













Super Pi 32M and AIDA64
In order to make the effects of the different RAM and CPU configurations even more visible, I’m going to unleash a few benchmarks on the systems today that are new to me. I would like to start with the well-known competition benchmark SuperPi with the preset “32M”. In this benchmark, 32 million digits of the number Pi are calculated in 24 repetitions, whereby the smallest changes to CPU and RAM become visible in the result. The benchmark still takes several minutes with current hardware and the results are still often reproducible to a fraction of a second. The decisive factors here are the performance of a single CPU thread together with cache and RAM. Moreover, what matters here is not the throughput, but the latency of the RAM. Even though this benchmark performs better with Hyperthreading off, we left it on for consistency accross all our tests.
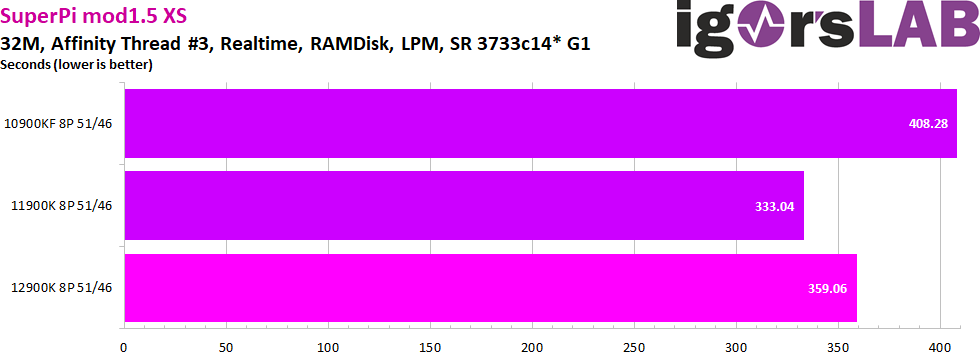
As expected, the Rocket Lake CPU is ahead of the Comet Lake CPU, due to its larger and more powerful cores. However, the fact that there is supposed to have been another performance leap in the cores from Rocket Lake to Alder Lake is apparently overshadowed by another factor here – keyword: latency. 26 seconds slower is the 12900K than its predecessor, with identical RAM. Now to be fair, Alder Lake in Gear 1 now supports higher clock speeds. We could already verify up to DDR4-4200 CL16 as stable. But even with a lot of manual tuning, extreme overclockers will have a very hard time making up the nearly 8% disadvantage in compute time to Rocket Lake. So the 11900K will probably remain the first choice at least for this clientele for the time being.
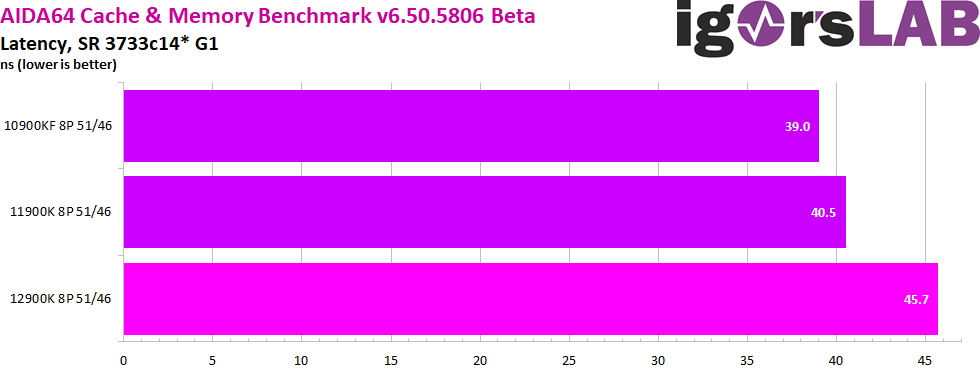
We will continue with latency, this time in the familiar AIDA64 Cache & Memory Benchmark. Alder Lake’s disadvantage in latency is once again confirmed here, although Comet Lake is actually still the nimblest here when it comes to transferring a small amount of data quickly between RAM and CPU. Since Comet Lake, RAM latency has grown steadily on Intel CPUs, due initially to the physically longer ring that had to connect Coffee Lake’s now 10 CPU cores instead of the previous 8. With Rocket Lake, gearing was introduced and now with Alder Lake, a second memory controller and 8 more small cores were added, all of which also want to talk on the ring. The consequence is also with deactivated E-Cores a higher overhead and thus slower latencies with the RAM access.
