













In some applications and games, we've encountered performance trends that didn't match our expectations. Considering that Skylake X has both a speed advantage through higher clock speeds and new architectural features, such as the redesigned caches or the 2D mesh topology, we wouldn't have expected Broadwell E models to Successors in any scenario could have trumped at all. But that is precisely what is happening in some cases. We have contacted Intel about this and the answer is our request:
… We have noticed that there are a handful of applications where the Broadwell-E part is comparable or faster than the Skylake-X part. These inversions are a result of the "mesh" architecture on Skylake-X vs. the "ring" architecture of Broadwell-E.
Every new architecture implementation requires architects to make engineering tradeoffs with the goal of improving the overall performance of the platform. The "mesh" architecture on Skylake-X is no different.
While these tradeoffs impact a handful of applications; overall, the new Skylake-X processors offer excellent IPC execution and significant performance gains across a variety of applications.
We've been looking at Intel's new mesh architecture, at least with the few details Intel provided early last week. At this point, therefore, we will offer a brief overview of the content before we return to our actual tests.
The background
Processor interconnects are lines to move data between the key components inside a processor, i.e. the CPU cores, caches, and the PCIe and memory controllers. This basic idea of processor design touches almost every internal component and thus also has a great influence on latency, which in many cases correlates with performance. In the same way, it influences the power consumption and is thus also reflected (in approaches) in the designated TDP.
Intel and AMD's interconnects debuted more than a decade ago. Intel's ring bus, for example, was introduced with Nehalem in 2007, while AMD's HyperTransport dates back to 2001. Both structures developed, but the rapidly growing core number, increasing caches, increasing performance and I/O throughput became the ever-increasing burden on interconnects. Although there are a myriad of technologies to increase the performance of existing interconnects, such as improved scheduling and routing, this usually requires an increase in frequency and thus also the voltage in order to even greater the number of performance gains.
Intel's bi-directional ring bus – shown at the top of red on a Broadwell LCC (Low Core Count) die – serves as a good example of the challenges. The data moves in a rather cumbersome way to get to the cores, cache, and I/O components. Latency then grows as a logical consequence with a growing number of cores. The second image shows a Broadwell HCC (High Core Count) die with 24 cores. A string of all the cores in a monolithic bus leads to excessive losses – so Intel simply divided the larger Die into two separate ring buses. This not only increases the complexity of scheduling, but the buffered switches, which facilitate communication between the two rings, also cause a delay of five cycles. This limits scalability enormously.
AMD's HyperTransport, too, eventually had grown beyond its load limits, so the manufacturer presented the new Infinity Fabric with the Zen architecture. The design is based on two quad-core processors (CCX) that communicate with each other via a 256-bit, bi-directional cross-connection that is equally responsible for Northbrigde and PCIe traffic. They also share the storage controller. The connection via Infinity Fabric to the next Core Complex (CCX) with its four cores, however, leads to increased latency in communication. A detailed look at the design and the latency can be found in our test of the Ryzen 5 1600X.
We also found that increasing the memory clock can lead to improvements in the characteristics of Infinity Fabric latency, which is most likely one of the main reasons why the performance of the Ryzen is improved with faster memory. capable of higher data transfer rates.
AMD is pushing for software and platform optimizations that could eliminate some of the performance issues we've been able to understand in our tests. And in what we have seen, this has indeed worked! AMD's efforts and an incessant succession of BIOS, chipset and software updates are now doing much better than the ones we measured in our first Ryzen 7 test. And AMD's work certainly continues.
Now Intel faces the same challenges and we are curious to see how quickly the blue giant can and will respond to this.
What a mesh!
Intel's new mesh architecture celebrated its launch in the Knights Landing chips. The mesh consists of rows and columns of interconnects that connect cores, caches, and I/O controllers. As you can see, the buffered switches, which are absolutely deadly for low latency, have simply disappeared. The ability to "pass" information through the cores allows for much more complex – and supposedly more efficient – routing among the components. Intel also claims that its 2D mesh requires a lower frequency and voltage than the ring bus, but does it achieve higher bandwidth and lower latency. Of course, we are still reviewing both.
Intel has moved the DDR4 controllers to the left and right sides of the 18-core HcC (High Core Count) ( similar to the Design of Knights Landing). On the ring bus, they were usually still housed at the bottom. The Skylake X Die photo also indicates six more memory controllers (second row from below, in the left and right columns). So it appears that Intel disabled two of the controllers by default. Intel probably uses the smaller LCC (Low Core Count) for the Core i9-7900X, but no details have been officially disclosed.
Things become "meshy"
Intel has developed its 2D mesh to improve scalability as well – but, as the manufacturer suggests, with some compromises. We used SiSoft Sandra's Processor Multi-Core Efficiency Test to measure inter-core, inter-module, and inter-package latency. The benchmark provides multi-threaded, multi-core- and single-threaded testing. For our test we used the multi-threaded test with the "Best Pair Match" setting (lowest latency).
