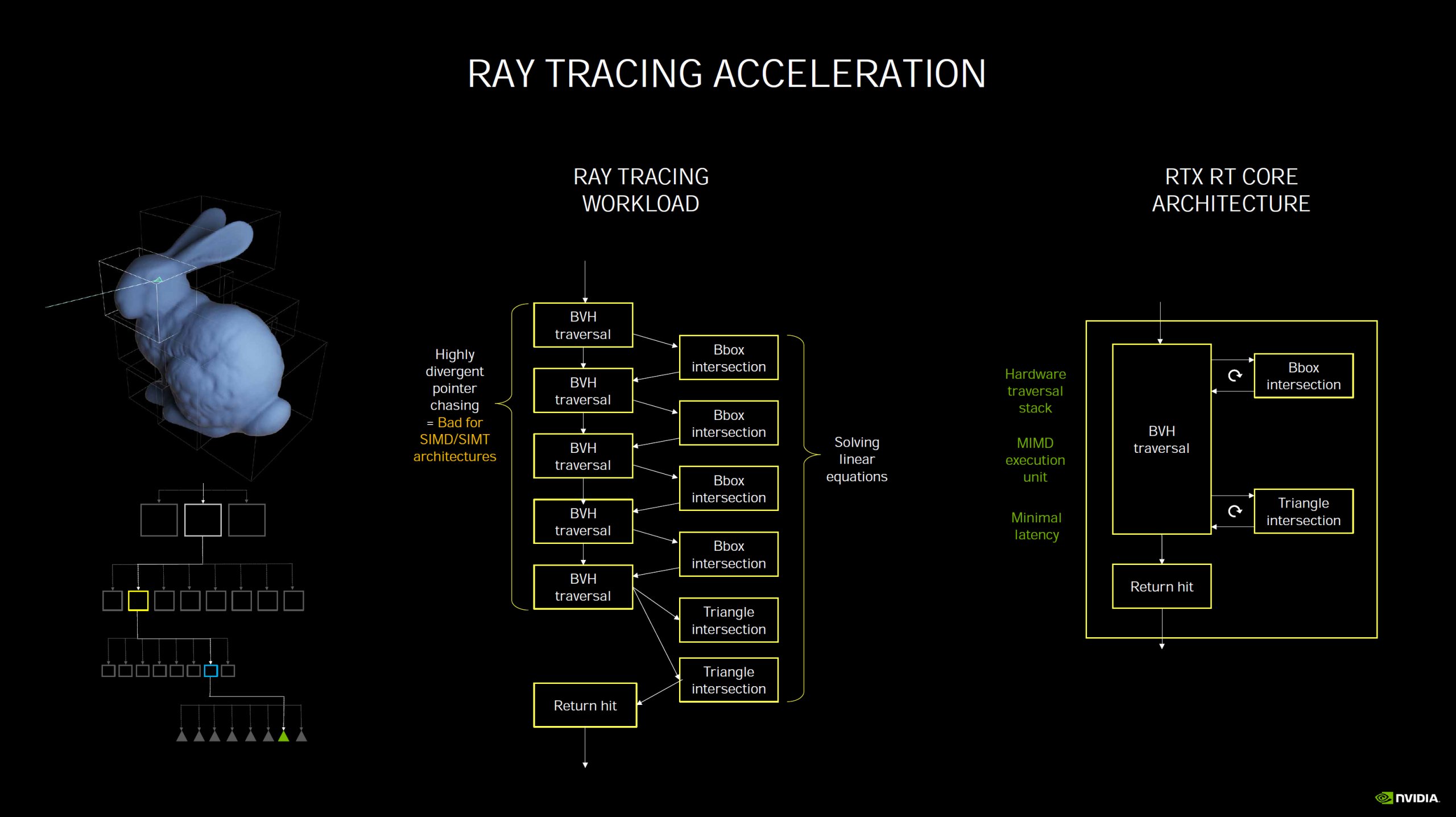
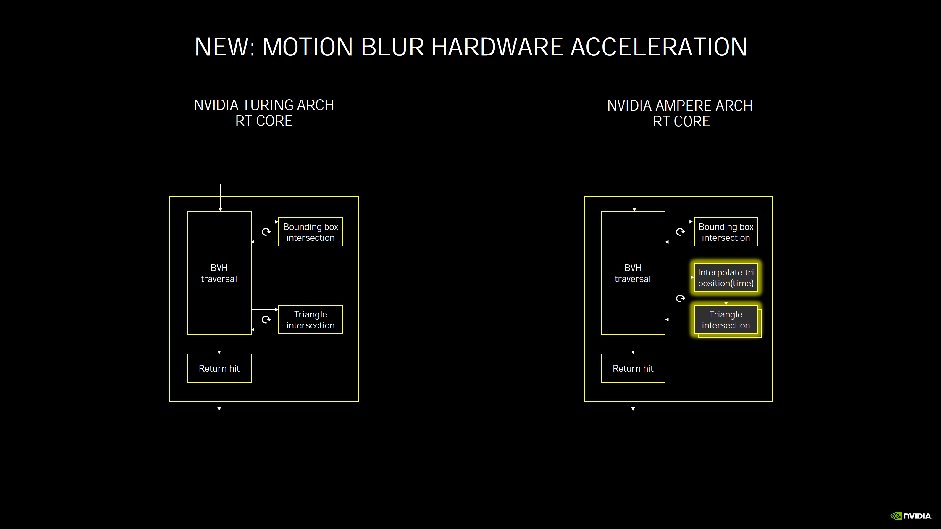



















Kommentieren