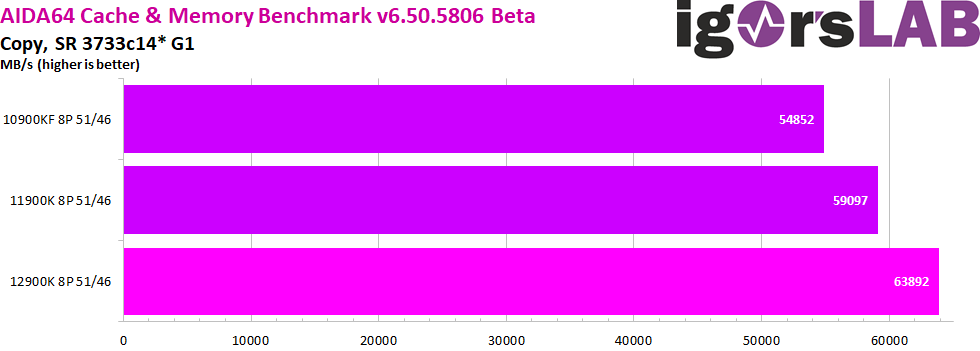
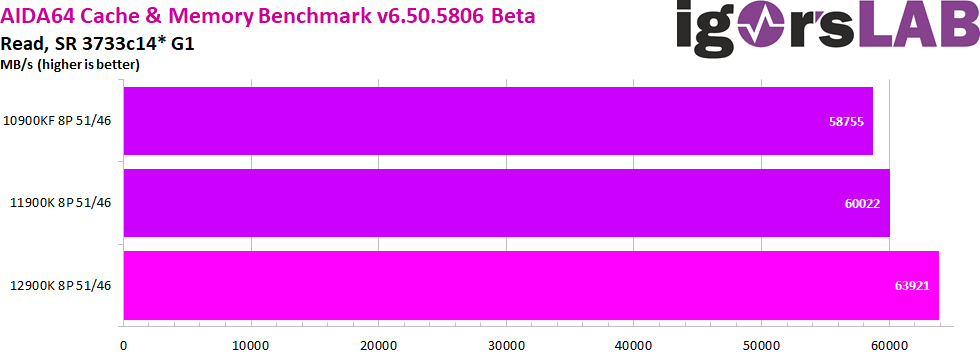
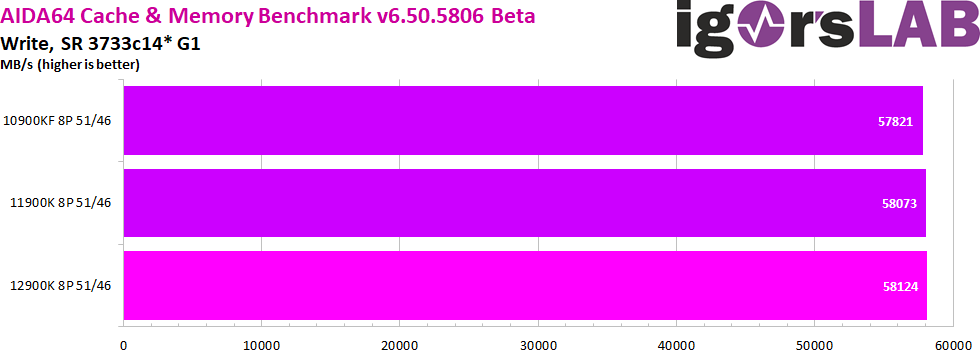
I have put the data throughput testes together in a gallery so you can switch between them yourself. Read and Copy are where the biggest differences between CPU generations are noticeable, while Write is where they are all effectively on par. MSI, in their explanation of the now two IMCs in Alder Lake, had cited this very AIDA64 copy test as an example of the resulting performance increase. So far we can also confirm this. However, it should also be mentioned that these data rates are also dependent on the core performance of the CPU and since Alder Lake also advertises progress here, we can’t say exactly where the performance increase in the results really comes from.
Linpack Xtreme and Geekbench 3
Now there is another benchmark newcomer, the Linpack Xtreme in version 1.1.5. This benchmark uses the Intel Math Kernel Library and thus also AVX2 and AVX512 for the calculation of linear algebra and thus provides an extremely high load on the CPU and the RAM. Besides a stress test, this benchmark also offers a performance metric in the form of flops, i.e. calculations per second. The performance also increases with the size of the memory used, since this also increases the complexity of the equations in the form of the “problem size”. Here we have chosen the 10 G preset with a problem size of 35000 to highlight the differences between the various CPU configurations as much as possible.