The test can be used to measure performance between cores with all possible thread pairings. For the Intel Core i9-7900X, this meant 189 different results in the end, which of course becomes too confusing in the presentation. We have therefore used a data parser to convert the measurement results into average values.
|
Processor |
Intra-Core Latency |
Core-To-Core Latency |
Core-To-Core Average Latency |
Average Transfer Bandwidth |
|---|---|---|---|---|
|
Core i9-7900X |
14.5 – 16ns |
69.3 – 82.3ns |
75.56ns |
83.21 GB/s |
|
Core i9-7900X x 3200 MT/s |
16 – 16.1ns |
76.8 – 91.3ns |
83.93ns |
87.31 GB/s |
|
Core i7-6950X |
13.5 – 15.4ns |
54.5 – 70.3ns |
64.64ns |
65.67 GB/s |
|
Core i7-7700K |
14.7 – 14.9ns |
36.8 – 45.1ns |
42.63ns |
35.84 GB/s |
|
Core i7-6700K |
16 – 4/4ns |
41.7 – 51.4ns |
46.71ns |
32.38 GB/s |
Intra-core measurement expresses the latency between threads in numbers processed with a physical core, while the core-to-core number reflects thread-to-thread latency between two physical cores. The i9-7900X is comparable at this point to the i7-6950X, which also has ten CPU cores. As a reference, however, we have also added the four-core counterparts.
Between the two chips, we were able to detect a slightly higher intra-core latency and an average value of 10.92 ns. Apart from a slightly increased latency, we were able to measure a decent increase in bandwidth for the Core i9-7900X, which was 17.54 GB/s higher on average – a whopping 26.7 percent increase.
We generated our first set of results with DDR4-2666 RAM and repeated the measurements with DDR4-3200 memory. We received higher latency in all areas, but were also able to measure a higher bandwidth. We fear that these results are only preliminary and will later perform further latency and gaming tests with different storage transfer rates and timings to provide a more in-depth analysis.
|
Processor |
Intra-CCX Core-to-Core Latency |
Cross-CCX Core-to-Core Latency |
Cross-CCX Average Latency |
Average Transfer Bandwidth |
|---|---|---|---|---|
|
Ryzen 7 1800X |
40.5 – 82.8ns |
120.9 – 126.2ns |
122.96ns |
48.1 GB/s |
|
Ryzen 5 1600X |
6/40 – 82.8ns |
121.5 – 128.2ns |
123.48ns |
43.88 GB/s |
The architecture of AMD's Ryzen processors differs significantly at this point, which of course leads to different measurement results. The intra-core latency measurement represents the communication between two logical threads on the same core, and the memory speed does not matter.
The intra-CCX measurements in AMD quantify the latency between threads in the same CCX module, but on different cores. In the past, we observed slight variances at this point, but intra-CCX latency is also hardly affected by the memory speed. In contrast, we were able to measure a 50 percent decrease in cross-CCX latency. How this can be done is simply explained. This type of latency occurs when threads are located on two different CCX modules. However, if the data rates of the memory are improved by switching from DDR4-1333- to DDR4-3200-RAM, these latencys also decrease as a logical consequence.
Structural bandwidth
We also recorded our test results in terms of structural bandwidth. At this point, the Core i9-7900X offers a significant advantage over its Broadwell E predecessor.
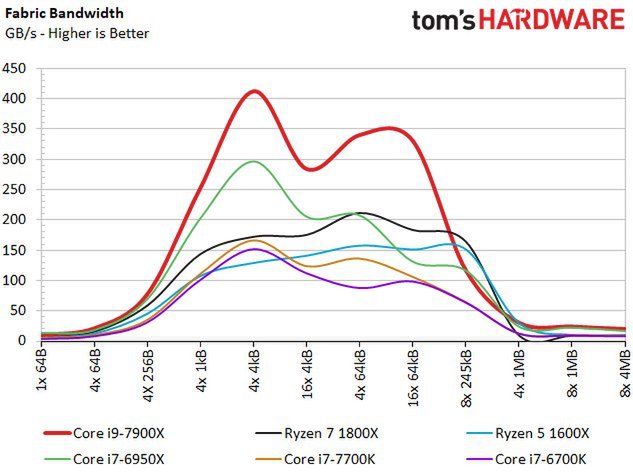
According to Intel, the structure is also expected to operate at a lower frequency and voltage, suggesting that the manufacturer has increased the width of the bus. AMD's Ryzen outperforms Intel's four-core, but on average offers less bandwidth than Intel's ten-core models.
- 1 - Einführung und Übersicht
- 2 - Intels Fabric - Mesh statt Ringbus
- 3 - Cache und Latenzen, IPC, AVX und Kryptographie
- 4 - Chipsatz, Testsystem und -methoden
- 5 - Problemanalyse mit Civilization VI und VRMark
- 6 - AotS Escalation, Battlefield 1, Deus Ex: Mankind
- 7 - GTA V, Hitman, Shadow of Mordor
- 8 - Project Cars, Rise of the Tomb Raider, The Division
- 9 - Workstation und HPC
- 10 - Leistungsaufnahme und Übertaktung
- 11 - Temperaturverläufe und thermische Probleme
- 12 - Zusammenfassung und Fazit

















Kommentieren