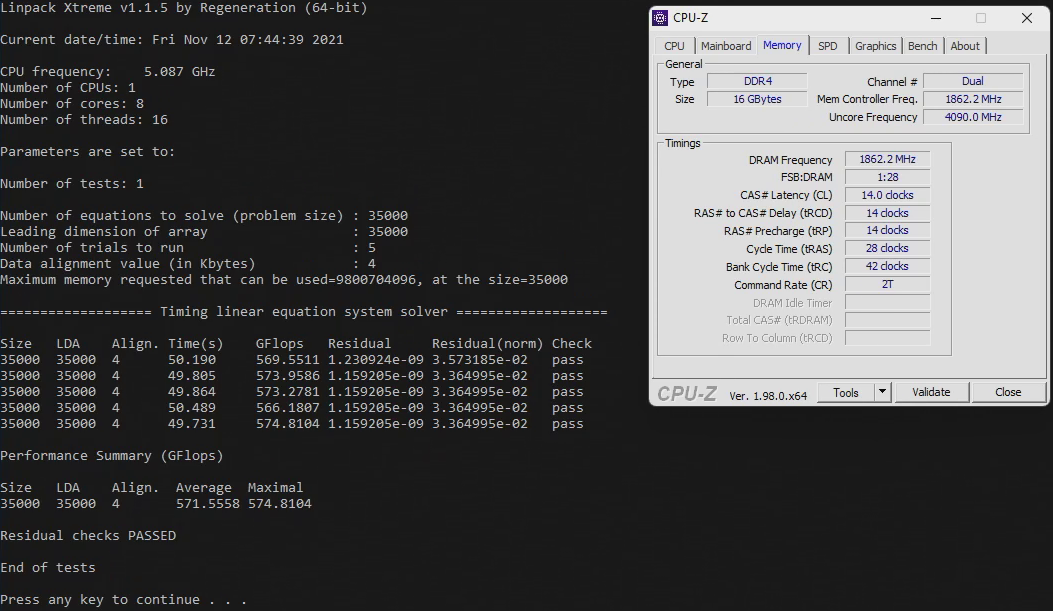
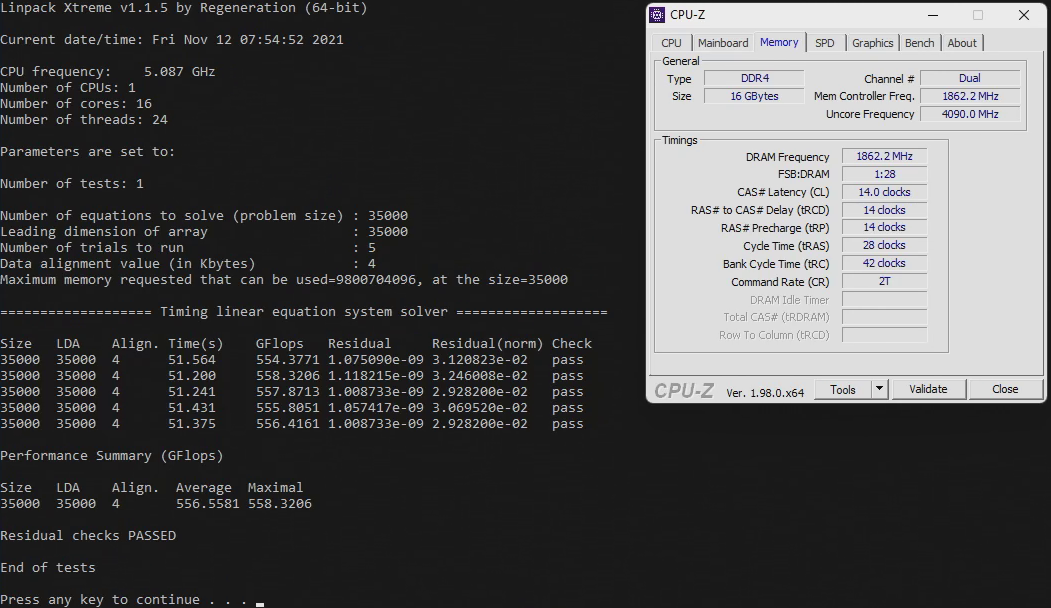
By the way, here it is important whether the AVX512 instruction set is activated on the new Alder Lake CPUs or not. Since this is only supported by the P cores, this requires the E cores to be disabled. We determined the results once with and once without AVX512, but always with disabled e-cores. Because if the e-cores are enabled as they are ex-factory, the clock of the cache has to be lowered on the one hand and on the other hand the e-cores actually cost performance here. The e-cores really just want to help, but effectively only get in the way of the P-cores when talking to the RAM. The result is about 15 GFlops less with, instead of without E-cores at the same P-core and cache clock. Congestion on Alder Lake Ring despite speed limit and “thread director” traffic control system.
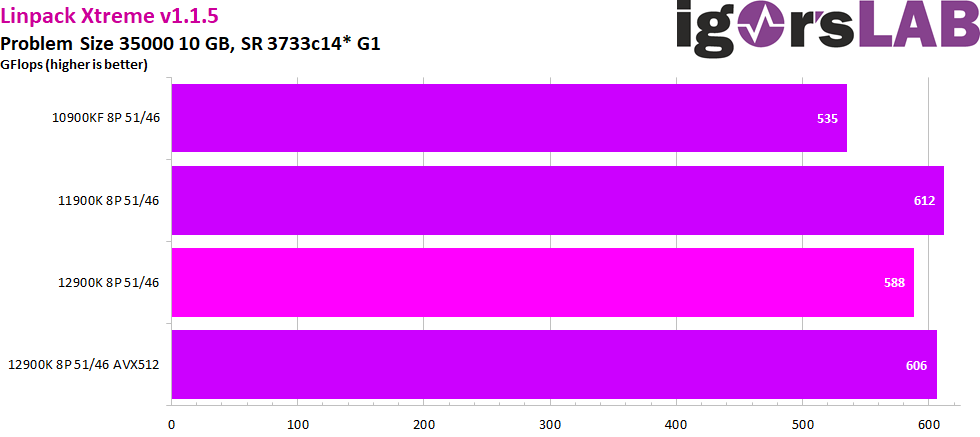
It’s also interesting to note here that even with AVX512, Alder Lake’s Golden Cove P cores don’t quite match the performance level of Rocket Lake with its Cypress Cove cores. But since the clock is effectively the same and there should be no other disadvantage for the 12900K, the only explanation is again the higher RAM latency. Intel’s new compute monsters also want to be fed in time, otherwise the brilliant performances will fail to materialize. Of course, in the real world, the higher possible RAM clock speeds with Alder Lake come in handy here, but whether DDR5’s increase in throughput will ultimately be able to make up for the deficit in latency will have to be seen another time. By the way, this was also the only benchmark where AVX512 makes a difference. In all other tests, the results were identical with and without the active instruction set.
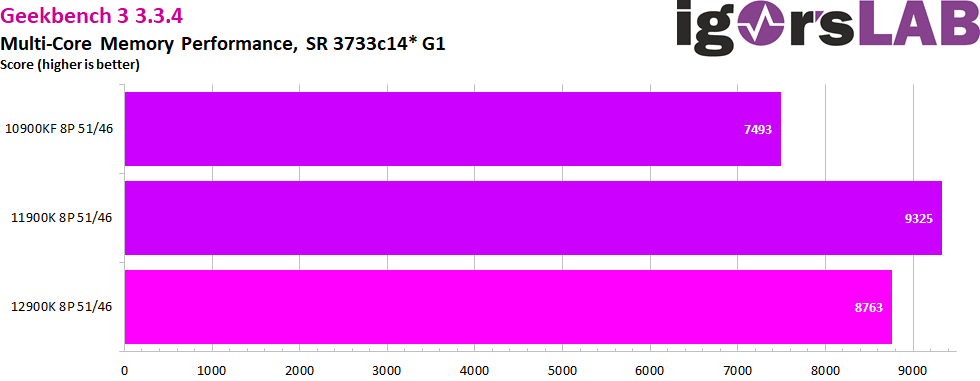
Finally, as with previous RAM tests, there is the Geekbench 3 multi-core memory performance score. Again, this shows a big jump forward from Comet to Rocket Lake and a step back from Rocket to Alder Lake. Again as a reminder, all primary, secondary and tertiary timings of RAM are identical between configurations. Only the respective CPU and its internal structure are decisive for the differences in the measured performance. Here, too, it remains to be seen whether and when the 12th generation with DDR5 will be able to make up for its supposed deficit.




















22 Antworten
Kommentar
Lade neue Kommentare
Neuling
Urgestein
Veteran
Veteran
Urgestein
Urgestein
Veteran
Urgestein
Veteran
Mitglied
Mitglied
Urgestein
Mitglied
Urgestein
Mitglied
Urgestein
1
Veteran
Urgestein
Alle Kommentare lesen unter igor´sLAB Community →